
MySQL-Seconds_behind_master的精度误差
MySQL-Seconds_behind_master的精度误差
前言
Seconds_behind_master是我们观察主从延迟的一个重要指标。但任何指标所能表示的精度都是有限的。例如用精度只能到秒的指标去衡量毫秒级的表现就会产生非常大的误差。如果再以此误差去分析问题,就会让思维走上弯路。例如用Seconds_behind_master去评估1s内的主从延迟就是一个典型的例子。
问题现场
在一些问题的排查中,我们注意到一个很奇怪的现象。那就是相同配置的从库表现出来的主从延迟差距有将近500ms。而这两个从库之间的差别就是所在的机房不一样(和主库都不在同一个机房)。如下图所示:
网络问题
难道是网络问题?那我们ping一下吧,最多也就相差1ms。那么还有499ms去哪里了呢,看来还得继续挖掘。
Seconds_behind_master的取点数据
直觉上来说网络问题不可能导致500ms这么大的误差,而机器配置和MySQL版本又是一样的。这就让笔者不得不怀疑这个兼容数据的准确性。所以就先看看这个500ms是怎么计算出来的。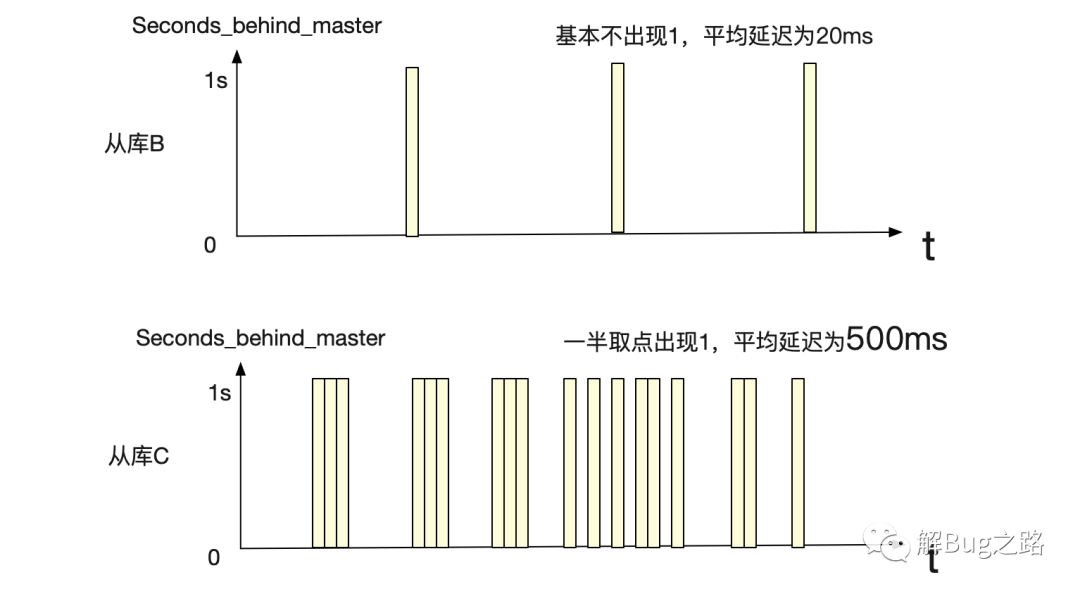
从监控取点数据来看从库C确实有主从延迟,不然为什么有那么多取点为0呢。
Seconds_behind_master什么时候计算出来为1
这时候笔者突然想到一个点,如果主从延迟一个是501ms一个是499ms,那么Seconds_behind_master计算的时候会不会采用四舍五入法。501ms(>=500ms)的就是1,499(<500ms)的就是0?为了了解这一问题,笔者就去翻了翻源码。
Seconds_behind_master在MySQL中的计算源码
计算这个指标的代码有很多微妙的分支,应对了各种corner case。在此笔者只列出和当前问题相关的源码。
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp)
- mi->clock_diff_with_master);
前面time(0) - mi->rli->last_master_timestamp明显就是指时间差。但是,我们要考虑到一个很容易被忽略的常识,也就是不同机器的时间戳是不一样的!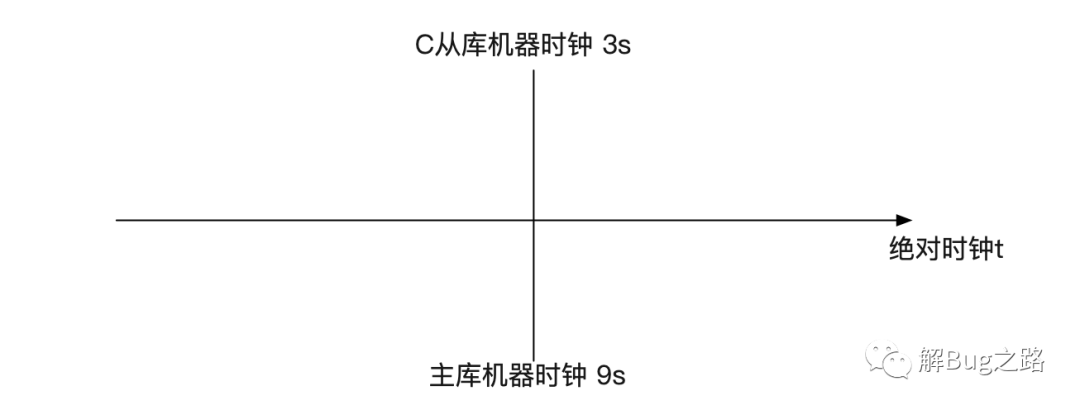
那么很明显的,如果主从实际延迟是0,但是计算的时候没有剔除掉机器时钟的差异。那么主从延迟就是6s。源码中的mi->clock_diff_with_master就是去修正这个差距!而计算这个
clock_diff_with_master就会引起不小的误差。
什么时候计算clock_diff_with_master
笔者在源码中翻阅时候注意到clock_diff_with_master不是每次都去计算的,而是在主从连接上或者重连(reconnect)的那一刻去计算一次。
handle_slave_io
/* 建立主从连接 */
|->safe_connect(thd, mysql, mi))
/* connected: 主从连接成功后,计算一下主从clock_diff_with_master */
|->get_master_version_and_clock
这就自然会导致下面的现象,假设一旦clock_diff_with_master计算有了误差。那么这个误差就会一直存在,直到下次重连为止!
clock_diff_with_master跨秒误差
接着笔者又注意到clock_diff_with_master精度只能到秒。那么自然就会出现下面这几种现象。为了简单起见,我们假设绝对时钟是从0开始,而且我们假设主从延迟是0。只看精度误差所能造成的影响。
在实际主从延迟为0的情况下clock_diff_with_master计算出来是-1,Seconds_behind_master计算为1
尽管有NTP,我们也不可能做到两台机器的时间戳在完全一致(除非两台机器有铯原子钟,那基本就没有毫秒级的误差了)。两台机器之间出现几百毫秒甚至数秒的延迟非常正常。例如假设我当前从库的clock是0.5s,主库的clock是1s。那么由于计算精度(只能到秒)的原因,实际实际只有0.5s的时间差会放大到1s。
那么我们现在可以计算出来在这种情况下Seconds_behind_master的平均值,在这里有一个预先假设就是我们取监控点的时间是随机的。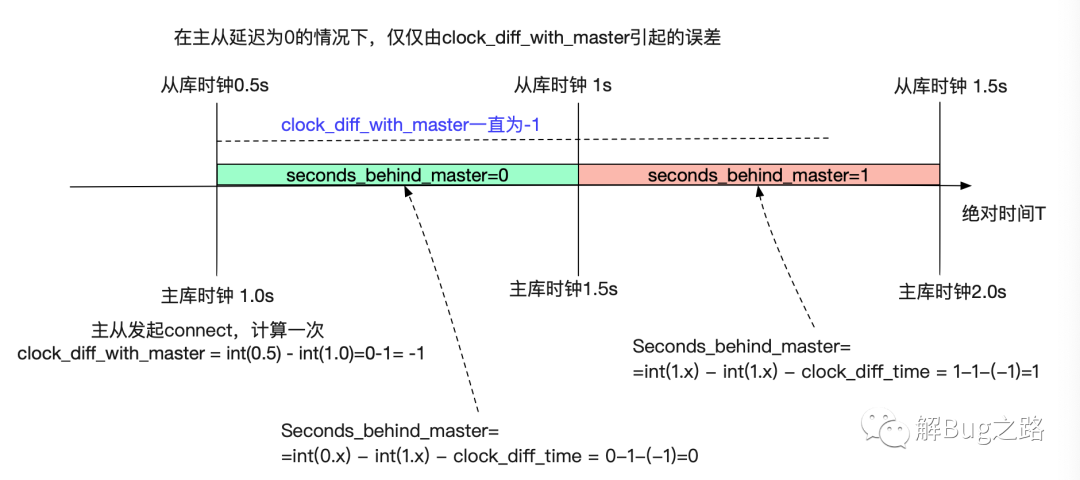
在上图中我们可以看到,在我们取从库时钟[0.5,1.5)这个1s的时间段范围内。在前0.5s,也就是[0.5,1)这个区间中我们计算出来的Seconds_behind_master是0,而在[1,1.5)区间计算的确是1
。那我们的平均值就可以计算出来为(0.5*0+0.5*1)/(1.5-0.5)=0.5=500ms!
也就是说,在没有任何实际主从延迟的情况下,仅仅跨秒这一个因素就能造成好几百毫秒的误差。
实际主从延迟为0的情况下clock_diff_with_master计算为0,Seconds_behind_master计算为-1并被校正为0
另外一个有意思的点是,既然误差能加1,自然也能减1。也就是Seconds_behind_master计算为-1。这就会给观察人员造成一个错觉,从库比主库快!当然了MySQL源码考虑到了这一点,强制校正为0。
在这里,笔者将主从连接的那一刻稍微往前偏移0.1s,就可以构造出刚才说的现象,如下图所示:
MySQL中的源码注释和强行校正逻辑如下所示:
long time_diff= ((long)(time(0) - mi->rli->last_master_timestamp)
- mi->clock_diff_with_master);
/*
Apparently on some systems time_diff can be <0. Here are possible
reasons related to MySQL:
- the master is itself a slave of another master whose time is ahead.
- somebody used an explicit SET TIMESTAMP on the master.
Possible reason related to granularity-to-second of time functions
(nothing to do with MySQL), which can explain a value of -1:
assume the master's and slave's time are perfectly synchronized, and
that at slave's connection time, when the master's timestamp is read,
it is at the very end of second 1, and (a very short time later) when
the slave's timestamp is read it is at the very beginning of second
2. Then the recorded value for master is 1 and the recorded value for
slave is 2. At SHOW SLAVE STATUS time, assume that the difference
between timestamp of slave and rli->last_master_timestamp is 0
(i.e. they are in the same second), then we get 0-(2-1)=-1 as a result.
This confuses users, so we don't go below 0: hence the max().
last_master_timestamp == 0 (an "impossible" timestamp 1970) is a
special marker to say "consider we have caught up".
*/
protocol->store((longlong)(mi->rli->last_master_timestamp ?
max(0L, time_diff) : 0));
如何获得精确的毫秒级的主从延迟
由于Seconds_behind_master精度的原因,完全无法衡量毫秒级的主从延迟,所以出现了pt-heartbeat这样的工具去精确的计算主从间毫秒级的延迟。在后续采用pt-heartbeat对两个库进行监控后,这两个看上去平均延迟相差500ms的从库实际主从延迟差距在10ms之内。
总结
任何指标都有其表示的精度,而在其精度表示范围之外就会产生相当大的误差,以至于能够误导我们的判断。当对某一项的指标感到很反常识的时候,可以考虑是不是本身指标并不能描述当前我们想要观察的现象。例如本文中的阐述就表明Seconds_behind_master对1s的主从延迟的刻画没有太大的意义。
公众号
关注笔者公众号,获取更多干货文章: