
【Python】分享几个令人相见恨晚的Pandas函数
Pandas函数,或许不那么为人所知,但是相信会给大家在数据分析与挖掘的过程中起到不小的帮助。创建数据集
首先我们先来创建一个数据集,代码如下
import numpy as np
import pandas as pd
df = pd.DataFrame({
"date": pd.date_range(start="2021-11-20", periods=100, freq="D"),
"class": ["A","B","C","D"] * 25,
"amount": np.random.randint(10, 100, size=100)
})
df.head()
output
To_period
to_period()方法来实现了,代码如下df["year"] = df["date"].dt.to_period("Y")
df["month"] = df["date"].dt.to_period("M")
df["day"] = df["date"].dt.to_period("D")
df["quarter"] = df["date"].dt.to_period("Q")
df.head()
output
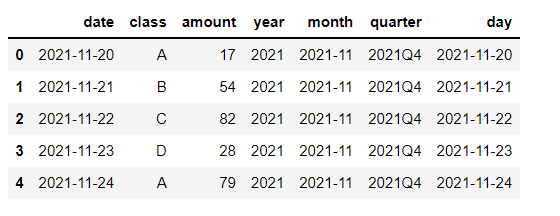
在此基础之上,我们可以进一步对数据进行分析,例如
df["month"].value_counts()
output
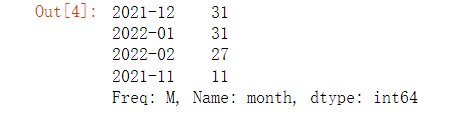
我们想要筛选出“2021-12”该时段的数据,代码如下
df[df['month'] == "2021-12"].head()
output
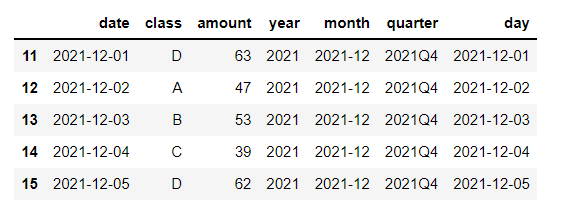
生成假数据
Python中的faker模块或者通过一些深度学习的模型来生成假数据pandas模块中也有一些相关的方法来帮助我们解决数据量不够的问题,代码如下pd.util.testing.makeDataFrame()
output
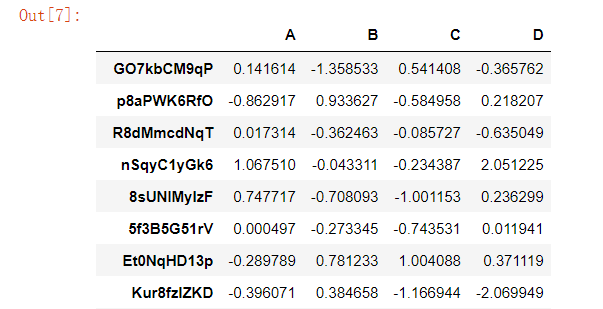
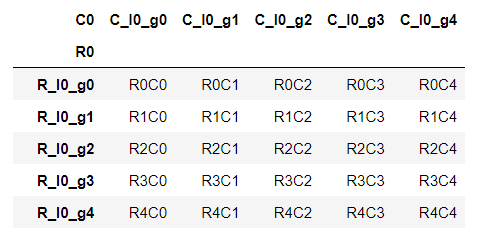
默认生成的假数据是30行4列的,当然我们也可以指定生成数据的行数和列数,代码如下
pd.util.testing.makeCustomDataframe(nrows=1000, ncols=5)
output
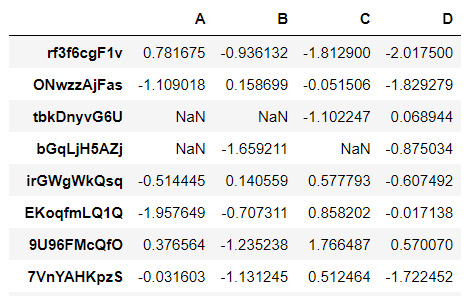
要是我们希望创建的数据集当中存在的缺失值,调用的则是makeMissingDataframe()方法
pd.util.testing.makeMissingDataframe()
output
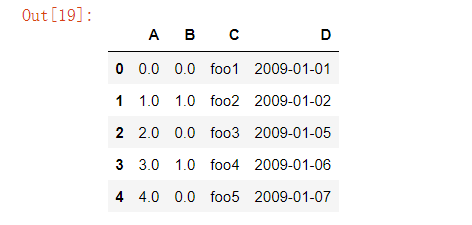
makeMixedDataFrame()方法pd.util.testing.makeMixedDataFrame()
output
将数据集导出至压缩包中
df = pd.util.testing.makeCustomDataframe(nrows=1000, ncols=5)
df.shape
output
(1000, 5)
csv格式的文件,看一下文件的大小,结果大概是占到了45KB的存储,代码如下import os
os.path.getsize("sample.csv")/1024
output
44
要是最后导出至压缩包当中呢,我们看一下文件的大小有多少?代码如下
df.to_csv('sample.csv.gz', compression='gzip')
os.path.getsize('sample.csv.gz')/1024
output
14
pandas还能够直接读取压缩包变成DataFrame数据集,代码如下df = pd.read_csv('sample.csv.gz', compression='gzip', index_col=0)
df.head()
output
一行代码让Pandas提速
pandas中的apply()方法将自定义函数或者是一些内部自带的函数应用到DataFrame每一行的数据当中,如果行数非常多的话,处理起来会非常地耗时间,这里使用的是swifter可以自动使apply()方法的运行速度达到最快,并且只需要一行代码即可,例如import swifter
df.swifter.apply(lambda x: x.max() - x.mean())
当然使用前,我们需要先前下载该模块,使用pip命令
pip install swifter
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码: