大数据文摘
大数据文摘






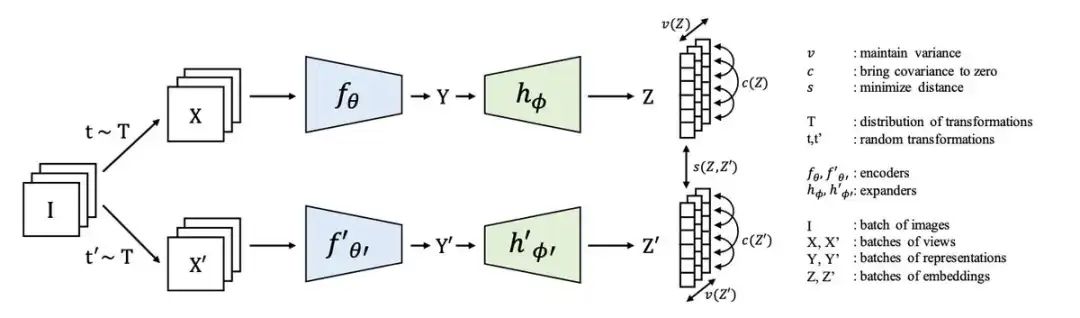
图注:基于能量的模型:“VICREG”是“自监督学习的方差-不变性-协方差重新正则化(Variance-Invariance-Covariance Re-Gularization For Self-Supervised Learning)”的缩写,是LeCun在基于能量的神经网络架构上的最新研究成果。一组图像在两个不同的管道中转换,每个扭曲后的图像会被发送到编码器,该编码器实质上是对图像进行压缩。然后,投影仪(也被称为“扩展器”)会将这些压缩的表示解压成最终的“嵌入”,即 Z 维。正因为这两种嵌入之间的相似性不受其扭曲的影响,程序才能够找到合适的低能量级别去识别出某些东西。(图源:FAIR)