
非度量多维排列 NMDS (Non-metric multidimensional scaling)分析
共 913字,需浏览 2分钟
· 2022-04-26
多维排列 (Multidimensional scaling,MDS)是可视化多变量样品(如多个物种丰度、多个基因表达)相似性水平的一种方法。其基于距离矩阵进行一系列的排序分析。
经典的MDS
(CMDS)分析就是前面提到的PCoA分析,也称为度量性MDS分析。而与之相对的是非度量多维排列
(Non-metric multidimensional scaling, NMDS)。
非度量多维排列
(NMDS)是基于相异矩阵或距离矩阵进行排序分析的间接梯度分析方法。NMDS的目标与PCA或PCoA类似
(一文读懂PCA分析
(原理、算法、解释和可视化);一文学会PCA/PCoA相关统计检验(PERMANOVA)和可视化),都是希望能在低维空间尽可能准确地展示样品在高维空间的关系。在低维空间,两个样品点距离越近,其相似度越高。NMDS的主要目的是识别和解释样品的分布模式,反应样品之间的顺序关系,找到能展示样品差异来源的梯度信息,如地理环境信息、生态信息等。
与MDS不同的是,NMDS分析将原始的距离矩阵转换为秩矩阵
(rank metric)再进行降维分析。NMDS弱化距离矩阵中具体值的大小,更关注其排序关系。假如样品A和样品B之间的距离是5,样品A和样品C之间的距离是10,转换后不再描述距离,而是说样品B是与样品A第1近的,样品C与样品A是第2近的,用排序的1,2代替原始的距离。所以称为“非参数”分析。
NMDS可以应用于 1) 存在配对距离缺失的数据中,2) 任何距离算法产生的矩阵,3) 定量、半定量、定性或混合变量的分析。
在多样本、物种数量多的情况下,NMDS模型能更准确地反映出距离矩阵的数值排序信息。因此当样本或者物种数量过多的时候使用NMDS会更加准确。
NMDS是不断迭代的过程,通过不断尝试找到样品在维度空间的最合适位置。其评估标准是stress值,表示
观察到的距离和拟合的距离的不一致性。Stress也可以理解为样品在降维后形成的空间的距离与其在原始多维空间的距离的差值。这个值越小越好,说明在低维空间更完整地捕获了高维空间的信息。对于NMDS二维分析,通常认为stress<0.2时有一定的解释意义;当stress<0.1时,可认为是一个好的排序;当 stress<0.05时,则具有很好的代表性。
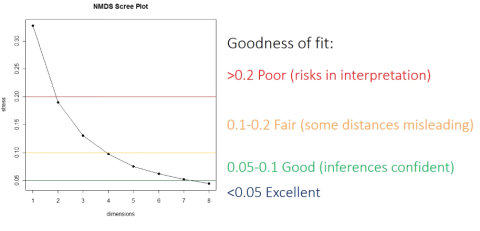
NMDS在分析之前就会选择降维轴的数目并把数据拟合到所选的轴进行排序(轴越多,stress值就会越少;但轴越多,越难以解释)。NMDS不同于其它排序算法的地方在于其最终解不唯一,而是多次尝试获得一个能接受的解。NMDS算法不使用奇异值-奇异向量等因子分解技术,同时NMDS1、NMDS2也不一定是能解释最大差异的轴(不过后面分析时会使得第一轴解释的差异最大,以便更好可视化)。所以NMDS的轴可以按需转换。
在生物信息中,NMDS用于时间序列表达谱中鉴定基因的变化模式 (https://www.biorxiv.org/content/10.1101/538918v1.full)和宏基因组数据中分析微生物群落的差异。
metaMDS - NMDS分析的推荐步骤
NMDS通常被认为是生态学领域最稳定的非限制性排序方法 (Minchin
1987)。metaMDS是vagan中的一个组合了Minchin’s (1987)
推荐的分析步骤的NMDS分析函数,其包含下面这些步骤:
数据转换:在参数
autotransform=T(默认)时,如果输入的物种丰度矩阵(一般是抽平后的物种丰度矩阵)中最大的丰度值大于9则会进行Wisconsin双重标准化(每个物种丰度值除以该物种最大丰度,再在各个样品内计算相对丰度);如果最大的丰度值大于50,则会对数据先进行开方处理再做Wisconsin转换。如果是自己转换过的数据,比如hellinger转换后的数据不想再被进一步转换,可以设置autotransform = FALSE。如果输入的是距离矩阵,这一步也会直接跳过。计算相异矩阵: 默认是
Bray-Curtis,也通常是效果最好的。也可以选择vegdist输出的其它距离矩阵。对于非群体构成数据,可以用函数rankindex寻找自己的数据最合适的矩阵算法。如果输入的是距离矩阵,这一步也会直接跳过。最短路径插值 (Step-across dissimilarities): 如果大比例的样品没有共有物种,则排序将很难进行。在这一情况下,就需要通过计算这些不同样品间的最短路径代替样品之间的相异值或距离。默认的NMDS引擎函数
monoMDS可以自动处理无共享物种的情况,不需要额外调用stepacross函数进行最短路径计算。而NMDS的另一个引擎函数isoMDS则不能自动处理这一情况,需要设置noshare=T触发stepacross步骤。如果输入的是距离矩阵,这一步也会直接跳过。多轮NMDS寻找最优解: NMDS会很容易陷入局部最优点,需要用不同的随机起始多运行几次才更可能获得全局最优解。
metaMDS的策略是先运行PCoA分析并以其结果作为参考标准 (RUN 0)。如果设置了previous.best参数,则以该参数传入的NMDS结果作为参考。随后metaMDS会设定多个随机起始点运行NMDS分析 (参数try和trymax可以设置最小和最大尝试次数)。如果某一个NMDS的结果优于当前最优结果 (判断标准是:更低的stress值),则该结果升级为当前最优结果,继续循环。可以设置trace = 2或更大的值跟踪这一优化过程。设置parallel=x设置进程数加速运算。结果优化:
metaMDS在获得NMDS结果后,调用postMDS进一步优化结果:1) 结果整体向坐标轴中心聚拢; 2) 根据主成分旋转NMDS1使第一维解释的差异最大 (也可以调用函数MDSrotate旋转第一轴与指定的环境变量平行); 3) 群落相似性单位均分。物种得分: 在最终NMDS结果中用函数
wascores计算物种的加权得分。
实战NMDS分析
继续使用之前的测试数据(如何读入自己的数据见前文和抄代码的时候总是遇到原始数据应该长什么样的问题)。
注意:测试数据已经做过了转置,每一行为一个样品,每一列为一个物种;自己的数据通常是每行为一个物种/OTU,每列为一个样品,读入后需要转置。
library(vegan)
data("dune")
data("dune.env")
rownames(dune) <- paste0("Sample",1:nrow(dune))
# 已经做了转置,样品在行,物种在列
head(dune)
## Achimill Agrostol Airaprae Alopgeni Anthodor Bellpere Bromhord Chenalbu Cirsarve Comapalu Eleopalu Elymrepe Empenigr Hyporadi
## Sample1 1 0 0 0 0 0 0 0 0 0 0 4 0 0
## Sample2 3 0 0 2 0 3 4 0 0 0 0 4 0 0
## Sample3 0 4 0 7 0 2 0 0 0 0 0 4 0 0
## Sample4 0 8 0 2 0 2 3 0 2 0 0 4 0 0
## Sample5 2 0 0 0 4 2 2 0 0 0 0 4 0 0
## Sample6 2 0 0 0 3 0 0 0 0 0 0 0 0 0
## Juncarti Juncbufo Lolipere Planlanc Poaprat Poatriv Ranuflam Rumeacet Sagiproc Salirepe Scorautu Trifprat Trifrepe Vicilath
## Sample1 0 0 7 0 4 2 0 0 0 0 0 0 0 0
## Sample2 0 0 5 0 4 7 0 0 0 0 5 0 5 0
## Sample3 0 0 6 0 5 6 0 0 0 0 2 0 2 0
## Sample4 0 0 5 0 4 5 0 0 5 0 2 0 1 0
## Sample5 0 0 2 5 2 6 0 5 0 0 3 2 2 0
## Sample6 0 0 6 5 3 4 0 6 0 0 3 5 5 0
## Bracruta Callcusp
## Sample1 0 0
## Sample2 0 0
## Sample3 2 0
## Sample4 2 0
## Sample5 2 0
## Sample6 6 0
rownames(dune.env) <- paste0("Sample",1:nrow(dune.env))
# 通过metaMDS执行NMDS推荐分析步骤
# k=2; Number of dimensions. NB., the number of points n should be n > 2*k + 1,
# and preferably higher in global non-metric MDS, and still higher in local NMDS.
# try, tryamx: Minimum and maximum numbers of random starts in search of stable solution.
# After try has been reached, the iteration will stop when two convergent solutions
# were found or trymax was reached.
# autotransform: Use simple heuristics for possible data transformation of typical
# community data (see below). If you do not have community data,
# you should probably set **autotransform = FALSE**.
set.seed(1)
dune_nmds <- metaMDS(dune, distance="bray", k=2, try=20, trymax=50, autotransform=T,
model="global", stress=1, maxit=200, parallel=2, noshare=F)
## Run 0 stress 0.1192678
## Run 1 stress 0.1886532
## Run 2 stress 0.1192678
## ... Procrustes: rmse 5.822837e-06 max resid 1.845818e-05
## ... Similar to previous best
## Run 3 stress 0.1192678
## ... Procrustes: rmse 6.697234e-06 max resid 2.061976e-05
## ... Similar to previous best
## Run 4 stress 0.1183186
## ... New best solution
## ... Procrustes: rmse 0.02027078 max resid 0.06496407
## Run 5 stress 0.1192679
## Run 6 stress 0.1939202
## Run 7 stress 0.1808911
## Run 8 stress 0.1183186
## ... New best solution
## ... Procrustes: rmse 1.651369e-06 max resid 5.655239e-06
## ... Similar to previous best
## Run 9 stress 0.1192678
## Run 10 stress 0.1183186
## ... Procrustes: rmse 1.505928e-06 max resid 4.480433e-06
## ... Similar to previous best
## Run 11 stress 0.1192679
## Run 12 stress 0.1192678
## Run 13 stress 0.1886532
## Run 14 stress 0.1183186
## ... New best solution
## ... Procrustes: rmse 1.088269e-06 max resid 3.328672e-06
## ... Similar to previous best
## Run 15 stress 0.1192678
## Run 16 stress 0.1183186
## ... New best solution
## ... Procrustes: rmse 1.797827e-06 max resid 3.862713e-06
## ... Similar to previous best
## Run 17 stress 0.2075713
## Run 18 stress 0.1192678
## Run 19 stress 0.1192679
## Run 20 stress 0.1183186
## ... Procrustes: rmse 6.241246e-06 max resid 1.34356e-05
## ... Similar to previous best
## *** Solution reached获得结果:stress=0.118结果还可以。(虽然指定了autotransform=T,但该套数据并没有触发数据转换)
dune_nmds
##
## Call:
## metaMDS(comm = dune, distance = "bray", k = 2, try = 20, trymax = 50, autotransform = T, noshare = F, model = "global", stress = 1, maxit = 200, parallel = 2)
##
## global Multidimensional Scaling using monoMDS
##
## Data: dune
## Distance: bray
##
## Dimensions: 2
## Stress: 0.1183186
## Stress type 1, weak ties
## Two convergent solutions found after 20 tries
## Scaling: centring, PC rotation, halfchange scaling
## Species: expanded scores based on 'dune'如果做了数据转换,会有类似如下的新:
Square root transformation Wisconsin double standardization … global Multidimensional Scaling using monoMDS
Data: wisconsin(sqrt(varespec))
理想情况下,增加的排序距离等于增加的观测距离,所有的点都落在一条单调递增的线上,越一致越好,偏差大则结果差。Stress值就是下图回归线的残差。
stressplot(dune_nmds)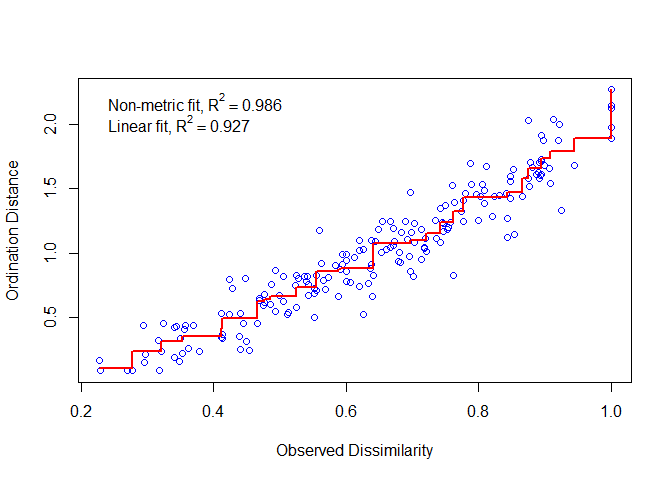
计算每个样品的拟合度,图中圈越小表示拟合度越高。
gof <- goodness(dune_nmds)
plot(dune_nmds, type="t", main = "goodness of fit")
points(dune_nmds, display="sites", cex=gof*100)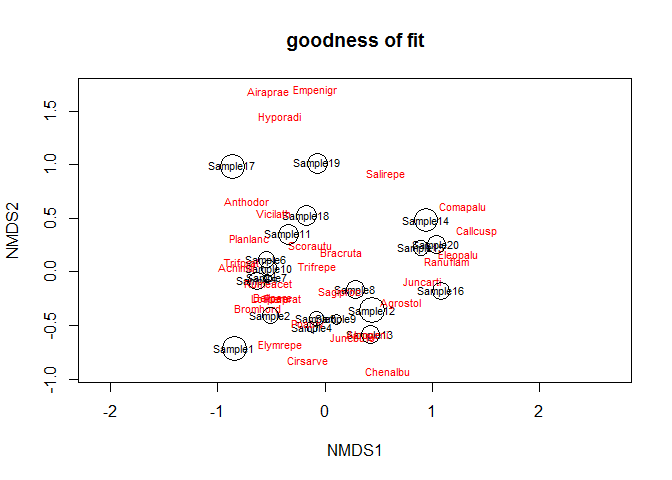
整理数据,绘制NMDS图。
dune_nmds_sample_result <- as.data.frame(scores(dune_nmds))
dune_nmds_sample_result$Sample <- rownames(dune_nmds_sample_result)
dune_nmds_sample_result <- cbind(dune_nmds_sample_result, dune.env)
dune_nmds_sample_result
## NMDS1 NMDS2 Sample A1 Moisture Management Use Manure
## Sample1 -0.84054551 -0.71582776 Sample1 2.8 1 SF Haypastu 4
## Sample2 -0.50485425 -0.40893664 Sample2 3.5 1 BF Haypastu 2
## Sample3 -0.08267021 -0.43667531 Sample3 4.3 2 SF Haypastu 4
## Sample4 -0.11562467 -0.52223859 Sample4 4.2 2 SF Haypastu 4
## Sample5 -0.62654363 -0.08669513 Sample5 6.3 1 HF Hayfield 2
## Sample6 -0.54269773 0.11315559 Sample6 4.3 1 HF Haypastu 2
## Sample7 -0.54030010 -0.05820584 Sample7 2.8 1 HF Pasture 3
## Sample8 0.28115518 -0.16683738 Sample8 4.2 5 HF Pasture 3
## Sample9 0.11057585 -0.44257696 Sample9 3.7 4 HF Hayfield 1
## Sample10 -0.51697230 0.02738090 Sample10 3.3 2 BF Hayfield 1
## Sample11 -0.33831007 0.35081631 Sample11 3.5 1 BF Pasture 1
## Sample12 0.44246800 -0.36410934 Sample12 5.8 4 SF Haypastu 2
## Sample13 0.41863051 -0.58334738 Sample13 6.0 5 SF Haypastu 3
## Sample14 0.94331987 0.47606816 Sample14 9.3 5 NM Pasture 0
## Sample15 0.89599692 0.22235599 Sample15 11.5 5 NM Haypastu 0
## Sample16 1.08109124 -0.17966386 Sample16 5.7 5 SF Pasture 3
## Sample17 -0.85990338 0.98711836 Sample17 4.0 2 NM Hayfield 0
## Sample18 -0.17720324 0.52341328 Sample18 4.6 1 NM Hayfield 0
## Sample19 -0.07001774 1.01213863 Sample19 3.7 5 NM Hayfield 0
## Sample20 1.04240524 0.25266697 Sample20 3.5 5 NM Hayfield 0
# Using the scores function from vegan to extract the species scores
# and convert to a data.frame
dune_nmds_species_result <- as.data.frame(scores(dune_nmds, "species"))
dune_nmds_species_result$Species <- rownames(dune_nmds_species_result)
dune_nmds_species_result
## NMDS1 NMDS2 Species
## Achimill -0.82280076 0.04328704 Achimill
## Agrostol 0.71096003 -0.28924414 Agrostol
## Airaprae -0.52817837 1.67987383 Airaprae
## Alopgeni 0.39096747 -0.58596256 Alopgeni
## Anthodor -0.72021737 0.65914560 Anthodor
## Bellpere -0.47838087 -0.24446722 Bellpere
## Bromhord -0.61896693 -0.33475908 Bromhord
## Chenalbu 0.59187098 -0.92197922 Chenalbu
## Cirsarve -0.15184056 -0.82169646 Cirsarve
## Comapalu 1.28932838 0.60840015 Comapalu
## Eleopalu 1.24504861 0.16149275 Eleopalu
## Elymrepe -0.42014574 -0.68023468 Elymrepe
## Empenigr -0.08835329 1.69629767 Empenigr
## Hyporadi -0.41569548 1.44600334 Hyporadi
## Juncarti 0.91146010 -0.08309672 Juncarti
## Juncbufo 0.26476745 -0.60761447 Juncbufo
## Lolipere -0.51199146 -0.24807077 Lolipere
## Planlanc -0.70645212 0.32063694 Planlanc
## Poaprat -0.38844035 -0.25091394 Poaprat
## Poatriv -0.15906762 -0.47836751 Poatriv
## Ranuflam 1.14363918 0.09953894 Ranuflam
## Rumeacet -0.52479268 -0.10530738 Rumeacet
## Sagiproc 0.14315579 -0.18745689 Sagiproc
## Salirepe 0.57484082 0.91104875 Salirepe
## Scorautu -0.13956707 0.25000522 Scorautu
## Trifprat -0.77154453 0.08564591 Trifprat
## Trifrepe -0.07526697 0.04516674 Trifrepe
## Vicilath -0.46793995 0.54914931 Vicilath
## Bracruta 0.15071778 0.18979787 Bracruta
## Callcusp 1.42118155 0.38376646 CallcuspNMDS是一种散点图,图形中每个点通常代表样本,不同颜色/形状等代表样本所属的分组信息或其它关注的样本属性信息。同组内样品点距离远近说明了样本的重复性强弱,组间样本的远近则反应了组间样本在检测变量空间上的差异。通常需要标记stress信息,不标记轴的权重信息。
library(ggplot2)
library(ggalt)
p1 <- ggplot(data=dune_nmds_sample_result,
aes(x=NMDS1,y=NMDS2,fill=Management,
colour=Management,group=Management)) +
geom_point(size=3) + # add the point markers
geom_encircle(alpha=0.1, show.legend = F) +
geom_hline(aes(yintercept=0),color="grey", linetype=3) +
geom_vline(aes(xintercept=0),color="grey", linetype=3) +
labs(title=paste0("Stress: ", round(dune_nmds$stress,3))) +
theme_classic()
p1
在NMDS二维空间同时绘制物种信息(物种较多时一团乱,可以筛选部分高峰度物种,再筛选dune_nmds_species_result进行绘制。或者也可以直接绘制物种信息。
p1 <- ggplot() +
geom_point(data=dune_nmds_sample_result,
aes(x=NMDS1,y=NMDS2,
colour=Management,group=Management),size=3) + # add the point markers
geom_encircle(data=dune_nmds_sample_result,
aes(x=NMDS1,y=NMDS2,fill=Management,group=Management),
alpha=0.1, show.legend = F) +
geom_hline(aes(yintercept=0),color="grey", linetype=3) +
geom_vline(aes(xintercept=0),color="grey", linetype=3) +
geom_point(data=dune_nmds_species_result, aes(x=NMDS1,y=NMDS2)) +
geom_text(data=dune_nmds_species_result, aes(x=NMDS1,y=NMDS2,label=Species)) +
labs(title=paste0("Stress: ", round(dune_nmds$stress,3))) +
theme_classic()
p1
参考
NMDS https://archetypalecology.wordpress.com/2018/02/18/non-metric-multidimensional-scaling-nmds-what-how/
NMDS https://blog.csdn.net/weixin_53819139/article/details/114133818
https://www.cd-genomics.com/microbioseq/non-metric-multidimensional-scaling-nmds-in-microbial-sequencing-data-analysis-introduction-application-and-comparison.html
很好的排序概念解释 http://albertsenlab.org/ampvis2-ordination/
https://blog.csdn.net/woodcorpse/article/details/107032032?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~aggregatepage~first_rank_ecpm_v1~rank_aggregation-4-107032032.pc_agg_rank_aggregation&utm_term=beta%E5%A4%9A%E6%A0%B7%E6%80%A7&spm=1000.2123.3001.4430
https://mb3is.megx.net/gustame/dissimilarity-based-methods/nmds
https://jkzorz.github.io/2019/06/06/NMDS.html
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集
