
大数据权限管理框架:Apache Sentry和Ranger
前沿
本篇简单介绍一下业界流行的大数据权限管理框架Apache Sentry和Ranger。
Apache Sentry
Sentry是由Cloudera公司内部开发而来的,初衷是为了让用户能够细粒度的控制Hadoop系统中的数据(这里主要指HDFS,Hive的数据)。所以Sentry对HDFS,Hive以及同样由Cloudera开发的Impala有着很好的支持性。
Apache Ranger
Ranger则是由于另一家公司Hortonworks所主导。它同样是做细粒度的权限控制。但相比较于Sentry而言,它能支持更丰富的组件,包括于 HDFS, Hive, HBase, Yarn, Storm, Knox, Kafka, Solr and NiFi。
这两个框架在权限管理时都有运用到基于角色的访问控制原理(role-based access control,RBAC)。换句话说,当新来一个用户时,我们赋予它的是一个身份角色,然后这个用户的执行权限操作完全由统一的角色本身所允许的一些权限。基于角色的访问控制,能够大大减轻系统对于大数据量用户的直接ACL控制。
下面就简单介绍一下两种权限授权管理框架:
Sentry
Sentry的架构模型
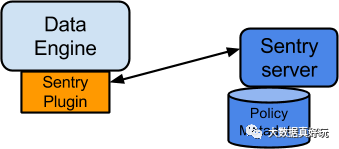
DataEngine指的是具体的数据应用程序,这里指的是HDFS,Hive和Impala。 Plugin,Plugin程序负责和Sentry Server通信,做权限策略信息的同步。同时在Plugin程序中,包含了认证引擎模块,来做权限的验证操作。 Policy metadata,这里的matadata存储权限策略数据,对应的会需要一个外部存储db。
从另一个角度层面来看Sentry的内部结构:
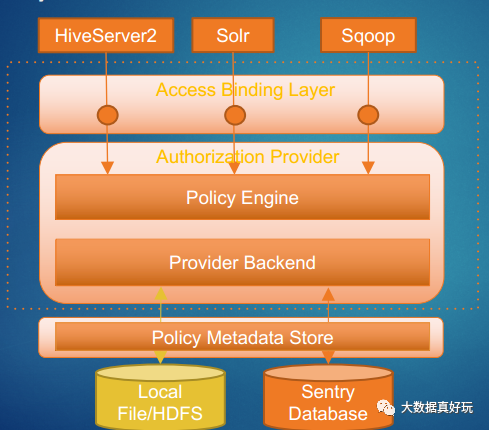
Sentry与Hive,HDFS,Impala等组件集成的较好, 结构图如下图所示:
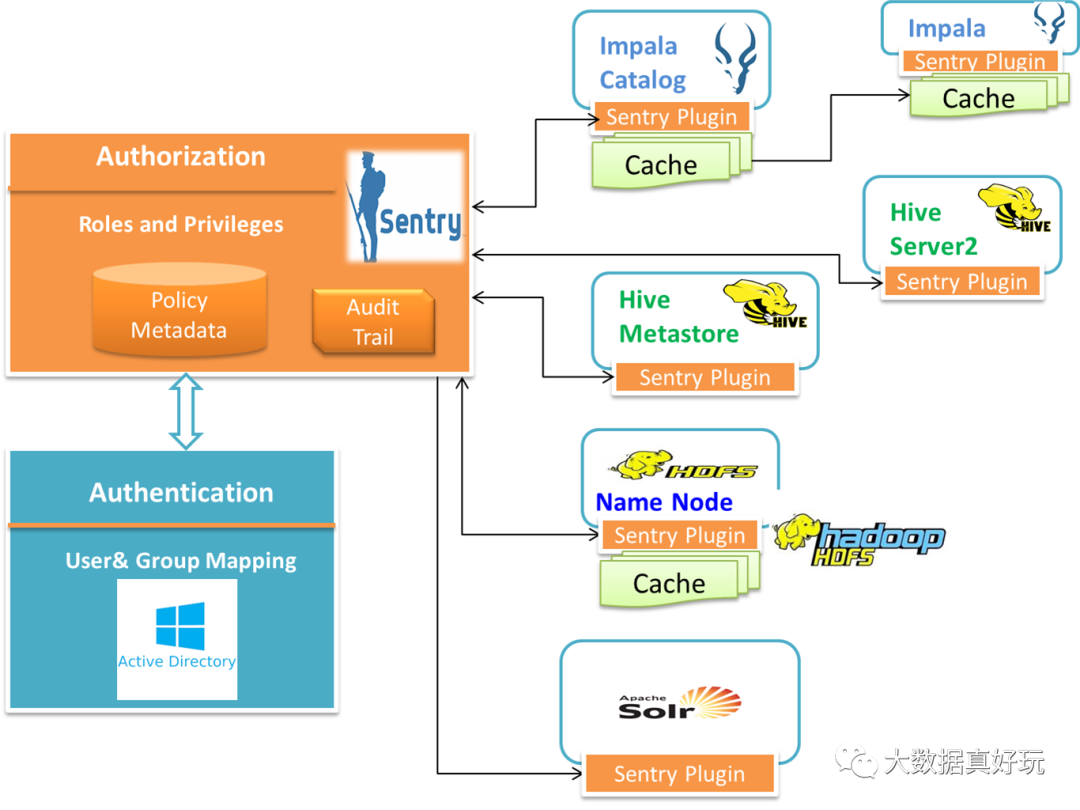
从上图中,我们注意到一个细节,在HDFS里面多了一个cache层,这个是用来干嘛的呢?其实为了保持HDFS的权限与HIve的一致,NameNode的Sentry Plugin程序会定期拉取Hive的Metadata信息以及Sentry Server上的权限信息,并cache起来。这可以说也是为了性能考虑了。
另外地在Sentry Sever中,它还有audit模块,记录了所有模块的请求访问记录。
Ranger
Ranger相比较于Sentry来说,它的功能可以说更加具有通用性。这里说的通用性在于以下两点:
上层支持的应用组件更多 对于控制的资源的类型更多
第一点,前文已经提到过,第二点这里的资源就不仅仅只有文件和目录了这种了,它还可以有表,行以及列的访问控制。这些都是体现在Ranger的策略信息里面的。
Ranger的架构模型
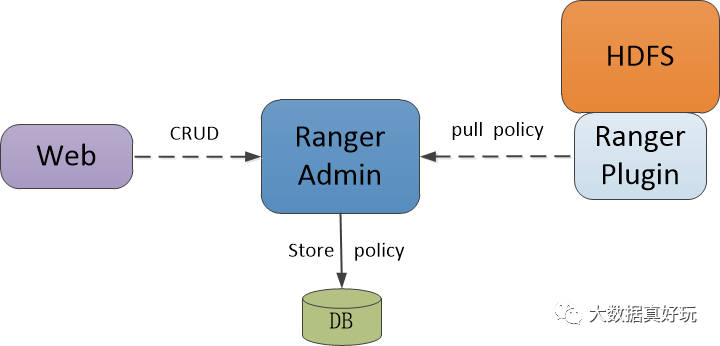
对于具体的策略控制,由用户通过admin web ui页面进行配置。
Ranger的策略配置
对于用户的ACL控制
我们先来看最简单的,对于用户的访问控制,我们可以设置用户对于选定的路径有哪些权限,策略细节如下:
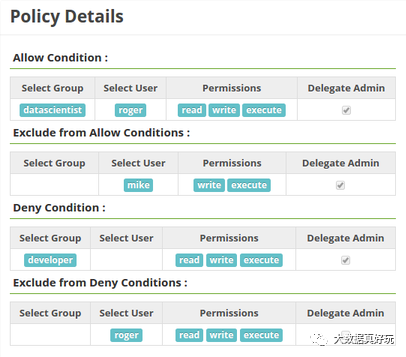
配置此策略信息后,系统会对这些用户做额外判断处理。
表的行过滤及列处理
假设我们有一以下Hive表:
Table: customer
+----+------------+-----------+--------------+---------------+----------------+
| id | name_first | name_last | addr_country | date_of_birth | phone_num |
+----+------------+-----------+--------------+---------------+----------------+
| 1 | Mackenzy | Smith | US | 1993-12-18 | 123-456-7890 |
| 2 | Sherlyn | Miller | US | 1975-03-22 | 234-567-8901 |
| 3 | Khiana | Wilson | US | 1989-08-14 | 345-678-9012 |
| 4 | Jack | Thompson | US | 1962-10-28 | 456-789-0123 |
| 5 | Audrey | Taylor | UK | 1985-01-11 | 12-3456-7890 |
| 6 | Ruford | Walker | UK | 1976-05-19 | 23-4567-8901 |
| 7 | Marta | Lloyd | UK | 1981-07-23 | 34-5678-9012 |
| 8 | Derick | Schneider | DE | 1982-04-17 | 12-345-67890 |
| 9 | Anna | Richter | DE | 1995-09-07 | 23-456-78901 |
| 10 | Raina | Graf | DE | 1999-02-06 | 34-567-89012 |
| 11 | Felix | Lee | CA | 1982-04-17 | 321-654-0987 |
| 12 | Adam | Brown | CA | 1995-09-07 | 432-765-1098 |
| 13 | Lucas | Jones | CA | 1999-02-06 | 543-876-2109 |
| 14 | Yvonne | Dupont | FR | 1982-04-17 | 01-23-45-67-89 |
| 15 | Pascal | Fournier | FR | 1995-09-07 | 23-45-67-89-01 |
| 16 | Ariel | Simon | FR | 1999-02-06 | 34-56-78-90-12 |
+----+------------+-----------+--------------+---------------+----------------+
假设此时我们执行以下查询语句,我们肯定能查到所有表数据的:
select * from cust.customer
如果此时我们加一个用户归属地的判断,每个用户只能查到它所属那个地域的数据。比如多了以下的用户关系:
+--------------+---------------+
| Group name | Users |
+--------------+---------------+
| us-employees | john,scott |
| uk-employees | mary,adam |
| de-employees | drew,alice |
+--------------+---------------+
在Ranger的页面配置效果如下图所示:
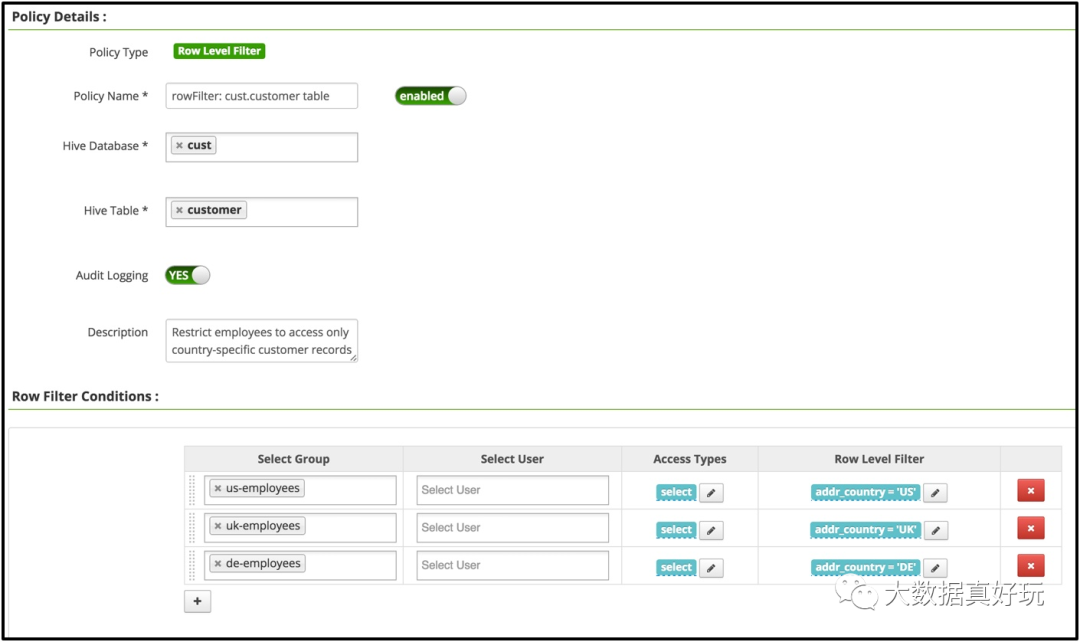
然后我们以john用户身份去查,查出的记录所属地域就只会是US上的了,不会受全部的数据了。
[john@localhost ~]$ beeline -u jdbc:hive2://localhost.localdomain:10000/cust
0: jdbc:hive2://localhost.localdomain:10000> select * from cust.customer;
+-----+-------------+------------+---------------+----------------+--------------+
| id | name_first | name_last | addr_country | date_of_birth | phone_num |
+-----+-------------+------------+---------------+----------------+--------------+
| 1 | Mackenzy | Smith | US | 1993-12-18 | 123-456-7890 |
| 2 | Sherlyn | Miller | US | 1975-03-22 | 234-567-8901 |
| 3 | Khiana | Wilson | US | 1989-08-14 | 345-678-9012 |
| 4 | Jack | Thompson | US | 1962-10-28 | 456-789-0123 |
+-----+-------------+------------+---------------+----------------+--------------+
对于列处理,Ranger支持对部分敏感字段实施遮掩处理,比如下面是对电话号码的处理:
+-----+-------------+------------+---------------+----------------+--------------+
| id | name_first | name_last | addr_country | date_of_birth | phone_num |
+-----+-------------+------------+---------------+----------------+--------------+
| 1 | Mackenzy | NULL | US | 1993-01-01 | xxx-xxx-7890 |
| 2 | Sherlyn | NULL | US | 1975-01-01 | xxx-xxx-8901 |
| 3 | Khiana | NULL | US | 1989-01-01 | xxx-xxx-9012 |
+-----+-------------+------------+---------------+----------------+--------------+
Ranger的Policy的灵活性
通过的Policy策略还有许多灵活的特性,包括它还能支持基于Tag的策略控制,有了Tag后,就无需考虑组件的差别了。另外还有condition的条件的添加控制,这些也都是由管理员用户人工控制的。
同样的,Ranger Plugin程序会拉取策略数据在本地,如果说Ranger admin server临时不可用了,也不会影响策略实际的执行认证。
总结:
两个框架非常类似,Sentry在于它对于Hive等相关组件支持集成的比较好(也和这个项目本身发展初期设计决定),而Ranger在于它更通用化的支持和更加丰富的策略控制。
参考:
[1].https://cwiki.apache.org/confluence/display/RANGER/Row-level+filtering+and+column-masking+using+Apache+Ranger+policies+in+Apache+Hive?preview=/65868896/65868900/rowFilter-usecase-1.jpg [2].https://www.linkedin.com/pulse/apache-ranger-vs-sentry-mythily-rajavelu/ [3].https://cwiki.apache.org/confluence/display/SENTRY/Sentry+Tutorial [4].https://www.cnblogs.com/qiuyuesu/p/6774520.html