
港中文提出 EdgeViT | 超越MobileViT与MobileNet,实现Transformer在CPU上实时
共 5162字,需浏览 11分钟
· 2022-05-14


在计算机视觉领域,基于
Self-attention的模型(如(ViTs))已经成为CNN之外的一种极具竞争力的架构。尽管越来越强的变种具有越来越高的识别精度,但由于Self-attention的二次复杂度,现有的ViT在计算和模型大小方面都有较高的要求。虽然之前的
CNN的一些成功的设计选择(例如,卷积和分层结构)已经被引入到最近的ViT中,但它们仍然不足以满足移动设备有限的计算资源需求。这促使人们最近尝试开发基于最先进的MobileNet-v2的轻型MobileViT,但MobileViT与MobileNet-v2仍然存在性能差距。在这项工作中,作者进一步推进这一研究方向,引入了
EdgeViTs,一个新的轻量级ViTs家族,也是首次使基于Self-attention的视觉模型在准确性和设备效率之间的权衡中达到最佳轻量级CNN的性能。这是通过引入一个基于
Self-attention和卷积的最优集成的高成本的local-global-local(LGL)信息交换瓶颈来实现的。对于移动设备专用的评估,不依赖于不准确的proxies,如FLOPs的数量或参数,而是采用了一种直接关注设备延迟和能源效率的实用方法。在图像分类、目标检测和语义分割方面的大量实验验证了
EdgeViTs在移动硬件上的准确性-效率权衡方面与最先进的高效CNN和ViTs相比具有更高的性能。具体地说,EdgeViTs在考虑精度-延迟和精度-能量权衡时是帕累托最优的,几乎在所有情况下都实现了对其他ViT的超越,并可以达到最高效CNN的性能。
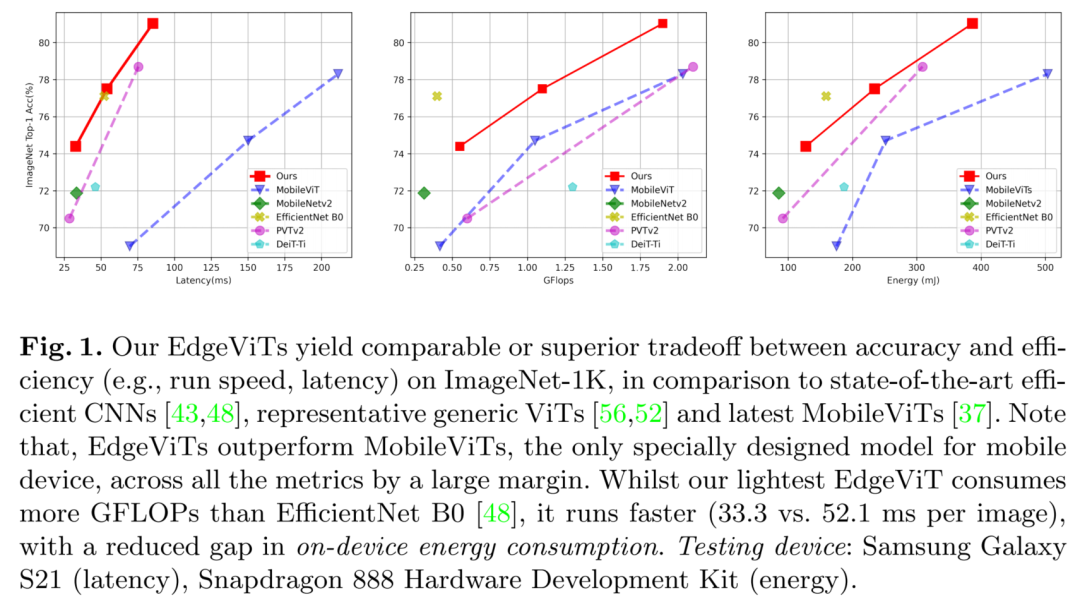
1EdgeViTs
1.1 总体架构
为了设计适用于移动/边缘设备的轻量级ViT,作者采用了最近ViT变体中使用的分层金字塔结构(图2(a))。Pyramid Transformer模型通常在不同阶段降低了空间分辨率同时也扩展了通道维度。每个阶段由多个基于Transformer Block处理相同形状的张量,类似ResNet的层次设计结构。
基于Transformer Block严重依赖于具有二次复杂度的Self-attention操作,其复杂度与视觉特征的空间分辨率呈2次关系。通过逐步聚集空间Token,Pyramid Transformer可能比各向同性模型(ViT)更有效。
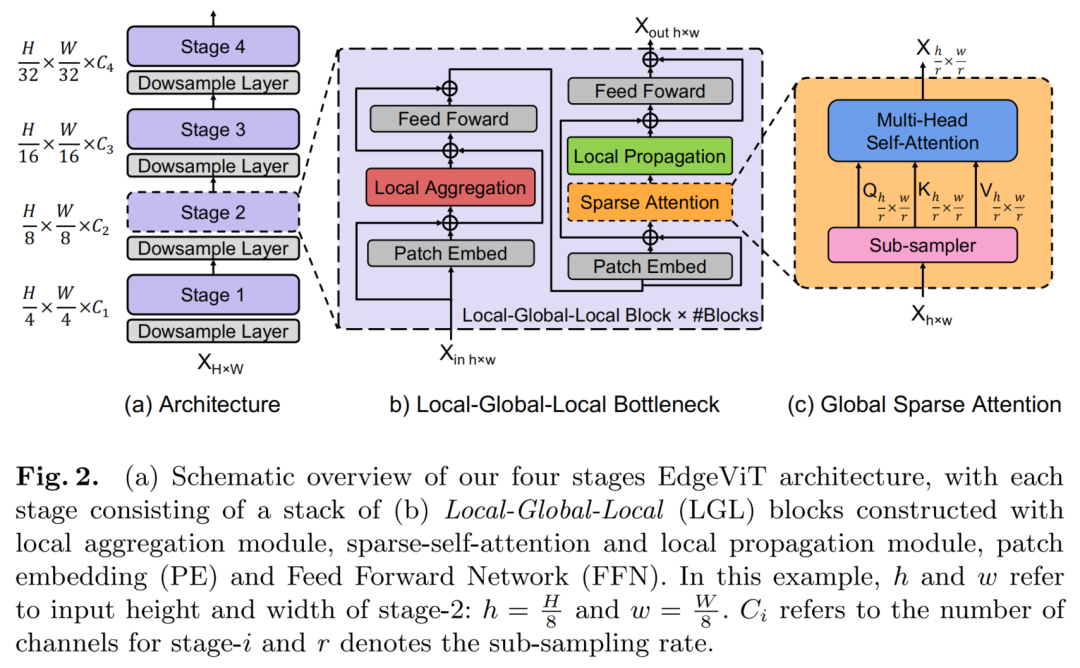
在这项工作中,作者深入到Transformer Block,并引入了一个比较划算的Bottlneck,Local-Global-Local(LGL)(图2(b))。LGL通过一个稀疏注意力模块进一步减少了Self-attention的开销(图2(c)),实现了更好的准确性-延迟平衡。
1.2 Local-Global-Local bottleneck
Self-attention已被证明是非常有效的学习全局信息或长距离空间依赖性的方法,这是视觉识别的关键。另一方面,由于图像具有高度的空间冗余(例如,附近的Patch在语义上是相似的),将注意力集中到所有的空间Patch上,即使是在一个下采样的特征映射中,也是低效的。
因此,与以前在每个空间位置执行Self-attention的Transformer Block相比,LGL Bottleneck只对输入Token的子集计算Self-attention,但支持完整的空间交互,如在标准的Multi-Head Self-attention(MHSA)中。既会减少Token的作用域,同时也保留建模全局和局部上下文的底层信息流。
为了实现这一点,作者将Self-attention分解为连续的模块,处理不同范围内的空间Token(图2(b))。
这里引入了3种有效的操作:
Local aggregation:仅集成来自局部近似 Token信号的局部聚合Global sparse attention:建模一组代表性 Token之间的长期关系,其中每个Token都被视为一个局部窗口的代表;Local propagation:将委托学习到的全局上下文信息扩散到具有相同窗口的非代表 Token。
将这些结合起来,LGL Bottleneck就能够以低计算成本在同一特征映射中的任何一对Token之间进行信息交换。下面将详细说明每一个组成部分:
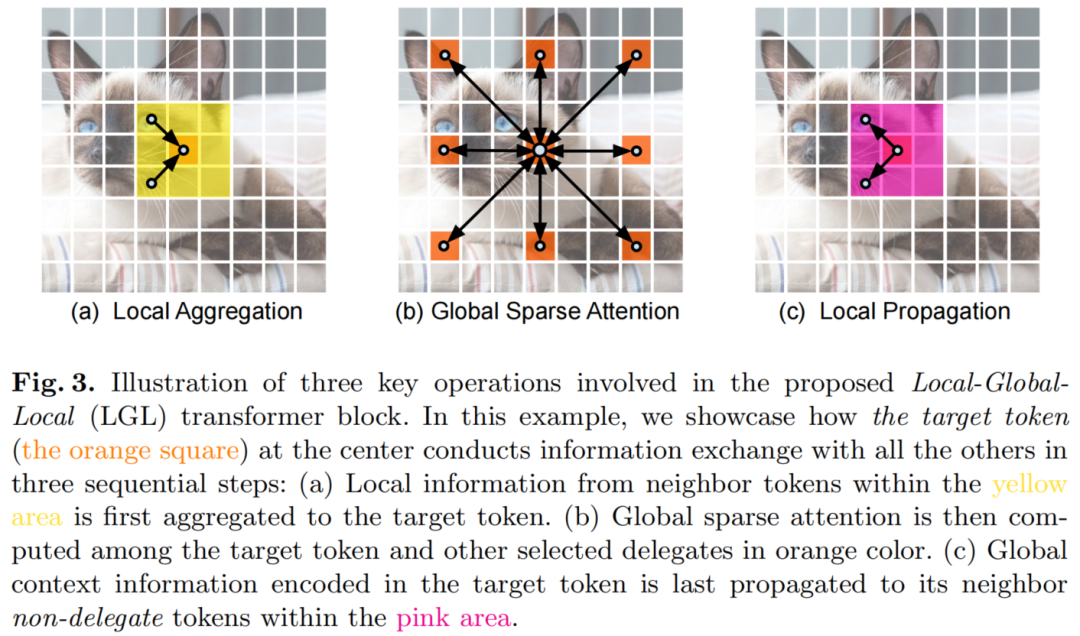
1、Local aggregation
对于每个Token,利用Depth-wise和Point-wise卷积在大小为k×k的局部窗口中聚合信息(图3(a))。
2、Global sparse attention
对均匀分布在空间中的稀疏代表性Token集进行采样,每个r×r窗口有一个代表性Token。这里,r表示子样本率。然后,只对这些被选择的Token应用Self-attention(图3(b))。这与所有现有的ViTs不同,在那里,所有的空间Token都作为Self-attention计算中的query被涉及到。
3、Local propagation
通过转置卷积将代表性Token中编码的全局上下文信息传播到它们的相邻的Token中(图3(c))。
最终,LGL bottleneck可以表达为:
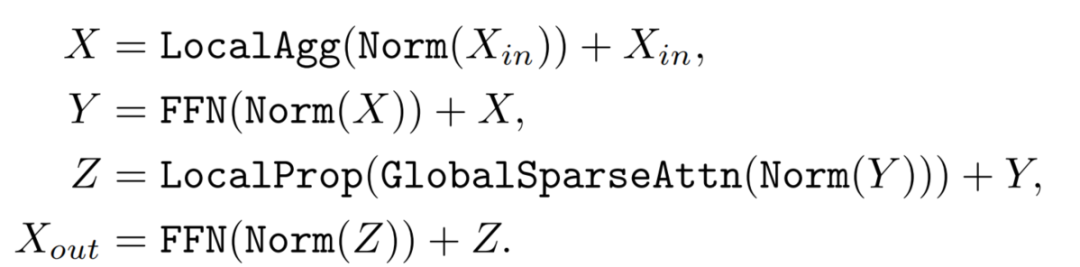
这里,表示输入张量。Norm是Layer Normalization操作。LocalAgg表示局部聚合算子,FFN是一个双层感知器。GlobalSparseAttn是全局稀疏Self-attention。LocalProp是局部传播运算符。为简单起见,这里省略了位置编码。注意,所有这些操作符都可以通过在标准深度学习平台上的常用和高度优化的操作来实现。因此,LGL bottleneck对于实现是友好的。
Pytorch实现
class LocalAgg():
def __init__(self, dim):
self.conv1 = Conv2d(dim, dim, 1)
self.conv2 = Conv2d(im, dim, 3, padding=1, groups=dim)
self.conv3 = Conv2d(dim, dim, 1)
self.norm1 = BatchNorm2d(dim)
self.norm2 = BatchNorm2d(dim)
def forward(self, x):
"""
[B, C, H, W] = x.shape
"""
x = self.conv1(self.norm1(x))
x = self.conv2(x)
x = self.conv3(self.norm2(x))
return x
class GlobalSparseAttn():
def __init__(self, dim, sample_rate, scale):
self.scale = scale
self.qkv = Linear(dim, dim * 3)
self.sampler = AvgPool2d(1, stride=sample_rate)
kernel_size=sr_ratio
self.LocalProp = ConvTranspose2d(dim, dim, kernel_size, stride=sample_rate, groups=dim
)
self.norm = LayerNorm(dim)
self.proj = Linear(dim, dim)
def forward(self, x):
"""
[B, C, H, W] = x.shape
"""
x = self.sampler(x)
q, k, v = self.qkv(x)
attn = q @ k * self.scale
attn = attn.softmax(dim=-1)
x = attn @ v
x = self.LocalProp(x)
x = self.proj(self.norm(x))
return x
class DownSampleLayer():
def __init__(self, dim_in, dim_out, downsample_rate):
self.downsample = Conv2d(dim_in, dim_out, kernel_size=downsample_rate, stride=
downsample_rate)
self.norm = LayerNorm(dim_out)
def forward(self, x):
x = self.downsample(x)
x = self.norm(x)
return x
class PatchEmbed():
def __init__(self, dim):
self.embed = Conv2d(dim, dim, 3, padding=1, groups=dim)
def forward(self, x):
return x + self.embed(x)
class FFN():
def __init__(self, dim):
self.fc1 = nn.Linear(dim, dim*4)
self.fc2 = nn.Linear(dim*4, dim)
def forward(self, x):
x = self.fc1(x)
x = GELU(x)
x = self.fc2(x)
return x
与其他经典结构的对比
LGL bottleneck与最近的PVTs和Twins-SVTs模型有一个相似的目标,这些模型试图减少Self-attention开销。然而,它们在核心设计上有所不同。PVTs执行Self-attention,其中Key和Value的数量通过strided-convolutions减少,而Query的数量保持不变。换句话说,PVTs仍然在每个网格位置上执行Self-attention。
在这项工作中,作者质疑位置级Self-attention的必要性,并探索由LGL bottleneck所支持的信息交换在多大程度上可以近似于标准的MHSA。Twins-SVTs结合了Local-Window Self-attention和PVTs的Global Pooled Attention。这不同于LGL bottleneck的混合设计,LGL bottleneck同时使用分布在一系列局部-全局-局部操作中的Self-attention操作和卷积操作。
如实验所示(表2和表3)所示,LGL bottleneck的设计在模型性能和计算开销(如延迟、能量消耗等)之间实现了更好的权衡。
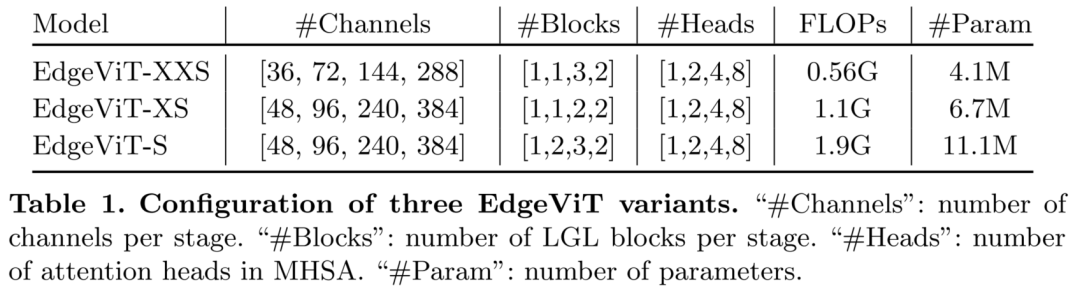
1.3 结构变体
2实验
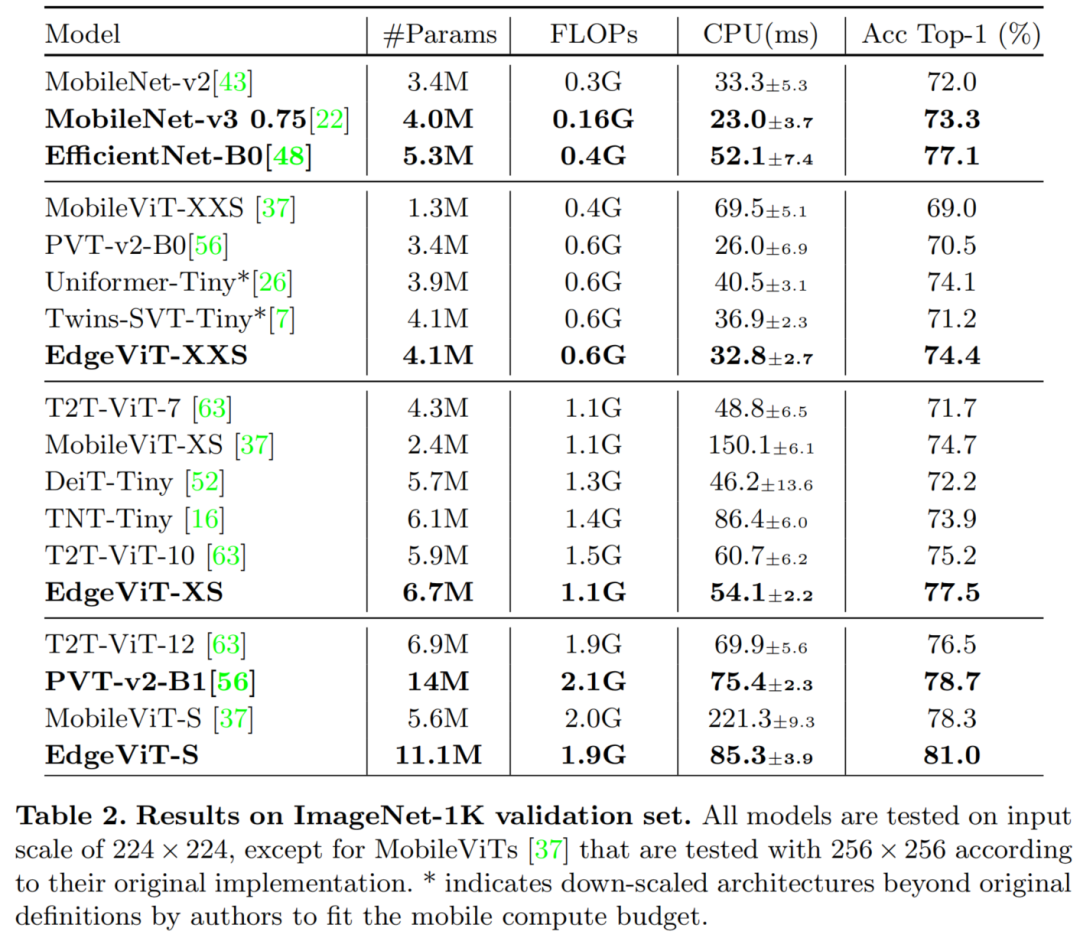
2.1 ImageNeT精度SoTA
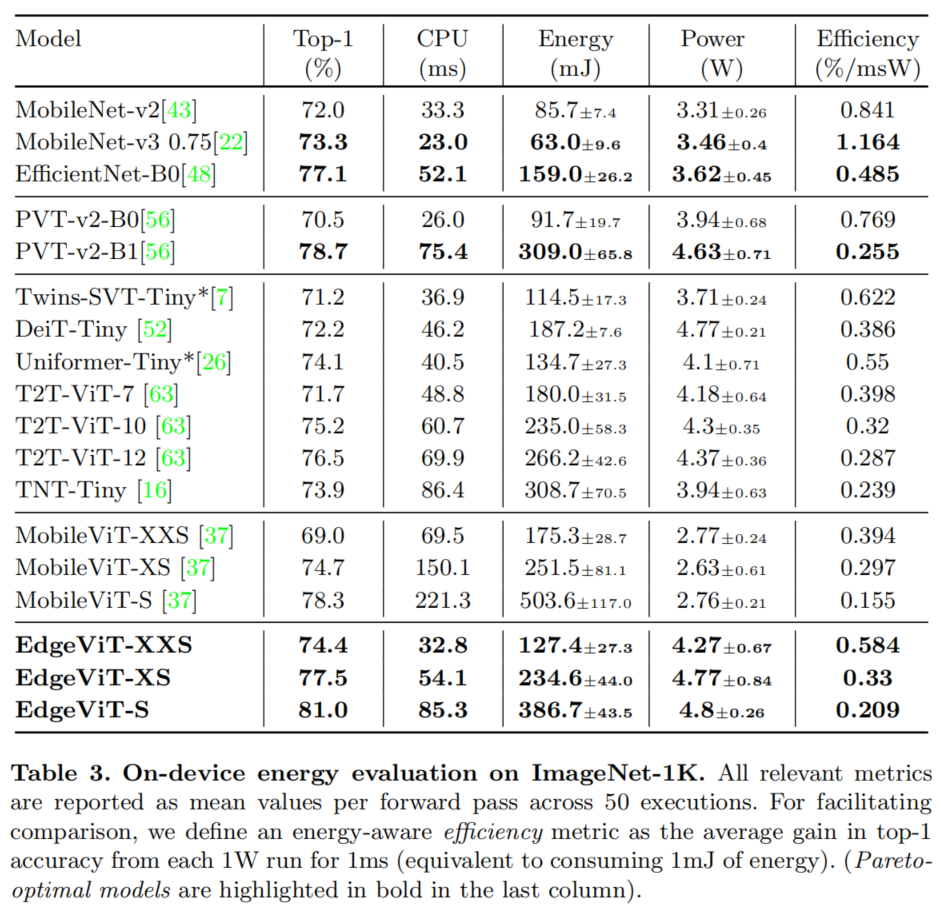
2.2 实时性与精度对比
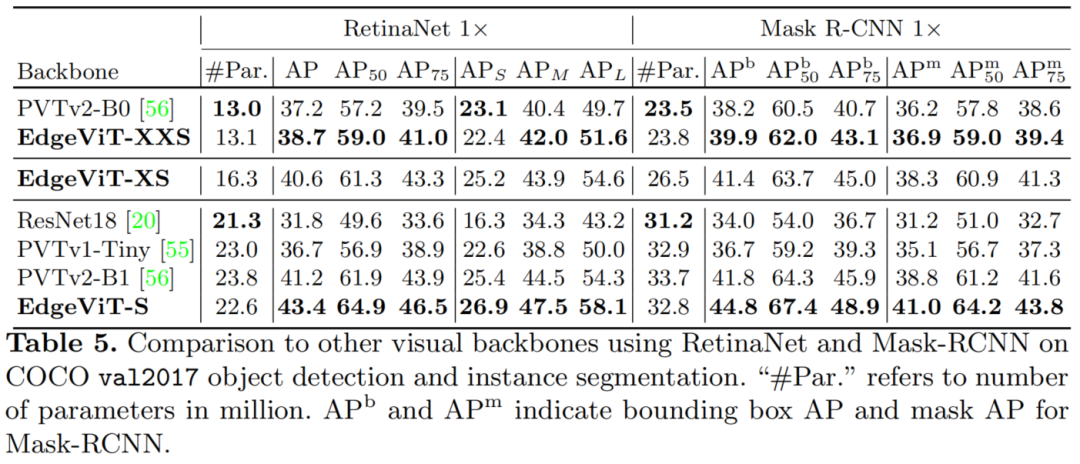
2.3 目标检测任务
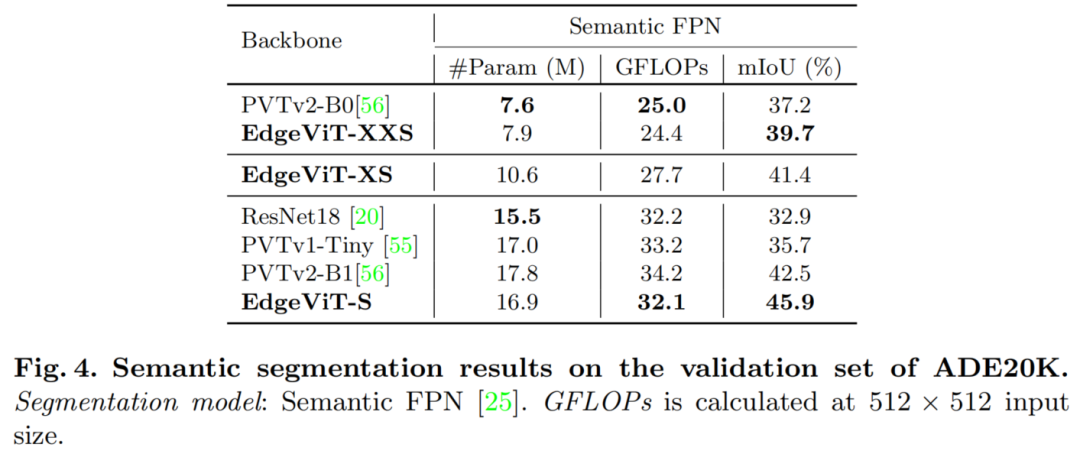
2.4 语义分割任务
3参考
[1].EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers
4推荐阅读
微软提出MiniViT | 把DeiT压缩9倍,性能依旧超越ResNet等卷积网络
Sparse R-CNN升级版 | Dynamic Sparse R-CNN使用ResNet50也能达到47.2AP
探究Integral Pose Regression性能不足的原因
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
