
MySQL千万数据方案调研,一不小心直接打挂我系统
大家好,我是Leo。
之前聊的RocketMQ暂时放放,目前正在调研一个千万数据的处理方案。
在准备测试数据的时候,执行了个 select 把我电脑内存打光了。然后OOM,黑屏,宕机。。

基础知识系列
大厂面试系列
本章概括
对Server影响
当执行下列代码时,因为InnoDB的数据是保存在主键索引上的,所以全表扫描是直接查主键索引的数据。他会从第一行一直查到最后一行放入结果集,然后返回给客户端。
select * from waybill
这个结果集是啥,为什么会导致我OOM?
先看一下Server层的查询流程
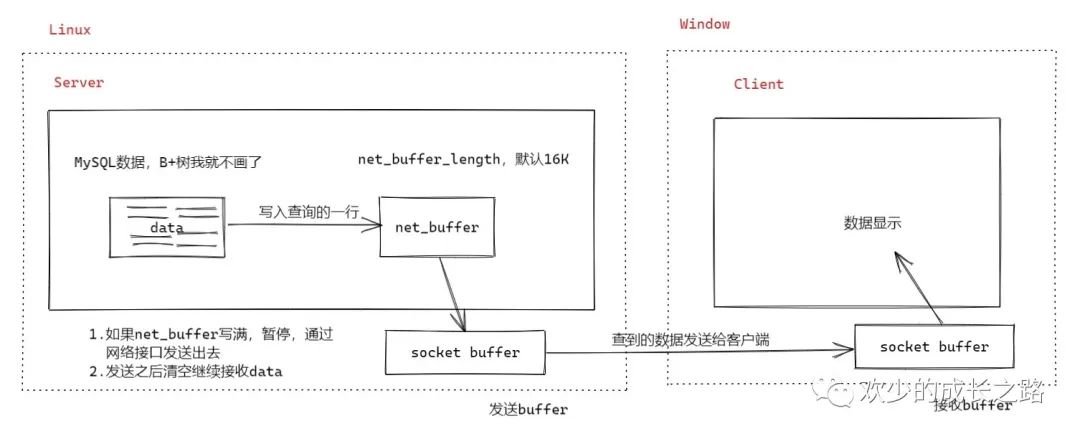
获取一行数据,把数据写入 net_buffer直至到最后一行,如果 net_buffer满了,就会调用网络接口把数据发送给Client端发送成功之后,清空 net_buffer继续接收如果发送失败,返回 EAGAIN或WSAEWOULDBLOCK,就表示本地网络栈socket buffer写满了,进入等待。直到网络栈重新可写,再继续发送
socket buffer 属于操作系统层,他是操作系统提供的socket缓冲区。缓冲区默认大小为8K(1024×8=8192字节),也可以设置成64K。
使用socket发送数据时先把数据发送到socket缓冲区中,之后接收函数从缓冲区中读取数据,如果发送端特别快的时候,缓冲区很快就被填满,我们可以根据情况设置缓冲区的大小,通过setsockopt函数实现
从流程可以得知 MySQL是边读边发的
占用最大的就是 net_buffer ,而且 net_buffer 的上限会控制在8K,为什么还会出现 OOM ?
一开始执行的时候这类知识我是知道的,但是我忽略了一个问题,日常使用时,我们会把数据库放在云服务器或者RDS中,今天为了测试千万数据我就直接在本地测了。
这就直接导致,服务器一直把数据返给客户端。都在本地,一不留神,悲剧了

强调一点! 对Server层来说,查询的结果是分段发给客户端的,所以Server不会把内存打爆。问题自然出在客户端了。
对InnoDB影响
大数据量查询时,InnoDB 内存的数据页是在 Buffer Pool(BP) 中管理的。主要起到了加速更新的作用。实际上 Buffer Pool 还有一个更重要的作用就是加速查询。
这个加速查询还依赖一个重要的指标 内存命中率
可以通过 show engine innodb status 命令查看,或者通过百度搜索 MySQL内存命令率查询
如果所有的查询都能在内存页中找到答案,那命中率肯定是 100% 。但是在生产环境上业务是比较复杂的,这个很难做到。
InnoDB Buffer Pool 的大小是由参数 innodb_buffer_pool_size 确定的,一般建议设置成可用物理内存的 60%~80%。
InnoDB Buffer Pool innodb的缓冲池
innodb_buffer_pool_size innodb缓冲池大小的配置项
在查询时,如果 Buffer Pool 满了,而又要从磁盘读入一个数据页时,它会淘汰一个数据页进行存放新的数据页。淘汰的依据就是 LRU 算法
LRU 最近最少使用算法,淘汰最久未使用的数据。
可以参考如下图,是一个LRU基本模型,它是使用链表实现的。
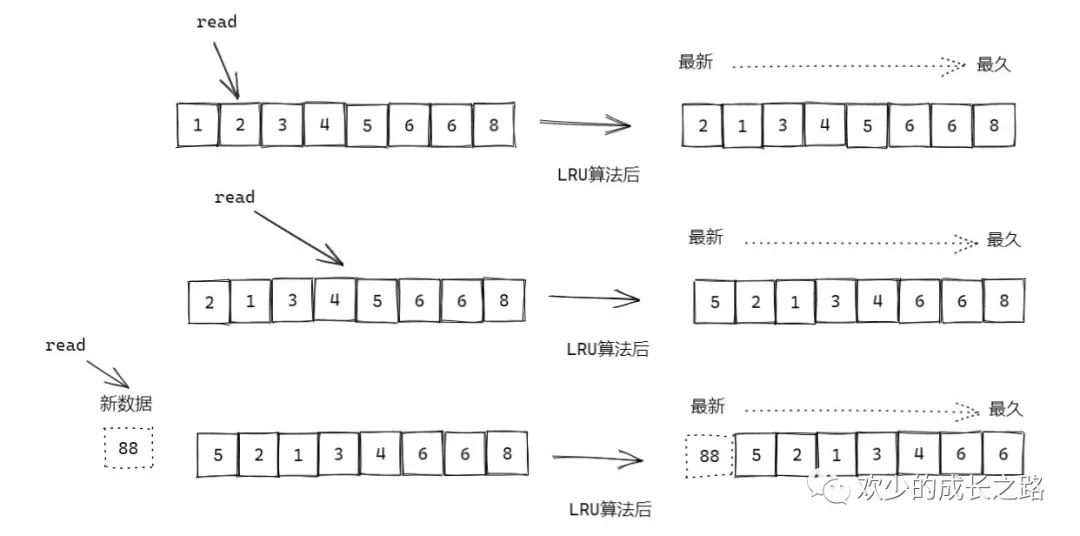
第一张图是读取数据2时,会把2放入链表的头部,然后其他数据依次向后移动 第二张图同感 第三张图是读取了链表上没有的数据,就会把当前最久未使用的数据移出,把头部的最新数据写入。
是不是觉得设计的很奇妙?我也觉得这个思想好奇妙,但是对于当前场景不实用!
大数据量写入之后,他会不断把链表的数据不断替换,也就是不断淘汰,最终导致内存命中率急剧下降,磁盘压力增加,SQL语句响应变慢。
在LRU的基础上InnoDB做了一些优化!
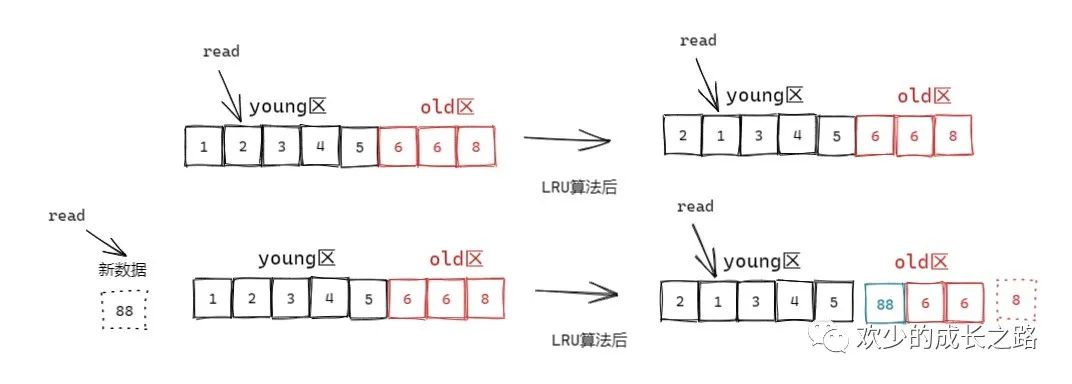
第一张图就是大概按照5:3的比例,把链表分成了 young区和old区。访问2时,会把2提到最前面,其他数据依靠靠后一格第二张图是写入一个新数据88时,他会把old区域的最后一个数8移出,然后把新数据88写入old区的第一个位置
处于 old 区域的数据页,每次被访问的时候都要做下面这个判断:
若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部; 如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。
这个策略,就是为了处理类似全表扫描的操作量身定制的。我们可以看一下全表查询的逻辑
扫描过程中,需要新插入的数据页,都被放到 old 区域 ; 一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在 old 区域; 再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),很快就会被淘汰出去。
可以看到,这个策略最大的收益,就是在扫描这个大表的过程中,虽然也用到了 Buffer Pool,但是对 young 区域完全没有影响,从而保证了 Buffer Pool 响应正常业务的查询命中率。
对我的影响
知道了原理之后,再进行实现下一步方案的时候就类似于搭积木一样。
万丈高楼平地起,地基不搭好,上面再豪华,轻轻一晃就倒了
结尾
有些不懂的地方或者不对的地方,麻烦各位指出,一定修改优化!
非常欢迎大家加我个人微信有关后端方面的问题我们在群内一起讨论! 我们下期再见!
长按上方扫码二维码,加我微信,拉你进群
