
性能远超ConvNeXt?浅析谷歌提出的「三合一」transformer模型MaxViT+伪代码分析

极市导读
为解决传统自注意力机制在图像大小方面缺乏的可扩展性,本文提出了一个简单的局部、全局自注意力与卷积三者混合的大一统模型,称之为MaxViT。作为视觉任务的骨干网络,MaxViT允许任意分辨率的输入,在ImageNet上其性能远超ConvNeXt、Swin Transformer等主流模型。代码将开源。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1 写在前面的话
为解决传统自注意力机制在图像大小方面缺乏的可扩展性,本文提出了一个简单的局部、全局自注意力与卷积三者混合的大一统模型,称之为MaxViT(Multi-Axis Vision Transformer)。作为视觉任务的骨干网络,MaxViT允许任意分辨率的输入,在ImageNet上其性能远超ConvNeXt、Swin Transformer等主流模型。代码将开源。

论文地址:https://arxiv.org/abs/2204.01697
2 问题引出
众所周知,Transformer具备强大的建模能力但缺乏空间归纳偏置,极易导致过拟合现象。一个有效的解决措施便是控制模型容量,在参数量减少的同时得到性能的增强,如Twins、LocalViT以及Swin Transformer等。但在灵活性与可扩展性得到提高的同时,由于这些模型普遍失去了类似于ViT的非局部性,即具有有限的模型容量,导致无法在更大的数据集上扩展(ImageNet-21K、JFT等)。
综上,研究局部与全局相结合的方法来增加模型灵活性是有必要的。然而,如何实现对不同数据量的适应,如何有效结合局部与全局计算的优势成为本文要解决的目标。
3 如何解决?
针对上述问题,本文提出以MBConv与Max-SA组成的模块作为堆叠的基本架构组件。MaxViT在每一个块内都可以实现局部与全局之间的空间交互,同时可适应不同分辨率的输入大小。其中Max-SA通过分解传统注意力计算得到窗口注意力(window attention)与网格注意力(grid attention),将传统计算方法的二次复杂度降到线性复杂度。而MBConv作为自注意力计算的补充,利用其固有的归纳偏差来提升模型的泛化能力,避免陷入过拟合。本节将配合伪代码对本文方法进行详细讲解。
预归一化相对自注意力(pre-normalized relative self-attention)
在正式介绍MaxViT之前,我们先来了解本文的基本算子——预归一化相对自注意力。这是一种在CoAtNet中被定义的方法,关于CoAtNet详情可见极市推文:https://mp.weixin.qq.com/s/Bq2SyEBAHTmy6c5Le8cr7w。这里进行简单的介绍:
相对自注意力: 给定输人尺寸 , 执行如下公式。首先创建一个可训练 参数 , 其尺寸为 。则对于空间位置 和 , 其对应相对偏 差为 , 因此总索引次数为 。需要注意的是, 对于更大的分辨率 输人 , 我们只需使用双线性揷值方法将 调整到所需的大小即可。
预归一化: 一个简单的归一化方法被使用在模块输入之后,对于MBConv(CoAtNet中定义的方法),使用批归一化;对于自注意力计算,则使用层归一化。
而在本文中,则使用具有相同头部维度的多头自注意力来实现,可用公式表示为:
其中B代表学习的静态位置感知矩阵,即上文介绍的可训练参数P。
多轴注意力(Multi-axis Attention)
为避免直接应用全局自注意力导致的二次复杂度,本文通过分解空间轴得到局部(block attention)与全局(grid attention)两种稀疏形式,具体过程如下:
block attention: 对于输入特征图 , 转化为形状张量 以表示划分为不重叠的穾口, 其中每个穾口的大小为 , 最 后在每一个窗口中执行自注意力计算。
grid attention: 不同于传统使用固定窗口大小来划分特征图的操作,grid attention 使用固定的 均匀网格将输人张量网格化为, 此时 得到自适应大小的窗口 , 最后在 上使用自注意力计算。需要注意, 通过使用相同的窗口 和网格 , 可以有效平衡局部和全局之间的计算 (且仅具有线性复杂度)。
图 1 MaxViT Block
如图1,将上述两种计算方式按顺序堆叠,即可轻松获得局部与全局信息交互,其中FFN代表由两个MLP组成的标准线性层。
需要注意的是,MBConv被添加到每一次堆叠的头部。在前文有提及,引入MBConv的动机是为了利用卷积固有的归纳偏置,在一定程度上提升模型的泛化能力与可训练性。但MBConv具备着另一大优势:相比于ViT中的显式位置编码,在Multi-axis Attention则使用MBConv来代替,这是因为深度卷积可被视为条件位置编码(CPE)。
MaxViT Block的伪代码如下所示:

对于输入input,首先经过MBConv进行卷积计算,接着使用einops进行block attention计算前的张量形状改变,即,最后通过unblock进行形状还原。在grid attention计算中,增加了swapaxes函数来对轴进行更改,最终通过unblock得到模块的输出。
MaxViT整体架构
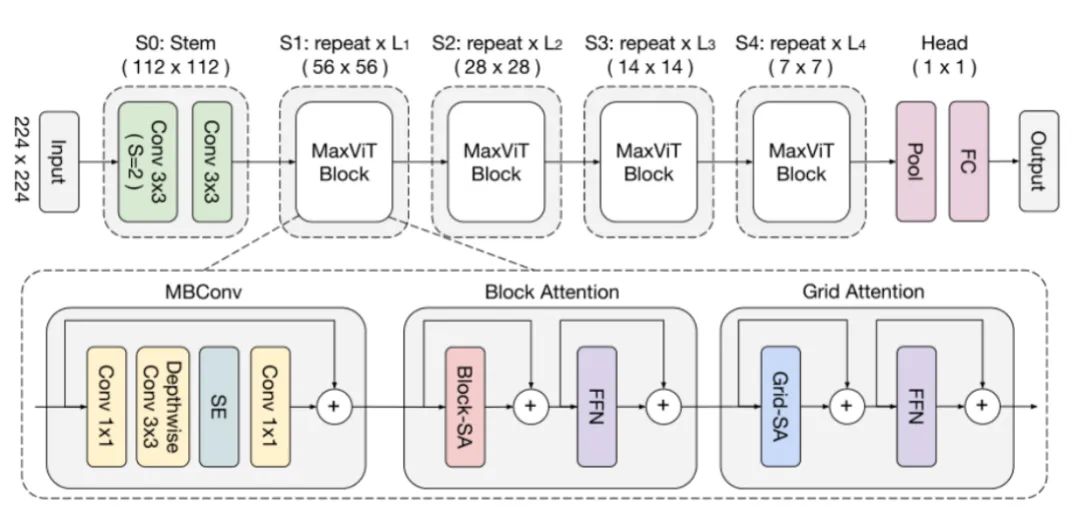 图2
图2如图2所示,MaxViT的详细结构被展示。在图中可以很清楚的看的MBConv的构成:需要注意的是,为了获得更丰富的特征表示,首先使用逐点卷积进行通道升维,在升维后的投影空间中进行Depth-wise卷积,紧随其后的SE用于增强重要通道的表征,最后再次使用逐点卷积恢复维度。可用如下公式表示:

在S0阶段,步长为2的卷积被用来执行下采样操作,之后便是若干个堆叠的MaxViT(每个阶段分辨率下降一半,通道数增加一倍),在网络的尾部,不同于传统ViT执行的分类头,而是使用池化后接全连接层来得到最终的输出。
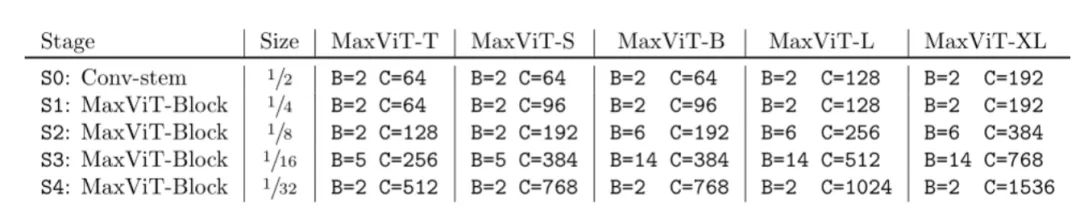
本文设计了五种不同容量的MaxViT版本,如下表所示:
4 思考
Multi-Axis attention与Axial attention
本文所提出的方法不同于 Axial attention。如图 3 所示, 在 Axial attention 中 首先使用 column-wise attention,然后使用 row-wise attention 来计算全局 注意力, 相当于 的计算复杂度。然而 Multi-Axis attention 则先采用局 部注意力 (block attention), 再使用稀疏的全局注意力 (grid attention), 这样的 设计充分考虑了图像的 2D 结构,并且仅具有 的线性复杂度。
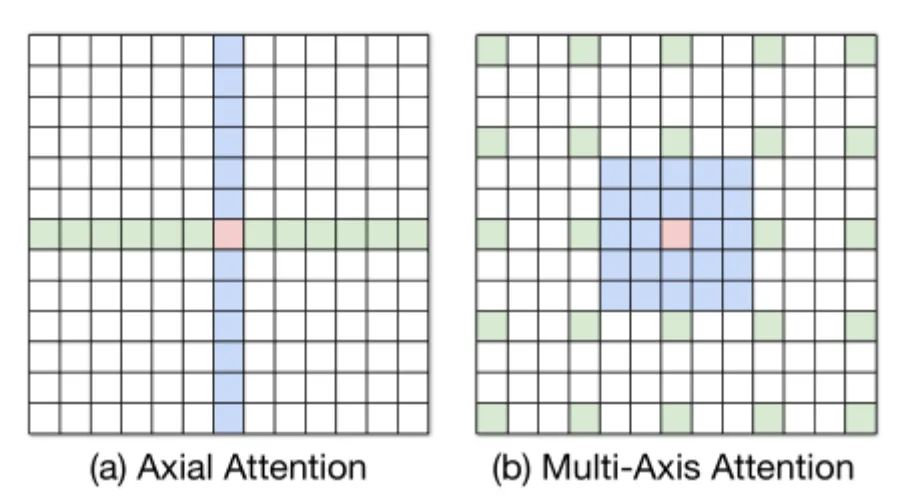 图 3
图 3
Block attention与Grid Attention
Grid attention与空洞卷积有极其相似的地方,本文的两种自注意力计算方式分别关注了局部和全局性,但是相比空洞卷积,本文有一个十分巧妙的设计。首先一个公认的结论是:特别稀疏的空洞卷积容易增加内存压力,因为先要加载一个与卷积核感受野尺寸一致的稠密数据矩阵,再通过mask去掉一些“不需要计算”的数据。但是在Grid attention中使用了einops对张量形状进行改变,从而将其构造为一种运算上的稠密结构。但需要注意的是,稀疏后抓取的信息点位置是固定的,在图像领域一个重要特点是:越靠近中心区域的像素越相关,距离越远的像素越不相关。因此对于这样的稀疏含远距离信息点的计算是否会引入噪声有待论证。
5 实验结果
本文针对图像分类、对象检测与实例分割、图像质量评估、图像生成均进行了详细的实验对比,其参数量与计算量对比如图4所示:
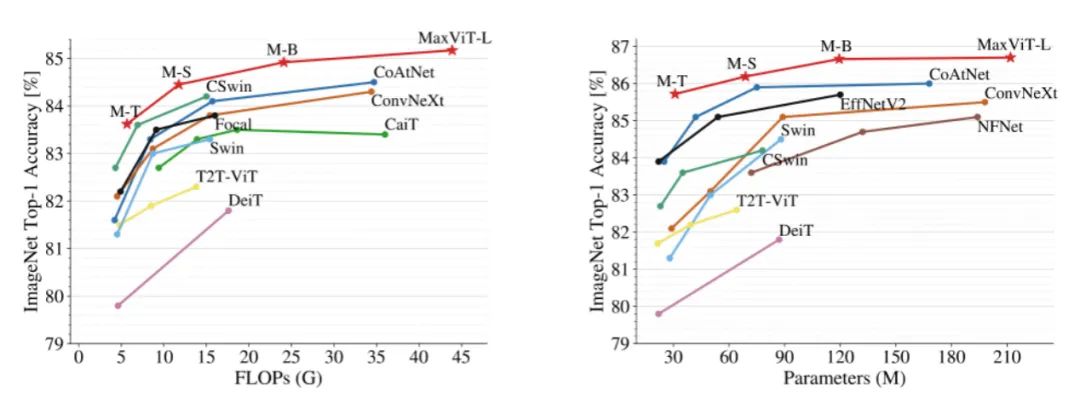 图 4
图 4
在ImageNet-1K的性能对比中,MaxViT-L达到了86.7%的top-1准确率,远超对比的ConvNeXt-L(84.3%)和Swin-B(84.5%)。
COCO数据集中实验对比结果如图5所示:

6 总结
本文提出集局部注意力、全局注意力和卷积计算于一体的灵活MaxViT架构,在实现局部与全局性交互的同时,通过卷积的添加来提升模型泛化性能,实现了模型在不同数据量中的灵活扩展,避免了ViT的易过拟合与Swin Transformer等模型容量有限的问题。最后在本文的附录部分,介绍了详细的实验过程以及不同模型的参数,感兴趣的朋友可以自行阅读查看~
公众号后台回复“数据集”获取30+深度学习数据集下载~

# 极市平台签约作者#

Ziyang Li
知乎:Ziyang Li
东电机器人专业在读,一个努力上进的CVer,一个普普通通的学生。
研究领域:先进传感技术、模式识别、深度学习、机器学习。
希望将路上的收获分享给同样前进的你们,共同进步,一起加油!
作品精选:
CVPR 2022 Oral|百度&中科院开源新的视觉Transformer:卷积与自注意力的完美结合
