 Python大数据分析
Python大数据分析




【玩转dash】公众号后台回复关键词【核酸检测】获取本期全部源码
这段时间以来,上海疫情的严峻形势一直牵动着大家的心,在这场没有硝烟的战争中很多人都在做出自己的贡献,前两天我就在新闻中就看到这样一条内容:

文中提到了这位复旦大学的博士生为了方便统计同学们的“健康云”核酸检测结果,使用到ocr和正则表达式等通用技术来实现批量数据录入,这本是一件利用通用技术手段解决日常小需求的正面案例,但可能因为媒体的夸张宣传,变味成了某些知道这一套流程技术门槛较低的人的眼中,用来“冷嘲热讽”的对象。
不过这些都不是本文要讨论的重点,我在看到这篇新闻后思考的是如何让这类工具更加实用易用,那么最好的形式就是将其开发为一个网页应用,通过局域网或云服务器部署后,使得更多人可以仅仅通过浏览器,就能直接访问使用其功能,而无需在各自的电脑上单独繁琐地配置环境。
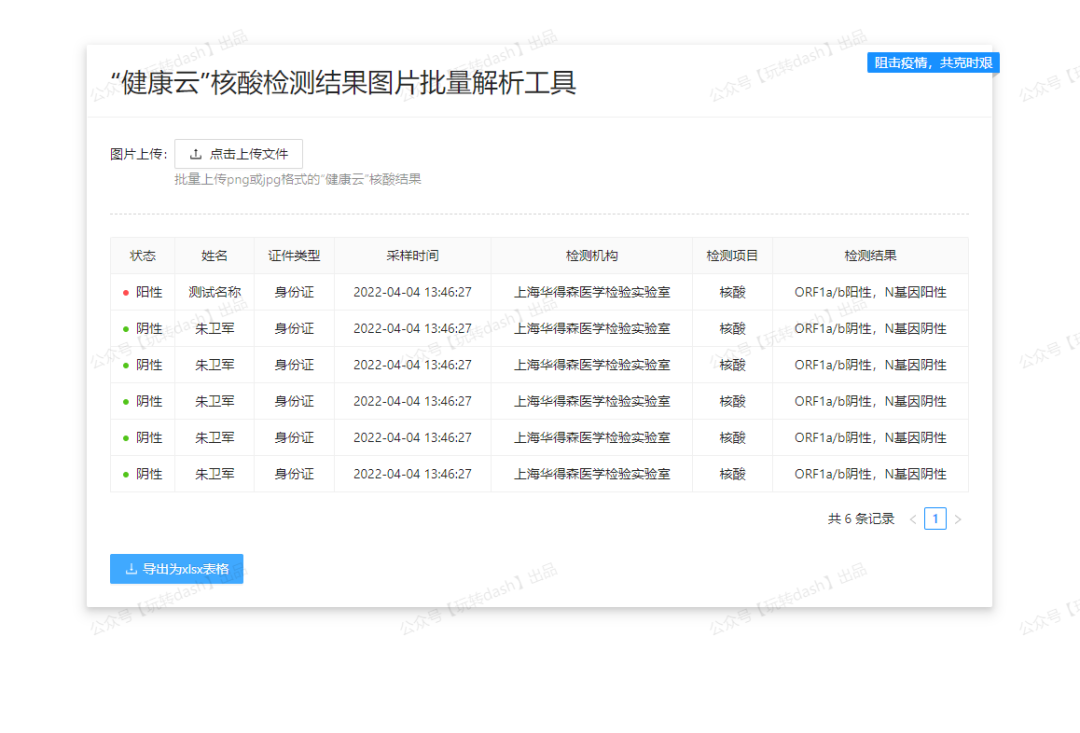
而今天的文章,费老师我就来带大家学习如何仅用Python来快速实现一个界面清新交互友好的“核酸检测结果批量解析工具”(感谢身在上海的军哥提供的“健康云”阴性结果页图片示例🌹)。
使用效果如下面的视频所示:
而要完成这样一款网页应用的开发,过程非常简单,主要使用到Dash、paddleocr以及由我开源的feffery-antd-components等框架,下面我们分步骤介绍具体开发过程:
1 环境搭建
首先为了在作为服务器的设备上运行该应用,建议大家使用虚拟环境来安装相关依赖,以conda和windows系统为例,可分为以下步骤:
创建虚拟环境
conda create -n ocr_app python=3.8 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ -y
conda activate ocr_app
安装 paddleocr相关依赖
本文演示使用的是paddleocr的CPU版本,你也可以自行前往其官方文档进行GPU版本的安装,从而获得显著地运算速度提升:
python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
conda install python-Levenshtein -c https://mirrors.sjtug.sjtu.edu.cn/anaconda/pkgs/main -y
pip install "paddleocr>=2.0.1" -i https://mirror.baidu.com/pypi/simple
准备 Dash+fac开发套件
最后就是准备我们最重要的网页应用开发环境了,注意这里一定要安装版本大于等于0.1.7的feffery-antd-components:
pip install dash -i https://pypi.douban.com/simple/
pip install feffery-antd-components==0.1.7
全部执行完成后我们的应用运行环境就准备好了~
2 ocr功能的实现
我们选择使用paddleocr来快速完成图片文字识别提取工作,过程很简单只有几行代码,你可以在本文源码(【玩转dash】公众号后台回复【核酸检测】获取全部源码)中的utils.py中的OcrModel类查看具体逻辑,其中初始化模型时使用到的enable_mkldnn等参数都是为了加速我们CPU版本的paddleocr:
class OcrModel:
def __init__(self):
self.ocr_model = PaddleOCR(lang="ch", enable_mkldnn=True, use_tensorrt=True, use_angle_cls=False)
...
3 网页搭建
在ocr功能的基础上,利用dash以及由我开源的fac框架(官网:http://fac.feffery.tech/)开发网页功能界面就非常简单了。
主要逻辑是用户点击上传按钮后可通过多选、全选的方式批量上传图片文件,在接受到用户上传的文件后,我们的dash应用会在回调函数中调用utils.py中的功能实现图片文字内容解析,最后将计算得到的表格结果、导出下载按钮以及埋设好的下载功能返回到网页供用户浏览和导出excel表格结果:
GPU版本。以上就是本文的全部内容,欢迎在【玩转dash】公众号后台回复【进群】加入交流群参与更多讨论。
更多Dash应用开发专业教程内容
欢迎加入我的知识星球【玩转dash】



