 3D视觉工坊
3D视觉工坊




来源:量子位
2张废片啪地一合!
错过的精彩瞬间立刻重现,还能从2D升到3D效果。
看,小男孩可爱的笑容马上跃然浮现:

吹灭生日蛋糕蜡烛的瞬间也被还原了出来:

咧嘴笑起来的过程看着也太治愈了吧~

咱就是说,这回相机里熊孩子/毛孩子的废片终于有救了!
而且完全看不出是后期合成的效果,仿佛是原生拍摄的一般。
这就是谷歌、康奈尔大学、华盛顿大学最近联合推出的成果,能只用2张相近的照片还原出3D瞬间,目前已被CVPR 2022收录。
论文作者一作、二作均为华人,一作小姐姐本科毕业于浙江大学。
用2张照片正反向预测中间场景
这种方法适用于两张非常相似的照片,比如连拍时产生的一系列照片。
方法的关键在于将2张图片转换为一对基于特征的分层深度图像 (LDI),并通过场景流进行增强。
整个过程可以把两张照片分别看做是“起点”和“终点”,然后在这二者之间逐步预测出每一刻的变化。
具体来看,过程如下:
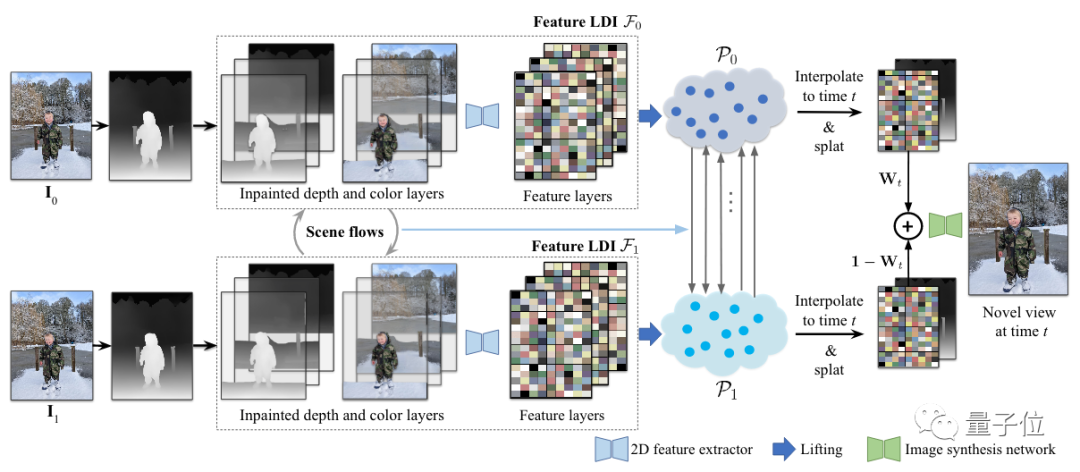
首先,将两张照片用单应矩阵(homegraphy)对齐,分别预测两张照片的稠密深度图。
然后将每个RGBD图像转换为彩色的LDI,通过深度感知修复背景中被遮挡的部分。
其中,RGB图像即为普通RGB图像+深度图像。

之后用二维特征提取器修复LDI的每个颜色层,以获取特征层,从而生成两份特征图层。
下一步就到了模拟场景运动部分。
通过预测两个输入图像之间的深度和光流,就能计算出LDI中每个像素的场景流。
而如果想要两张图之间渲染出一个新的视图、并提升到3D,在此需要将两组带特征值的LDI提升到一对3D点云中,还要沿着场景流双向移动到中间的时间点。
然后再将三维的特征点投影展开,形成正向、反向的二维特征图及对应深度图。
最后将这些映射与时间线中对应时间点的权重线性混合,将结果传给图像合成网络,就能得到最后的效果了。
实验结果
从数据方面来看,该方法在所有误差指标上,均高于基线水平。
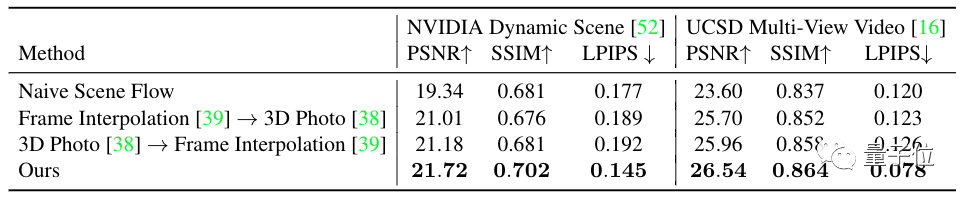
在UCSD数据集上,这一方法可以保留画面中的更多细节,如(d)所示。

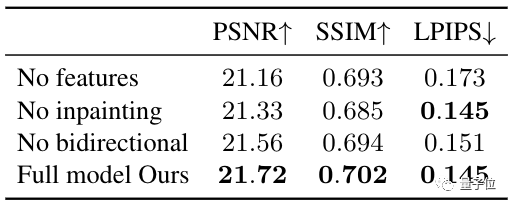
在NVIDIA数据集上进行消融实验表明,该方法在提高渲染质量上表现也很nice。
不过也存在一些问题:当两张图像之间的改变比较大时,会出现物体错位的现象。
比如下图中酒瓶的瓶嘴移动了,不该发生变化的酒杯也摇晃了起来。

还有照片如果没有拍全的地方,在合成的时候难免会出现“截肢”的情况,比如下图中喂考拉的手。

团队介绍

该研究的一作为Qianqian Wang,现在在康奈尔大学读博四。
她本科毕业于浙江大学,师从周晓巍。
研究兴趣为计算机视觉、计算机图形学和机器学习。

二作是Zhengqi Li,博士毕业于康纳尔大学,本科毕业于明尼苏达大学,目前在Google Research。
曾获提名CVPR 2019最佳论文,谷歌2020博士奖研金,2020年Adobe Research奖学金,入围百度2021年AI华人新星百强榜单。

参与此项研究的还有华盛顿大学教授Brian Curless。
他还提出过另一种方法能够实现类似效果,同样只用到了2张照片,通过新型帧插值模型生成连贯的视频。

论文地址:
https://3d-moments.github.io/
3D视觉工坊精品课程官网:3dcver.com
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款 
圈里有高质量教程资料、答疑解惑、助你高效解决问题 觉得有用,麻烦给个赞和在看~

