 AI算法与图像处理
AI算法与图像处理




点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
来源:机器之心编辑部
复旦大学、微软 Cloud+AI 的研究者将视频表征学习解耦为空间信息表征学习和时间动态信息表征学习,提出了首个视频 Transformer 的 BERT 预训练方法 BEVT。该研究已被 CVPR 2022 接收。

论文地址:https://arxiv.org/abs/2112.01529
源代码:https://github.com/xyzforever/BEVT
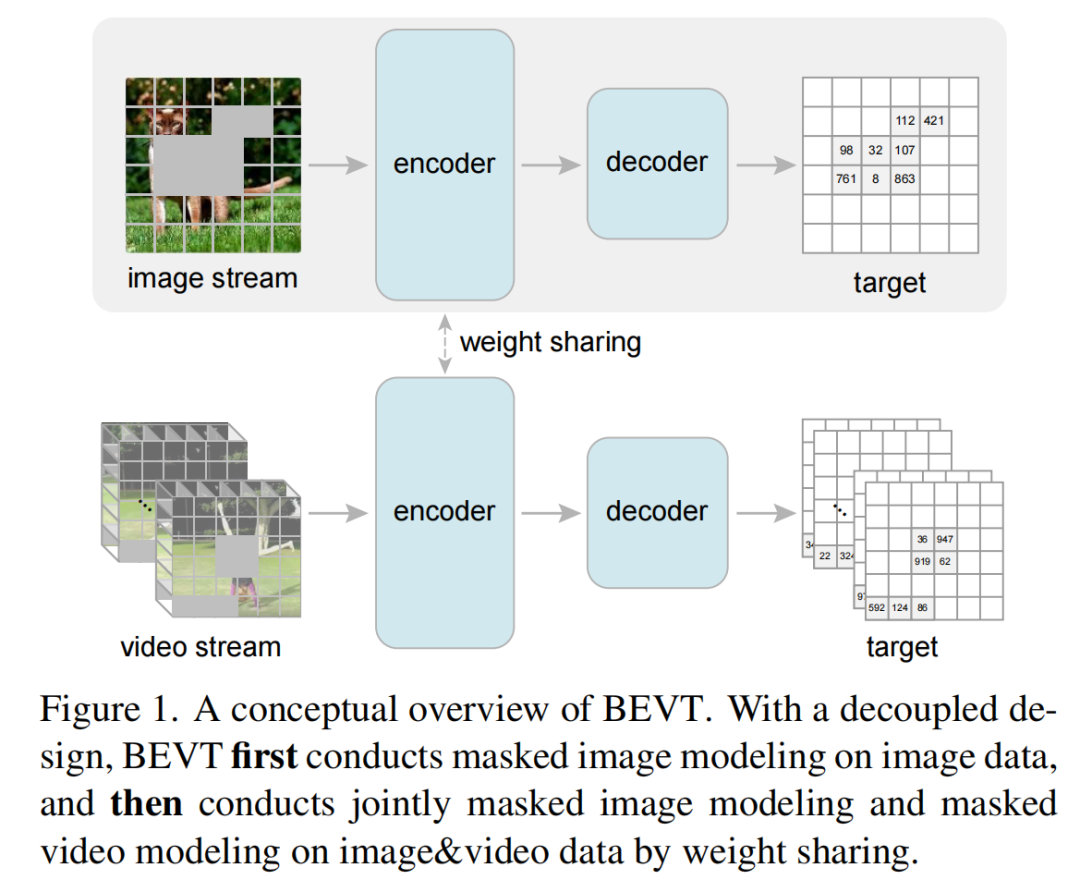
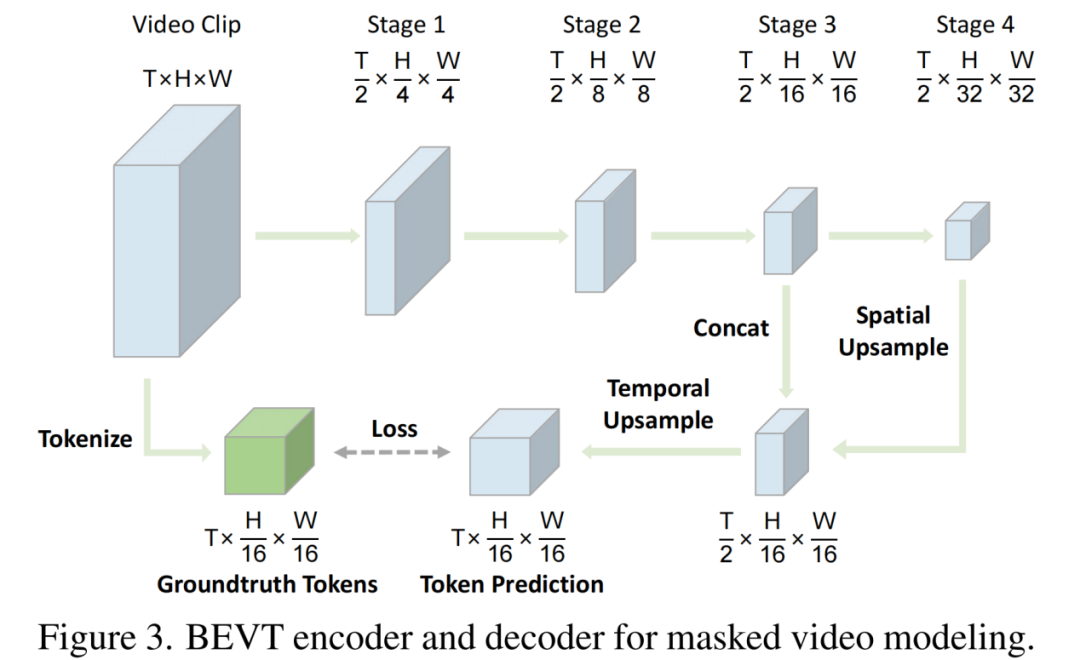
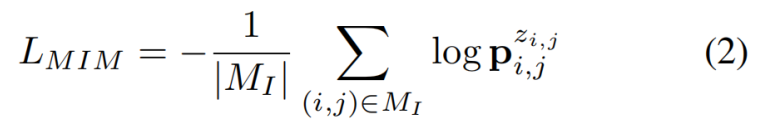
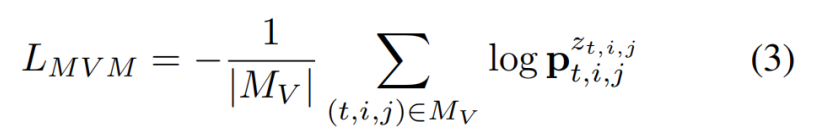
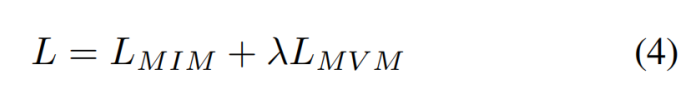
图像通路使用 2D patch 划分方式,而视频通路使用 3D patch 划分方式;图像通路和视频通路采用独立的 patch embedding 层分别将 2D patch 和 3D patch 投影到相同维度。
对于图像通路,将 Video Swin Transformer 自注意力机制中的 3D shifted local window 转变为 2D 版本(即 Swin Transformer 中的方式),此时图像通路使用三维相对位置编码中相对时间距离等于 0 的子矩阵作为二维相对位置编码,而其他自注意力模块权重可以完全共享。权重共享机制使得图像通路和视频通路的联合预训练能够真正优化一个近乎统一的 Transformer 编码器。
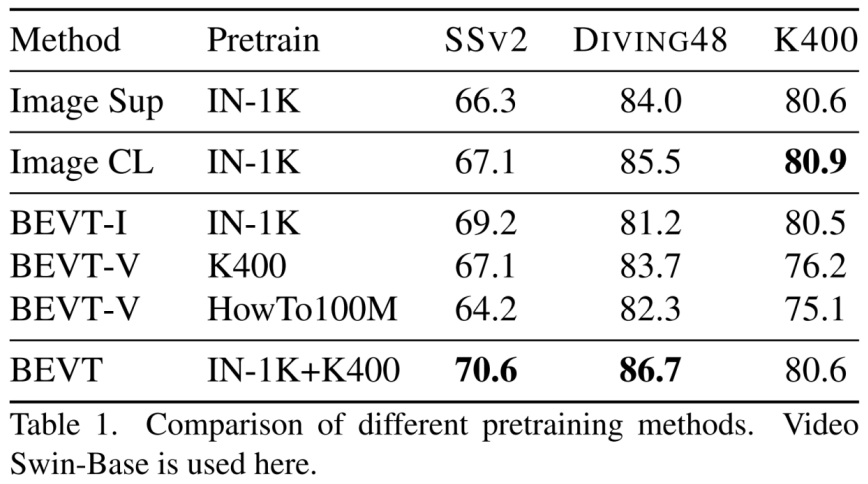
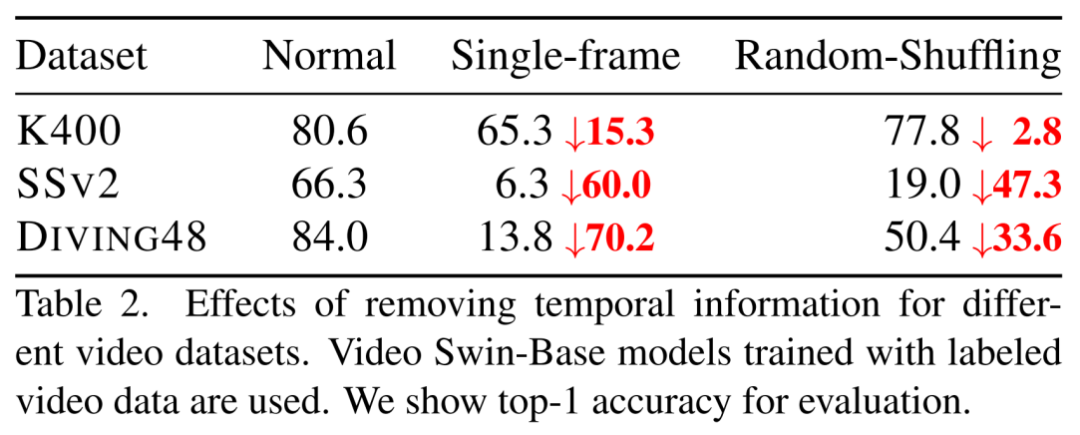
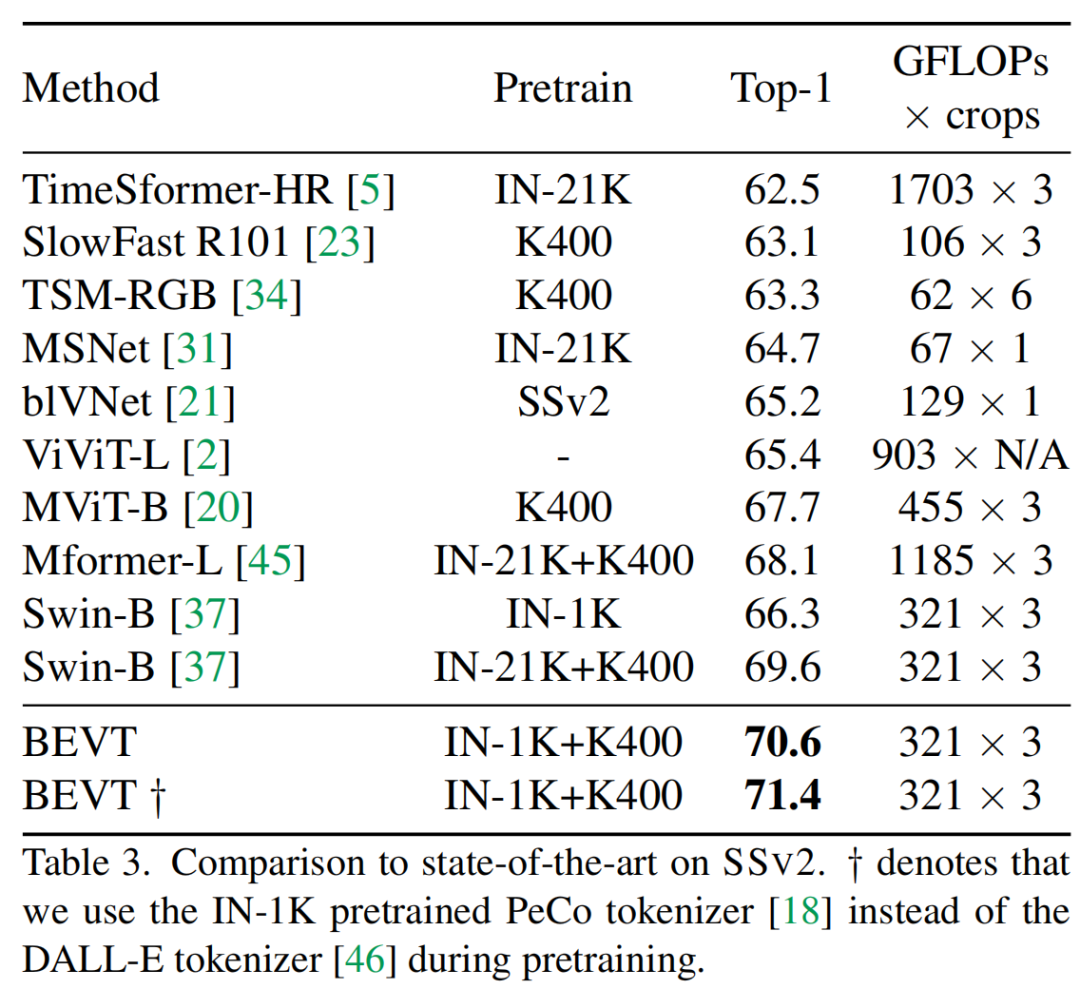
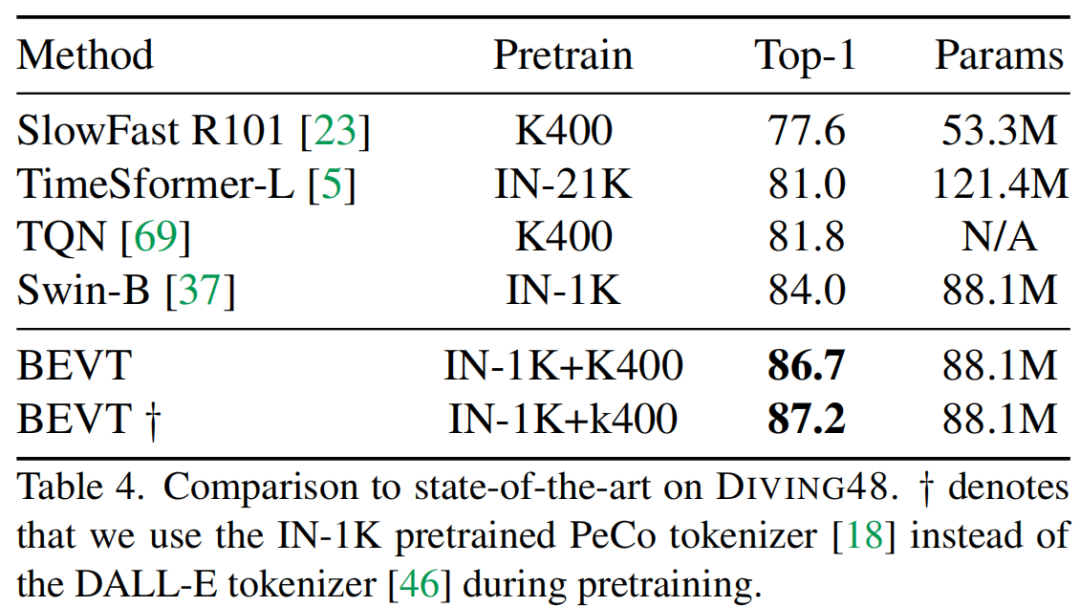
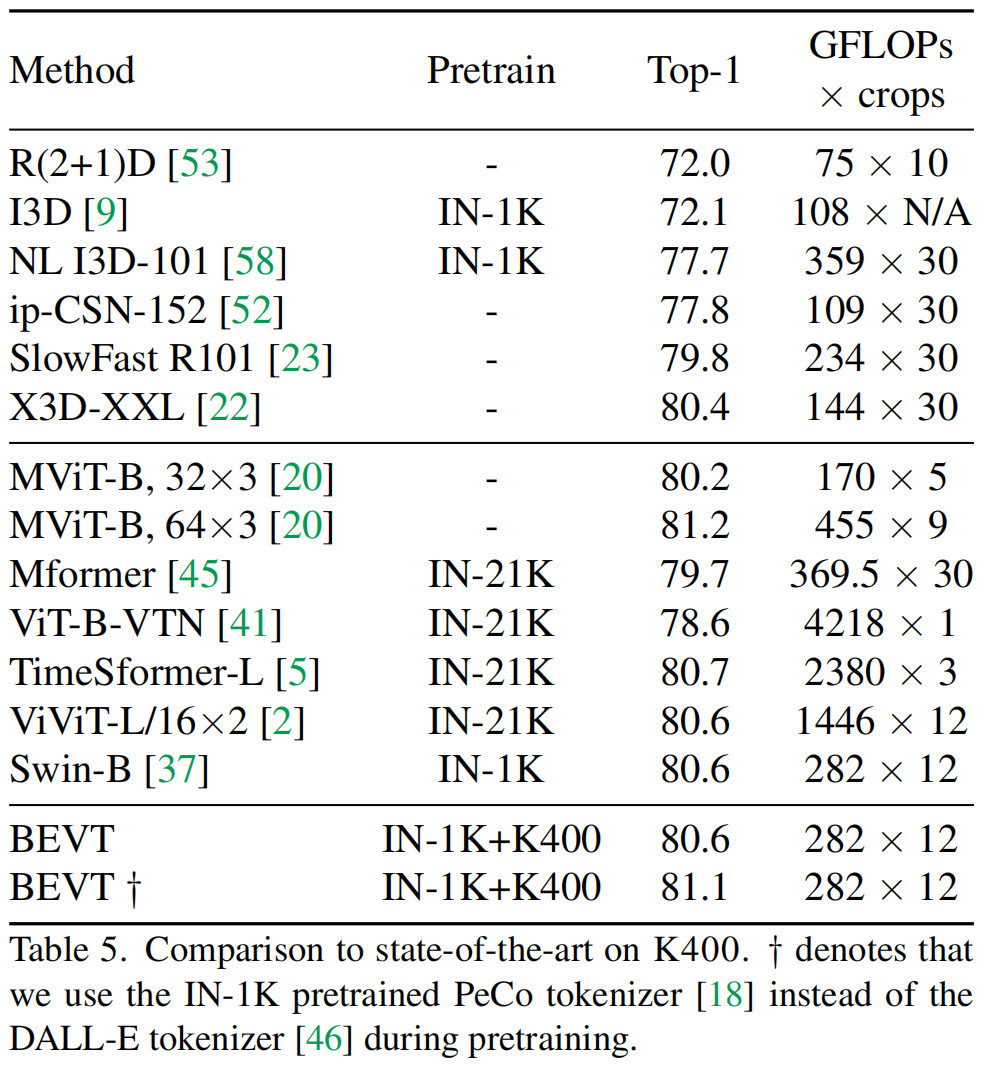
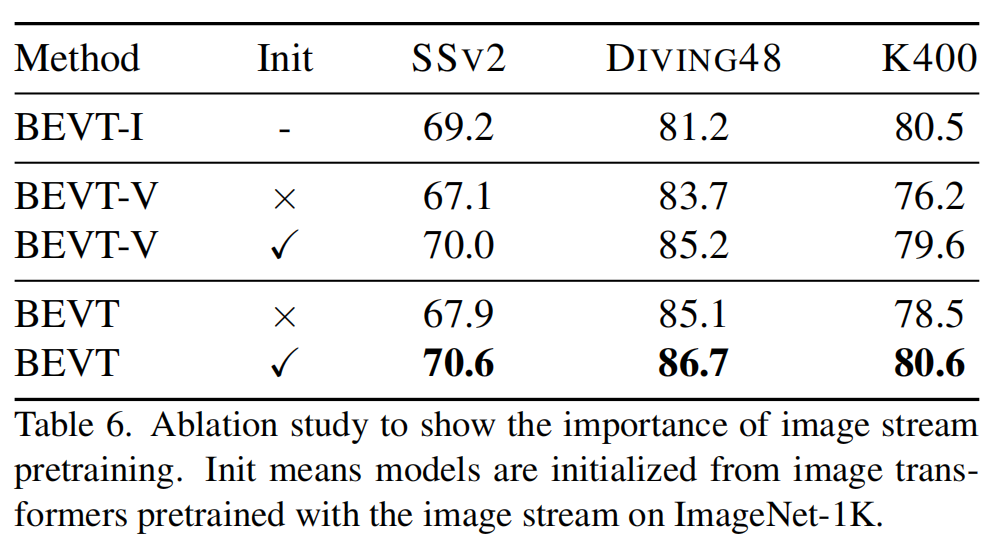
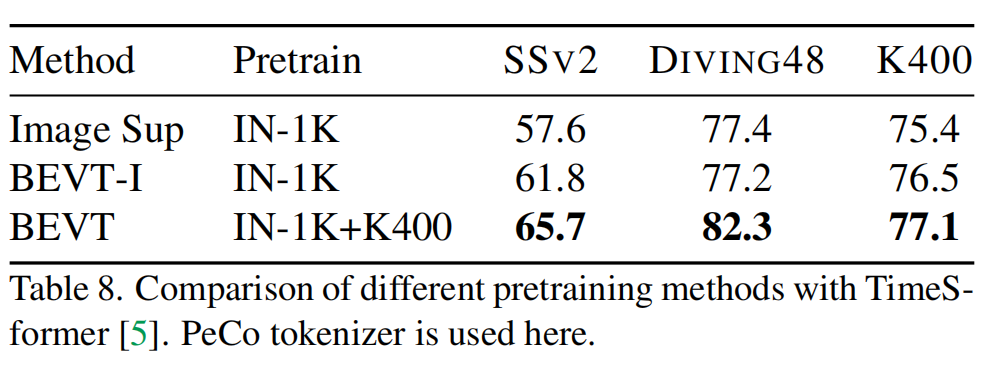
作为首个视频 Transformer BERT 预训练方法,BEVT 不仅将图像 Transformer BERT 预训练中的掩码图像建模任务扩展为了掩码视频建模任务,还通过设计图像 - 视频双路联合预训练框架,避免了直接在大规模视频数据上从头训练这种相对低效的做法,并使得模型在不同类型的视频数据集上均能取得良好的迁移性能。
这种图像 - 视频联合自监督预训练方法为视频 Transformer 上的表征学习提供了一种新的高效训练方式,且可以推广到多种视频 Transformer 架构上。研究者希望后面的工作能在这种多源数据统一架构预训练框架的基础上,进一步考虑在有限资源下的高效预训练、多种自监督任务联合训练、多模态数据联合训练等具有挑战性的问题,实现图像 - 视频 / 多模态大一统模型研究的更大突破。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文



