 3D视觉工坊
3D视觉工坊




一、鱼眼相机成像模型
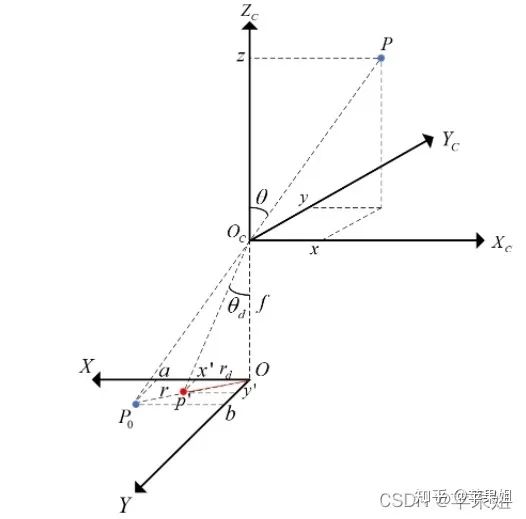
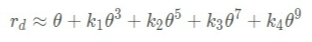
二、重投影之2D到3D投影
# Scale intrinsics to adjust image resize.
K, D = scale_intrinsic(args, intrinsic, coords)
x = np.linspace(0, args.input_width - 1, args.input_width)
y = np.linspace(0, args.input_height - 1, args.input_height)
mesh_x, mesh_y = np.meshgrid(x, y)
mesh_x, mesh_y = mesh_x.reshape(-1, 1), mesh_y.reshape(-1, 1)
x_cam = (mesh_x - K[1]) / K[0]
y_cam = (mesh_y - K[2]) / K[0]
r = np.sqrt(x_cam * x_cam + y_cam * y_cam)
theta_LUT = np.arctan2(y_cam, x_cam).astype(np.float32)
angle_LUT = np.zeros_like(r, dtype=np.float32)
for i, _r in tqdm(enumerate(r)):
a = np.roots([D[3], D[2], D[1], D[0], -_r])
a = np.real(a[a.imag == 0])
try:
a = np.min(a[a >= 0])
angle_LUT[i] = a
except ValueError: # raised if `a` is empty.
print(f"Field angle of incident ray is empty")
pass
三、重投影之3D到2D投影
x_cam, y_cam, z = [world_coords[:, i, :].unsqueeze(1) for i in range(3)]
# angle in the image plane
theta = torch.atan2(y_cam, x_cam)
# radius from angle of incidence
r = torch.sqrt(x_cam * x_cam + y_cam * y_cam)
# Calculate angle using z
a = np.pi / 2 - torch.atan2(z, r)
distortion_coeffs = distortion_coeffs.unsqueeze(1).unsqueeze(1)
r_mapping = sum([distortion_coeffs[:, :, :, i] * torch.pow(a, i + 1) for i in range(4)])
intrinsics = intrinsics.unsqueeze(1).unsqueeze(1)
x = r_mapping * torch.cos(theta) * intrinsics[:, :, :, 0] + intrinsics[:, :, :, 2]
y = r_mapping * torch.sin(theta) * intrinsics[:, :, :, 1] + intrinsics[:, :, :, 3]
四、图像重构和求损失函数
五、激光点云真值投影与模型评测
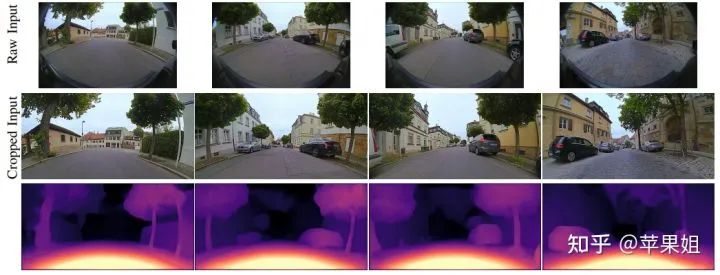
3D视觉工坊精品课程官网:3dcver.com
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款 
圈里有高质量教程资料、答疑解惑、助你高效解决问题 觉得有用,麻烦给个赞和在看~

