
特征工程:基于梯度提升的模型的特征编码效果测试
共 8888字,需浏览 18分钟
· 2022-04-10

来源:DeepHub IMBA 本文4300字,建议阅读8分钟
展示梯度提升模型下表格数据中的数字和分类特征的各种编码策略之间的基准测试研究的结果。
梯度提升
特征编码
数字特征
分类特征
基准基准
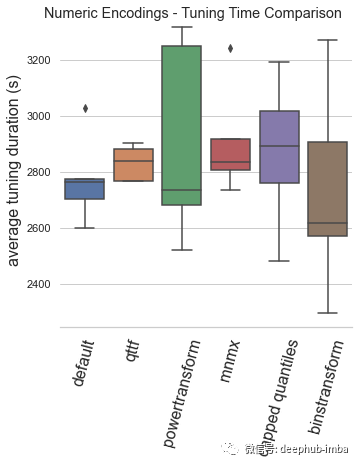
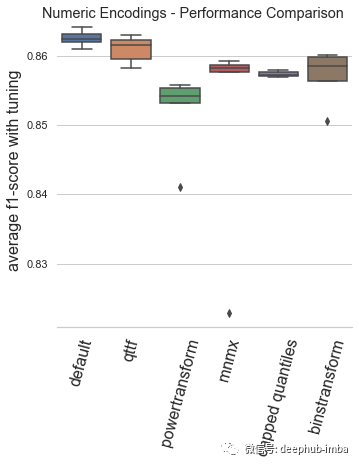
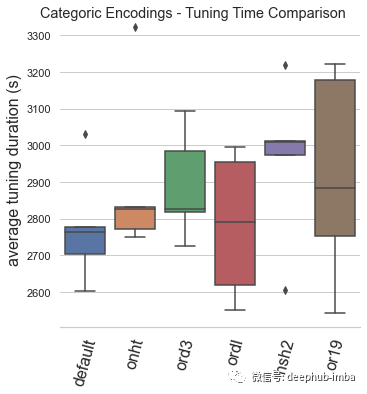
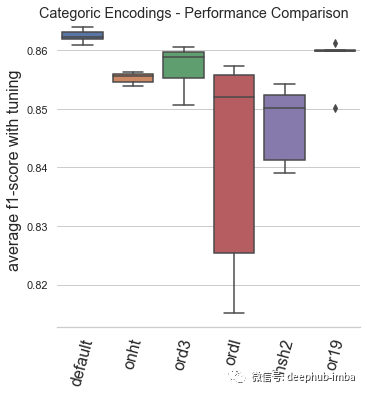
总结
基准测试包括以下表格数据集,此处显示了它们的 OpenML ID 号:
Click prediction / 233146
C.C.FraudD. / 233143
sylvine / 233135
jasmine / 233134
fabert / 233133
APSFailure / 233130
MiniBooNE / 233126
volkert / 233124
jannis / 233123
numerai28.6 / 233120
Jungle-Chess-2pcs / 233119
segment / 233117
car / 233116
Australian / 233115
higgs / 233114
shuttle / 233113
connect-4 / 233112
bank-marketing / 233110
blood-transfusion / 233109
nomao / 233107
ldpa / 233106
skin-segmentation / 233104
phoneme / 233103
walking-activity / 233102
adult / 233099
kc1 / 233096
vehicle / 233094
credit-g / 233088
mfeat-factors / 233093
arrhythmia / 233092
kr-vs-kp / 233091
Akiba, T., Sano, S., Yanase, T., Ohta, T., and Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In KDD. (2019). URL https://optuna.org/#paper.
Box, G. E. P., and Cox, D. R. An analysis of transformations. Journal of the Royal Statistical Society: Series B (Methodological), 26(2):211–243, (1964). https://www.jstor.org/stable/2984418.
Breiman, L. Random Forests. Machine Learning 45, 5–32 (2001). https://doi.org/10.1023/A:1010933404324.
Chen, T. and Guestrin, C., XGBoost: A Scalable Tree Boosting System. (2016). https://arxiv.org/abs/1603.02754.
Elsayed, S., Thyssens, D., Rashed, A., Samer Jomaa, H., and Schmidt-Thieme, L., Do We Really Need Deep Learning Models for Time Series Forecasting? (2021). https://arxiv.org/abs/2101.02118.
Friedman, J. H. Greedy function approximation: A gradient boosting machine. The Annals of Statistics, 29(5) 1189–1232 (October 2001). https://doi.org/10.1214/aos/1013203451.
Goodfellow, I. J., Bengio, Y., and Courville, A. *Deep Learning*. MIT Press, Cambridge, MA, USA, (2016). http://www.deeplearningbook.org.
Gorishniy, Y., Rubachev, I., Khrulkov, V., and Babenko, A., Revisiting Deep Learning Models for Tabular Data. Advances in Neural Information Processing Systems, volume 30.
Curran Associates, Inc. (2021). URL https://openreview.net/forum?id=i_Q1yrOegLY.
Howard, J. and Gugger, S. *Deep Learning for Coders with fastai and PyTorch*. O’Reilly Media, 2020. https://www.oreilly.com/library/view/deep-learning-for/9781492045519/.
Jain, A. Complete Guide to Parameter Tuning in XGBoost with codes in Python. Analytics Vidhya (2016). https://www.analyticsvidhya.com/blog/2016/03/complete-guide-parameter-tuning-xgboost-with-codes-python/.
Kadra, A., Lindauer, M., Hutter, F., and Grabocka, J. Well-tuned simple nets excel on tabular datasets. In Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=d3k38LTDCyO.
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., and Liu, T. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc. (2020). URL https://proceedings.neurips.cc/paper/2017/file/6449f44a102fde848669bdd9eb6b76fa-Paper.pdf.
London, I. Encoding cyclical continuous features — 24-hour time. (2016) URL https://ianlondon.github.io/blog/encoding-cyclical-features-24hour-time/
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M.,
Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E., Scikit-learn: Machine Learning in Python, JMLR 12, pp. 2825–2830, (2011). https://www.jmlr.org/papers/v12/pedregosa11a.html.
Quinlan, J. R. Induction of Decision Trees. Mach. Learn. 1, 1, 81–106 (March 1986). https://doi.org/10.1023/A:1022643204877.
Ravi, Rakesh. One-Hot Encoding is making your Tree-Based Ensembles worse, here’s why? Towards Data Science, (January 2019). https://towardsdatascience.com/one-hot-encoding-is-making-your-tree-based-ensembles-worse-heres-why-d64b282b5769.
Stevens, E., Antiga, L., Viehmann, T. *Deep Learning with PyTorch*. Manning Publications, (2020). https://www.manning.com/books/deep-learning-with-pytorch.
Swersky, K. and Snoek, J. and Adams, R. P., Multi-Task Bayesian Optimization. Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc. (2013). URL https://proceedings.neurips.cc/paper/2013/file/f33ba15effa5c10e873bf3842afb46a6-Paper.pdf.
Teague, N. Automunge code repository, documentation, and tutorials, (2022). URL https://github.com/Automunge/AutoMunge.
Teague, N. Custom Transformations with Automunge. (2021). URL https://medium.com/automunge/custom-transformations-with-automunge-ae694c635a7e
Teague, N. Hashed Categoric Encodings with Automunge (2020a) https://medium.com/automunge/hashed-categoric-encodings-with-automunge-92c0c4b7668c.
Teague, N. Parsed Categoric Encodings with Automunge. (2020b) https://medium.com/automunge/string-theory-acbd208eb8ca.
Vanschoren, J., van Rijn, J. N., Bischl, B., and Torgo, L. OpenML: networked science in machine learning. SIGKDD Explorations 15(2), pp 49–60, (2013). https://arxiv.org/abs/1407.7722