 SQL数据库开发
SQL数据库开发




初学计算机时,我经常琢磨的一个问题是:一个进程到底能吃多大内存,能把系统内存吃完?
学了数据库后,我又开始问自己类似的问题,一条 SQL 能把数据库内存全部吃完?
假设数据库系统内存 有128GB,全盘扫描一遍 200GB的表,是不是就把数据库内存撑爆了,别人的 SQL 就不能运行了?
一开始,这个问题我始终没找到答案。
经过零零散散学了些数据库系统知识,最终把这些零碎的知识拼凑起来,完整呈现一条SQL请求发给数据库,数据库到底怎么层层运转,最终把数据吐给最初的请求(客户端)后,我才不迷惑了!
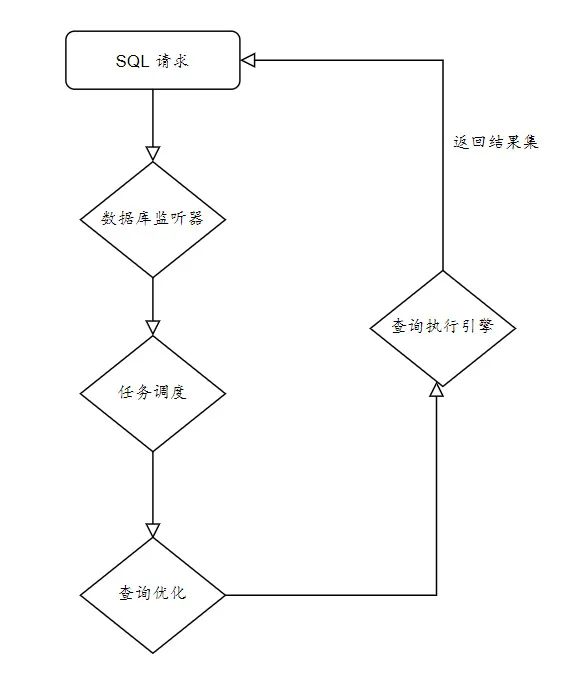
这是一条粗的数据流转链路,实际上,单看这条链路,总以为(结果集)数据是一下撑到内存里,接着由内存发到请求客户端。实际上,并不总是这样。
下面用SQL Server 的导出数据做演示。虚拟机服务器总共有8G内存,从数据库导出一张2GB的表,监测服务器内存的使用量。
1- 用 SQL Server 自带的“导出”功能,将一张2GB的表,导出到一个文本文件。为了不影响虚拟机中内存的监控,这个导出的操作, 在本机(架设虚拟机的本地机器)执行。
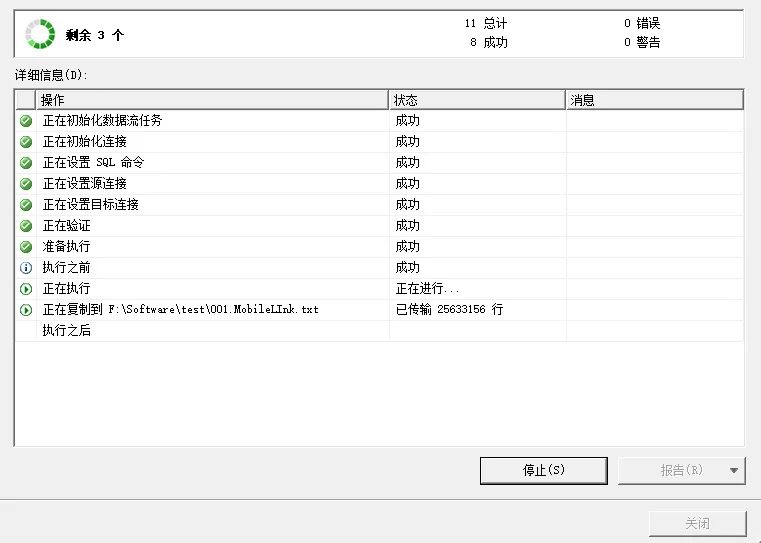
2 - 在服务器上,打开系统监控窗口,监控每秒钟的服务器内存使用量:
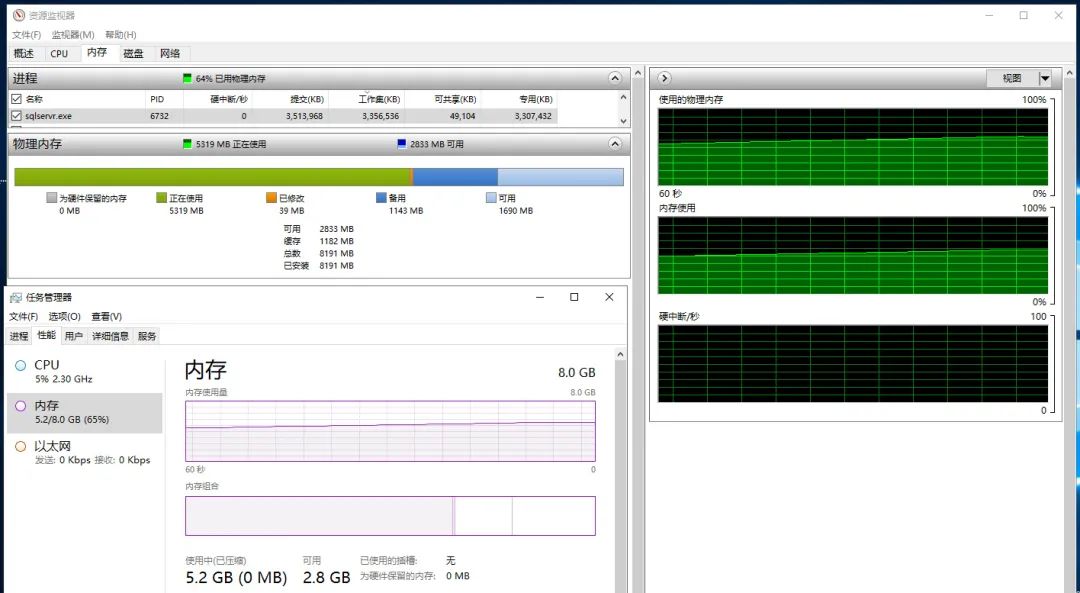
在开始测试之前,设置数据库的最大可用内存为 2GB. 否则系统容易出现OOM(Out Of Memory)的错误。
在SQLServer中,设置系统可用最大的内存,可以用以下命令:
execute sp_configure 'max server memory' ,2048
reconfigure with override
以上把 SQL Server 服务器最大可用内存设置为 2048MB,即2GB.
设置完后,当启动 2 个抽取数据的任务后,SQL Server 占用系统的内存比率,变得恒定。
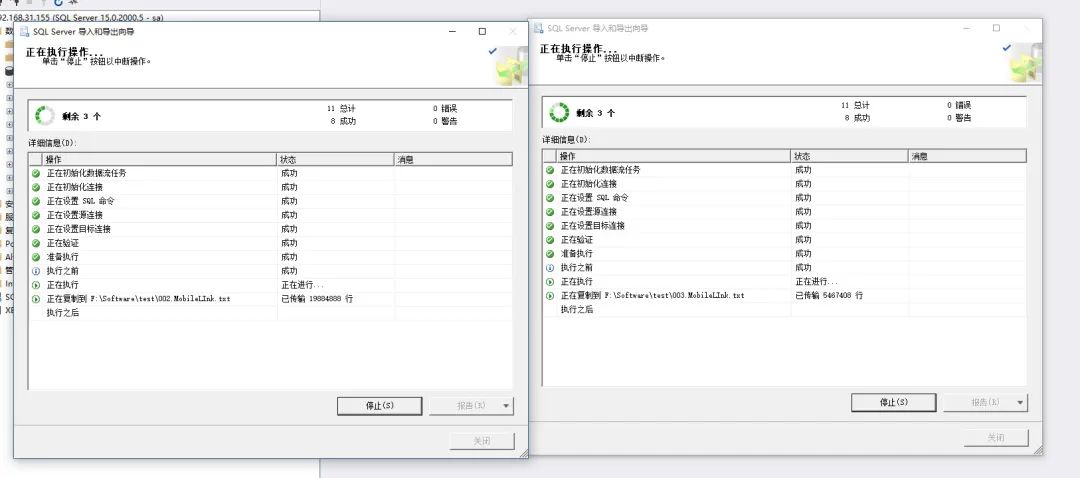
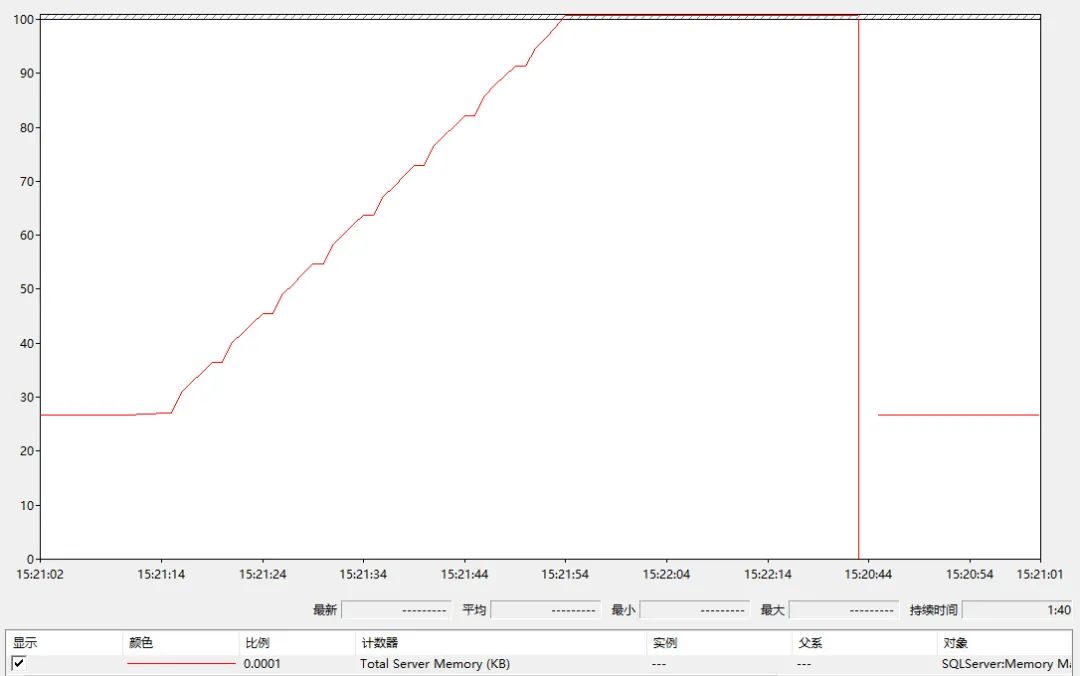

那么如果不设置这个值,会有什么影响?
来做一次实验,把最大可用内存扩大10倍:
execute sp_configure 'max server memory' ,20480
reconfigure with override
再启动 2个抽取数据的任务, 可得系统内存的比率图:
如果内存全部耗完,整个操作系统变得不稳定,SQL Server 的稳定性即即将崩溃。
回到主问题,一条 SQL 能占多大内存?
select
sess.host_name,
sess.program_name,
sess.client_interface_name,
sess.login_name,
sess.status,
sess.cpu_time,
sess.memory_usage,
sess.total_scheduled_time,
sess.total_elapsed_time,
sess.reads,
sess.writes,
sess.text_size,
sess.row_count,
sess.page_server_reads ,
sql_text.text as sql_text
from
sys.dm_exec_sessions sess
inner join sys.dm_exec_connections sql_con
on sql_con.session_id = sess.session_id
cross apply (
select
text
from
sys.dm_exec_sql_text(sql_con.most_recent_sql_handle) t) sql_text
where sess.host_name = 'DESKTOP-15RCMQD' and client_interface_name='OLEDB'

着重看这个数字:sys.dm_exec_session.memory_usage.
特别的是,4 看上去直观,但意义非凡。在 SQL Server 中 memory_usage 以page为计量单位。
在sql server中默认的一个 page 能存 8K数据, memory_usage 等于4,意味着总共使用了 32KB的数据。
看到这,有疑惑是这样的。导出 5000 万条数据,共 2.2GB 数据,只用了32KB内存?
事实上,这里可以用码头跑船来形容。
在魔都(上海)的朋友,可能去码头玩过。一艘艘跑船,打通了国际航运。普通货船吨位在1万吨,如果要把马来西亚10万吨的香蕉运到上海,需要10个来回。
数据库在导数据时,也一样。
比如 5000万的数据,一个批次只能运输 10000 条,那总共就该分成 5000个批次来回导。
但正如跑船业务,我的船载重大,别的船1万吨,我的船吃重10万吨,别人跑10次,我跑1次。
所以数据库在导入导出数据时,也可以据量派船。数据量大,就把数据包缓存加大;反之,就用恒定量的数据包。但修改数据包缓存属性会造成更多麻烦,除非能掌控全局影响,轻易不修改。
在进行导出操作时,查询系统字典表,不难发现,大数据量导出的这条链接,一直处于活动状态,显示等待客户端处理, 等待类型为 ASYNC_NETWORK_IO
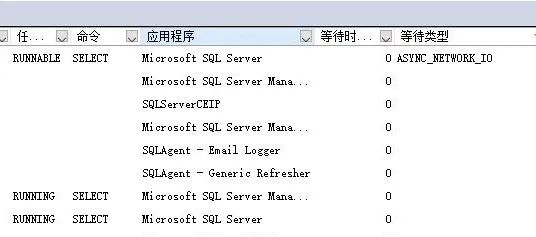
这里又引出一个问题,假设这个链接一直处于活动状态,本该共享的数据库链接就会一直被占用,导致其他用户不能操作数据库,也就是,降低了并发量。
这,是数据库链接池的范畴。
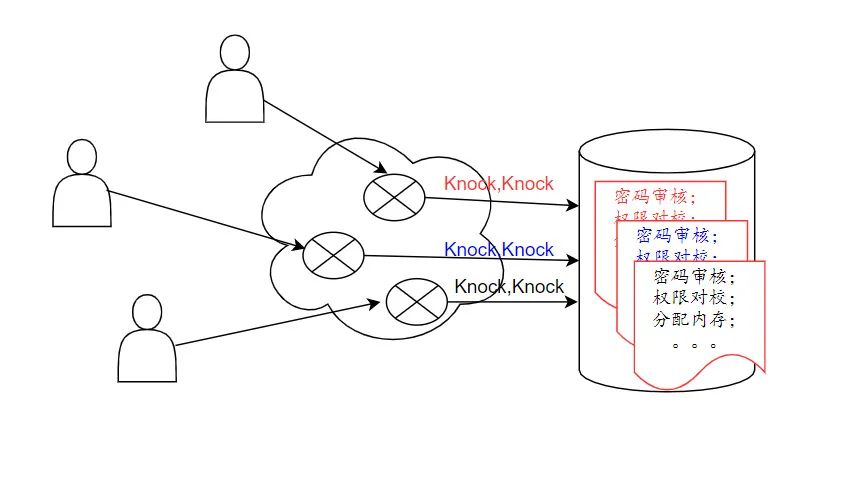
数据库库链接池的建立,旨在提高数据库的访问效率。建立一条数据库链接,最大的代价是耗时,比如审核权限,分配链接内存,加入请求栈等。
每次与数据库的交互,多等1秒,对用户体验就十分不友好。解决方法,是系统在预加载的时候,多建立几个链接,等到用时,把已经建立好的链接拿过来就用,这样就可省去建链接的时间。
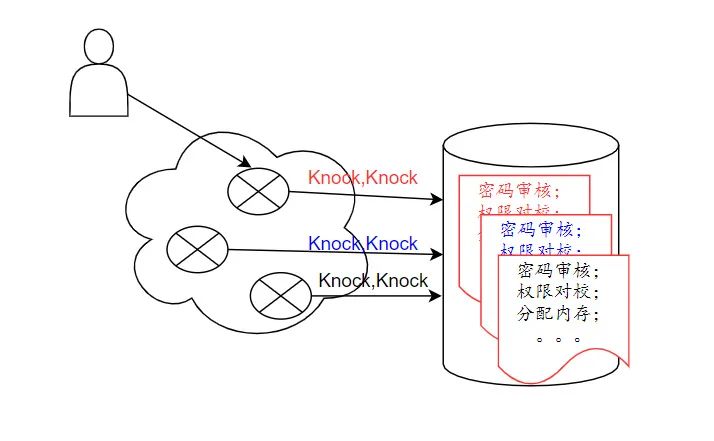
既然说到可以预先建立几个数据库链接备用,那么是不是建的越多越好,比如100万个?真的不是
设置的越大,反而还有风险。100万个数据库链接同时跑起来,对CPU的时间分片也是压力,CPU的数量是恒定的,比如8核。同时处理8个任务是最好的利用,一旦同时处理80个任务,CPU的分时分片就不可避免,每个任务就会有等待。这样CPU频繁切换任务,会导致任务一个都处理不完。
就好比,本来你一天看一本书,会沉浸在意识流中,效率很高,神情也很饱满,一旦你开始一天同时读三本书,且都想读完时,就变得非常焦虑。事实上,临睡前,你可能 一本都读不完。
所以,数据库连接池针对长短链接,一定要分级控制。该长的链接,就不能让它频繁切换。该短的链接,就不能让它长期占着,降低并发
最后给大家分享我写的SQL两件套:《SQL基础知识第二版》和《SQL高级知识第二版》的PDF电子版。里面有各个语法的解释、大量的实例讲解和批注等等,非常通俗易懂,方便大家跟着一起来实操。 有需要的可以下载学习,只需要在下面的公众号「数据前线」(非本号),后台回复关键字:SQL,就行 数据前线
后台回复关键字:1024,获取一份精心整理的技术干货 后台回复关键字:进群,带你进入高手如云的交流群。 推荐阅读




