
深入机器学习的梯度优化
简介
机器学习在选定模型、目标函数之后,核心便是如何优化(目标)损失函数。而常见的优化算法中,有梯度下降、遗传算法、模拟退火等算法,其中用梯度类的优化算法通常效率更高,而使用也更为广泛。接下来,我们从梯度下降(Gradient descent)、梯度提升(Gradient Boosting)算法中了解下“梯度”优化背后的原理。
一、梯度
我们先引出梯度的定义:
梯度是一个矢量,其方向上的方向导数最大,其大小正好是此最大方向导数
简单对于二维的情况,梯度也就是曲线上某点的切线斜率,数值就是该曲线函数的导数,如y=x^2^ ,求导dy/dx=2x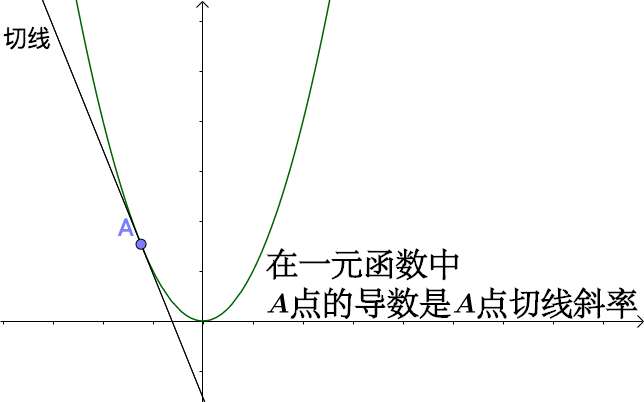 扩展到3维(多维),各点方向导数是无限多(一个平面),梯度也就是方向导数最大的方向,数值即对多元函数各参数求偏导数,如y=x^2^ + 3z^2^ ,求x偏导dy/dx=2x,求z偏导dy/dz=6z。
扩展到3维(多维),各点方向导数是无限多(一个平面),梯度也就是方向导数最大的方向,数值即对多元函数各参数求偏导数,如y=x^2^ + 3z^2^ ,求x偏导dy/dx=2x,求z偏导dy/dz=6z。
换句话说,沿着函数(曲线)的任意各点位置取梯度相反的方向,如y=x^2^ + 3z^2^ 的负梯度-(2x, 6z),也就是多元函数下降最快的地方,越容易找到极值。这也就是梯度下降算法的基本思想。
二、梯度下降算法
2.1 梯度下降的基本原理
梯度类的优化算法,最为常用的就是随机梯度下降,以及一些的升级版的梯度优化如“Adam”、“RMSP”等等。
如下介绍梯度下降算法的基本原理:
首先可以将损失函数J(w)比喻成一座山,我们的目标是到达这座山的山脚(即求解出最优模型参数w使得损失函数为最小值)
这时,梯度下降算法可以直观理解成一个下山的方法。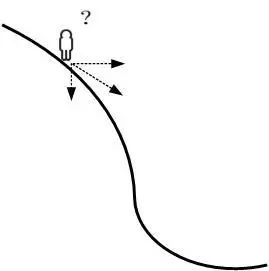
下山要做的无非就是“往下坡的方向走,走一步算一步”,而在损失函数这座山上,每一位置的下坡的方向也就是它的负梯度方向(直白点,也就是山各点位置的斜向下的方向)。每往下走到一个位置的时候,代入当前样本的特征数据求解当前位置的梯度,继续沿着最陡峭最易下山的位置再走一步。这样一步步地走下去,一直走到山脚(或者山沟沟)。
当然这样走下去,有可能我们不是走到山脚(全局最优,Global cost minimun),而是到了某一个的小山谷(局部最优,Local cost minimun),这也后面梯度下降算法的可进一步调优的地方。对应的算法步骤,直接截我之前的图:
与梯度下降一起出现的还有个梯度上升,两者原理一致,主要是术语的差异。简单来说,对梯度下降目标函数取负数,求解的是局部最大值,相应需要就是梯度提升法。
2.2 梯度下降的数学原理——泰勒展开
本节会通过泰勒展开定理,"推导"得出梯度下降
首先引出泰勒展开原理,它是种计算函数某点的近似值的方法,通过多个多项式拟合某一函数f(x)。泰勒多项式展开的项数越多,拟合的越好
1、回到我们的损失函数J,做个一阶的泰勒展开近似:(其中θ-θ0越小越近似)

2 其中θ−θo是微小矢量,做一下变换,θ-θ0以λ*d替代(λ为向量长度,d为单位向量),可得:

3、计算后式的向量乘积,可得:(theta为梯度与d向量的夹角)
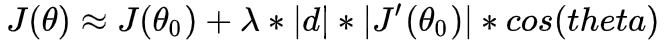
4、上式中,我们希望J(θ) 越小越好,而J(θo)为常量,所以我们希望后项越小越好,当cos(180)=-1可以取到最小值,意味着梯度与d单位向量的夹角为相反的,也就是需要d为负梯度方向:
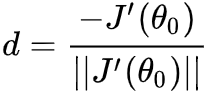
5、进一步的,将d代入式子:θ-θo = λ*d,就可以得到梯度下降公式的雏形(其中λ及1/||J'||为常数可以改写为常用的学习率α),优化后的θ也就是:
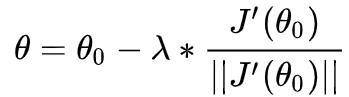
三、梯度提升算法
说到梯度提升(Gradient Boosting),要注意的是和上文谈到的梯度上升不是一个概念。
梯度提升是一种加法模型思想(Fm = Fm-1 + hm, 同上泰勒定理,hm应为负梯度),不像梯度下降直接利用负梯度更新模型参数,梯度提升是通过各弱学习器去学习拟合负梯度的,在进一步累加弱学习器,来实现损失函数J的负梯度方向优化。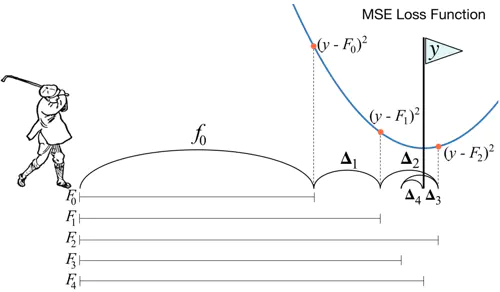
梯度提升算法很像是一个“打高尔夫,不断补杆”的过程,基本思路是弱学习器一个接着学习上一个学习器的残差或负梯度(没学习好的内容),最终得到m个弱学习器h0..hm一起决策。(注:对于平方损失函数, 其负梯度刚好等于残差。我们通过直接拟合负梯度可以扩展到更为复杂的损失函数。)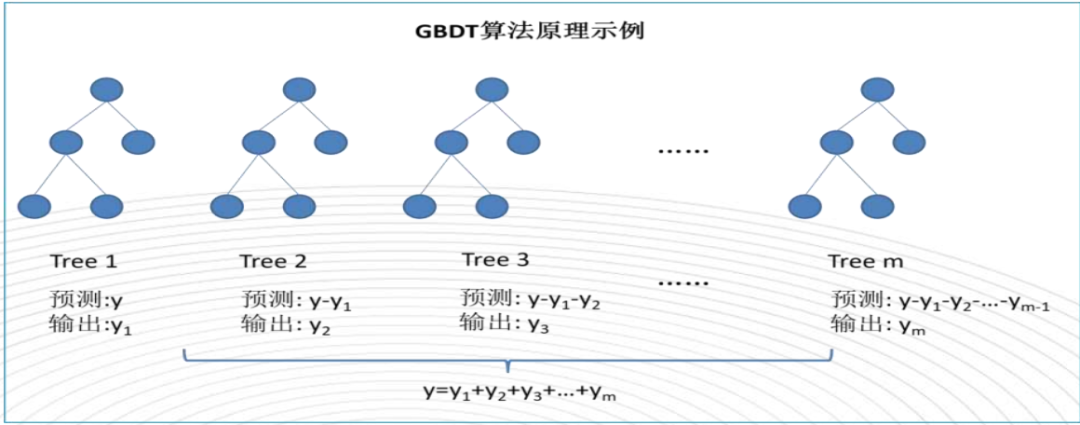
举个简单例子,假如我们的目标值是【100】,当第一个弱学习器h0学习目标值100,实际输出y^只有【60】,和实际y还是有偏差的,残差值y^ - y,第二个学习器h1继续学习拟合之前的残差(或者负梯度),学习剩下的【100-60】,并实际输出【50】...依次学习到第h2个弱学习器拟合之前的残差【100-60-50】,这时比较准确地输出【-10】,达到较好的拟合结果,算法结束。整个模型的表示就是Fm = h0 + h1 + h2 = 60 + 50 - 10 => 100。如下图具体算法:
后记
在优化领域,梯度优化方法无疑是简单又极有效率的,但不可避免的是它通常依赖着有监督标签,且得到的是近似最优解。不可否认,在优化的道路上,我们还有很长的一段路要走。
- END -参考文献:
https://zhuanlan.zhihu.com/p/45122093
https://zhuanlan.zhihu.com/p/82757193
https://www.zhihu.com/question/63560633
- 推荐阅读-
深度学习系列机器学习系列
文末,粉丝福利来了!!关注【算法进阶】👇
后台回复【课程】,即可免费领取Python|机器学习|AI 精品课程大全
机器学习算法交流群,邀您加入!!!
入群:提问求助、认识行业内同学、交流进步、共享资源...
扫描👇下方二维码,备注“加群”
