
计算密集型服务 性能优化实战始末
背景
项目背景
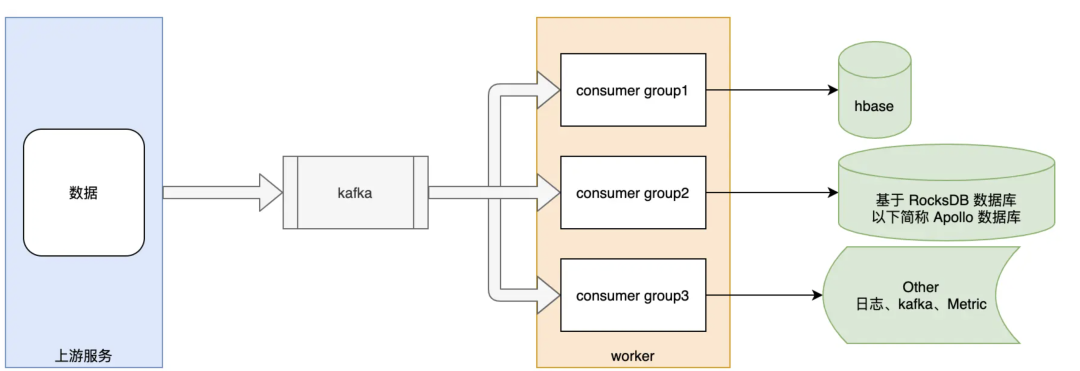
worker 服务数据链路图
worker 服务消费上游数据(工作日高峰期产出速度达近 200 MB/s,节假日高峰期可达 300MB/s 以上),进行中间处理后,写入多个下游。在实践中结合业务场景,基于快慢隔离的思想,以三个不同的 consumer group 消费同一 Topic,隔离三种数据处理链路。
面对问题
worker 服务在高峰期时 CPU Idle 会降至 60%,因其属于数据处理类计算密集型服务,CPU Idle 过低会使服务吞吐降低,在数据处理上产生较大延时,且受限于 Kafka 分区数,无法进行横向扩容; 对上游数据的采样率达 **30%**,业务方对数据的完整性有较大诉求,但系统 CPU 存在瓶颈,无法满足;
性能优化
针对以上问题,开始着手对服务 CPU Idle 进行优化;抓取服务 pprof profile 图如下:go tool pprof -http=:6061 http://「ip:port」/debug/pprof/profile
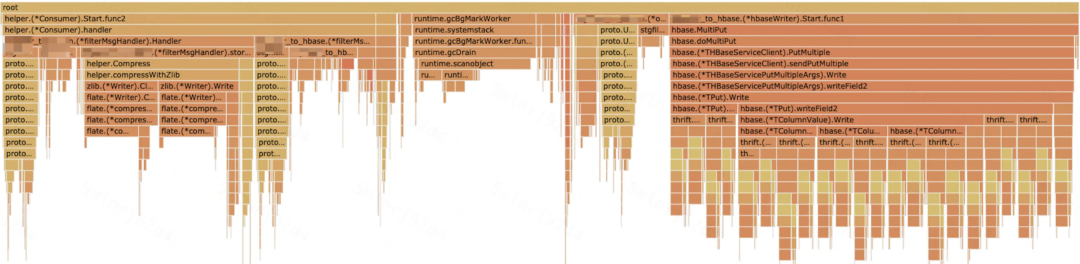
优化前的 pprof profile 图
服务与存储之间置换压力
背景
worker 服务消费到上游数据后,会先写全部写入 Apollo 的数据库,之后每分钟定时捞取处理,但消息体大小 P99 分位达近 1.5M,对于 Apollo 有较严重的大 Key 问题,再结合 RocksDB 特有的写放大问题,会进一步加剧存储压力。在这个背景下,我们采用 zlib 压缩算法,对消息体先进行压缩后再写入 Apollo,减缓读写大 Key 对 Apollo 的压力。
优化
在 CPU 的优化过程中,我们发现服务在压缩操作上占用了较多的 CPU,于是对压缩等级进行调整,以减小压缩率、增大下游存储压力为代价,减少压缩操作对服务 CPU 的占用,提升服务 CPU 。这一操作本质上是在服务与存储之间进行压力置换,是一种空间换时间的做法。
关于压缩等级
这里需要特别注意的是,在压缩等级的设置上可能存在较为严重的边际效用递减问题。在进行基准测试时发现,将压缩等级由 BestCompression 调整为 DefaultCompression 后,压缩率只有近 1‱ 的下降,但压缩方面的 CPU 占用却相对提高近 **50%**。此结论不能适用于所有场景,需从实际情况出发,但在使用时应注意这个问题,选择相对最优的压缩方式。
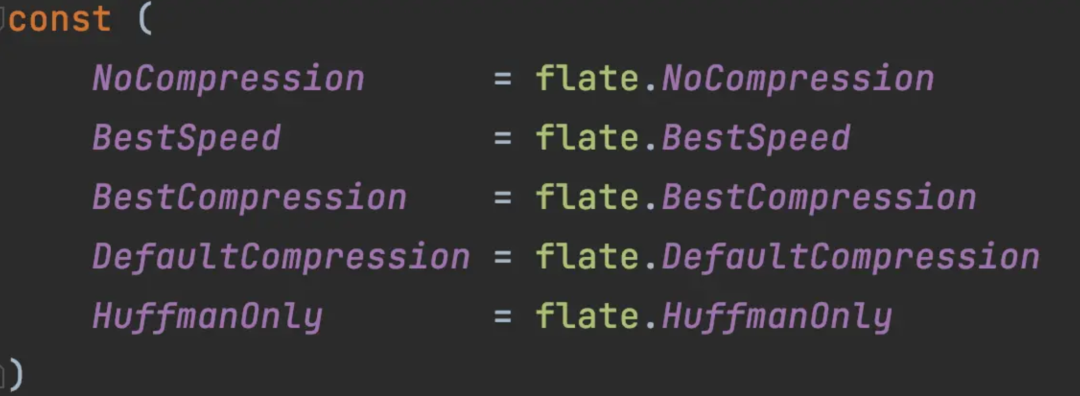
zlib 可设置的压缩等级
使用更高效的序列化库
背景
worker 服务在设计之初基于快慢隔离的思想,使用三个不同的 consumer group 进行分开消费,导致对同一份数据会重复消费三次,而上游产出的数据是在 PB 序列化之后写入 Kafka,消费侧亦需要进行 PB 反序列化方能使用,因此导致了 PB 反序列化操作在 CPU 上的较大开销。
优化
经过探讨和调研后发现,gogo/protobuf 三方库相较于原生的 golang/protobuf 库性能更好,在 CPU 上占用更低,速度更快,因此采用 gogo/protobuf 库替换掉原生的 golang/protobuf 库。
gogo/protobuf 为什么快
通过对每一个字段都生成代码的方式,取消了对反射的使用; 采用预计算方式,在序列化时能够减少内存分配次数,进而减少了内存分配带来的系统调用、锁和 GC 等代价。
用过去或未来换现在的时间:页面静态化、池化技术、预编译、代码生成等都是提前做一些事情,用过去的时间,来降低用户在线服务的响应时间;另外对于一些在线服务非必须的计算、存储的耗时操作,也可以异步化延后进行处理,这就是用未来的时间换现在的时间。出处:https://mp.weixin.qq.com/s/S8KVnG0NZDrylenIwSCq8g
关于序列化库
这里只列举的了 PB 序列化库的优化 Case,但在 JSON 序列化方面也存在一样的优化手段,如 json-iterator、sonic、gjson 等等,我们在 Feature 服务中先后采用了 json-iterator 与 gjson 库替换原有的标准库 JSON 序列化方式,均取得了显著效果。JSON 库调研报告:https://segmentfault.com/a/1190000041591284
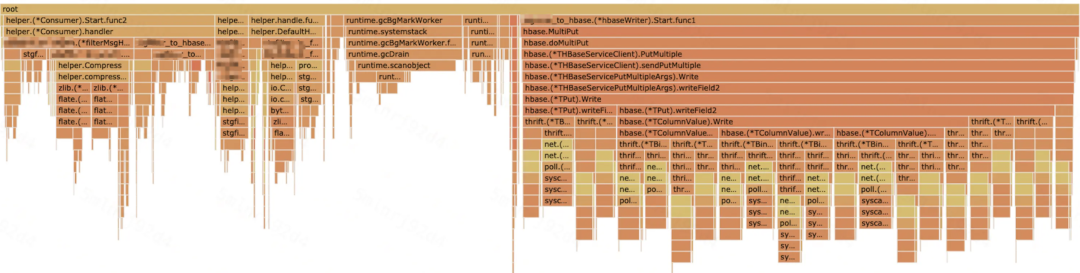
调整压缩等级与更换 PB 序列化库之后
数据攒批 减少调用
背景
在观察 pprof 图后发现写 hbase 占用了近 50% 的相对 CPU,经过进一步分析后,发现每次在序列化一个字段时 Thrift 都会调用一次 socket->syscall,带来频繁的上下文切换开销。
优化
阅读代码后发现, 原代码中使用了 Thrift 的 TTransport 实现,其功能是包装 TSocket,裸调 Syscall,每次 Write 时都会调用 socket 写入进而调用 Syscall。这与通常我们的编码习惯不符,认为应该有一个 buffer 充当中间层进行数据攒批,当 buffer 写完或者写满后再向下层写入。于是进一步阅读 Thrift 源码,发现其中有多种 Transport 实现,而 TTBufferedTransport 是符合我们编码习惯的。
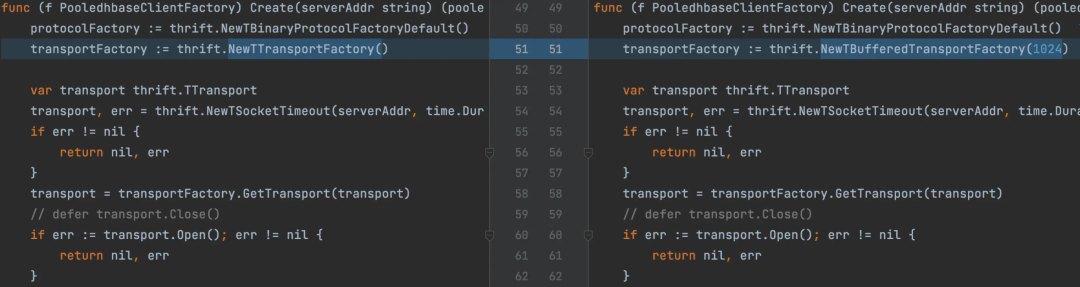
对 Thrift 调用进行优化,使用带 buffer 的 transport,大大减少对 Syscall的调用
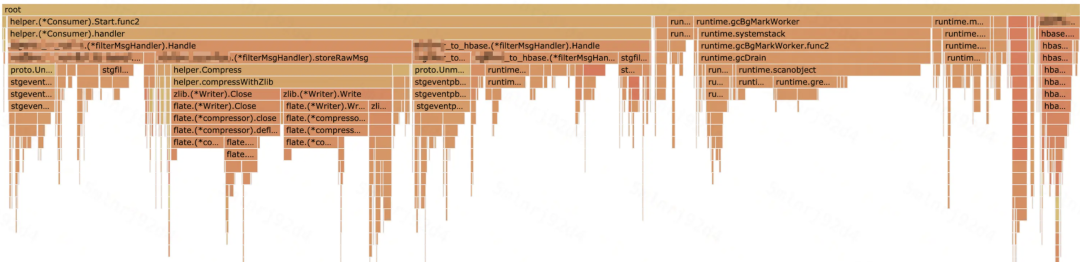
更换 transport 之后,对 HBase 的调用消耗只剩最右侧的一条了
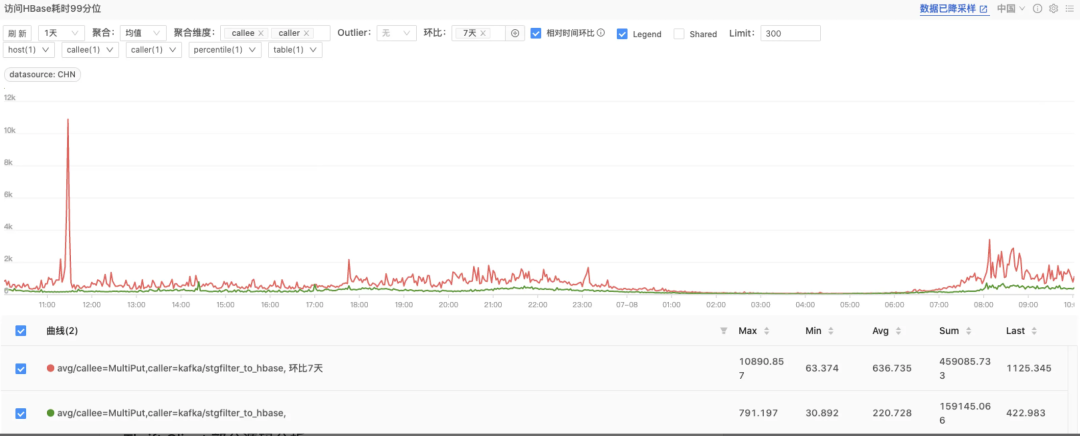
对 HBase 的访问耗时大幅下降
Thrift Client 部分源码分析
Transport 使用了装饰器模式
| Transport 实现 | 作用 |
|---|---|
| TTransport | 包装 TSocket,裸调 Syscall,每次 Write 都会调用 syscall; |
| TTBufferedTransport | 需要提前声明 buffer 的大小,在调用 Socket 之前加了一层 buffer,写满或者写完之后再调用 Syscall; |
| TFramedTransport | 与 TTBufferedTransport 类似,但只会在全部写入 buffer 后,再调用 Syscall。数据格式为:size+content,客户端与服务端必须都使用该实现,否则会因为格式不兼容报错; |
| streamTransport | 传入自己实现的 IO 接口; |
| TMemoryBufferTransport | 纯内存交换,不与网络交互; |
| Protocol 实现 | 作用 |
|---|---|
| TBinaryProtocol | 直接的二进制格式; |
| TCompactProtocol | 紧凑型、高效和压缩的二进制格式; |
| TJSONProtocol | JSON 格式; |
| TSimpleJSONProtocol | SimpleJSON 产生的输出适用于 AJAX 或脚本语言,它不保留Thrift的字段标签,不能被 Thrift 读回,它不应该与全功能的 TJSONProtocol 相混淆;https://cwiki.apache.org/confluence/display/THRIFT/ThriftUsageJava |
关于数据攒批
数据攒批:将数据先写入用户态内存中,而后统一调用 syscall 进行写入,常用在数据落盘、网络传输中,可降低系统调用次数、利用磁盘顺序写特性等,是一种空间换时间的做法。有时也会牺牲一定的数据实时性,如 kafka producer 侧。相似优化可见:https://mp.weixin.qq.com/s/ntNGz6mjlWE7gb_ZBc5YeA
语法调整
除在对库的使用上进行优化外,在 GO 语言本身的使用上也存在一些优化方式;
slice、map 预初始化,减少频繁扩容导致的内存拷贝与分配开销; 字符串连接使用 strings.builder(预初始化) 代替 fmt.Sprintf();
func ConcatString(sl ...string) string {
n := 0
for i := 0; i < len(sl); i++ {
n += len(sl[i])
}
var b strings.Builder
b.Grow(n)
for _, v := range sl {
b.WriteString(v)
}
return b.String()
}
buffer 修改返回 string([]byte) 操作为 []byte,减少内存 []byte -> string 的内存拷贝开销;
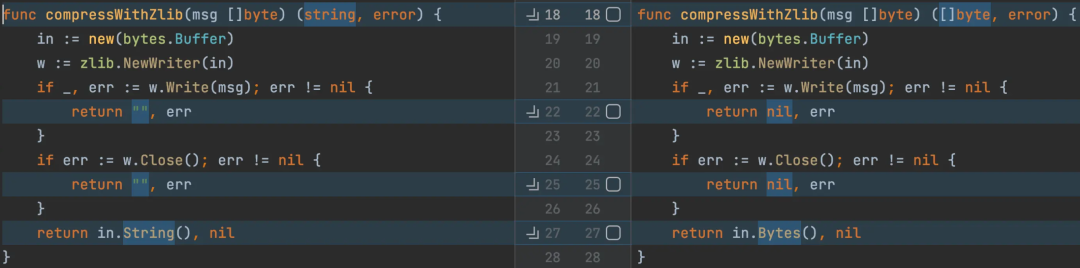
string <-> []byte 的另一种优化,需确保 []byte 内容后续不会被修改,否则会发生 panic;
func String2Bytes(s string) []byte {
sh := (*reflect.StringHeader)(unsafe.Pointer(&s))
bh := reflect.SliceHeader{
Data: sh.Data,
Len: sh.Len,
Cap: sh.Len,
}
return *(*[]byte)(unsafe.Pointer(&bh))
}
func Bytes2String(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
关于语法调整
更多语法调整,见以下文章
https://www.bacancytechnology.com/blog/golang-performance https://mp.weixin.qq.com/s/Lv2XTD-SPnxT2vnPNeREbg
GC 调优
背景
在上次优化完成之后,系统已经基本稳定,CPU Idle 高峰期也可以维持在 80% 左右,但后续因业务诉求对上游数据采样率调整至 100%,CPU.Idle 高峰期指标再次下降至近 70%,且由于定时任务的问题,存在 CPU.Idle 掉 0 风险;
优化
经过对 pprof 的再次分析,发现 runtime.gcMarkWorker 占用不合常理,达到近 30%,于是开始着手对 GC 进行优化;
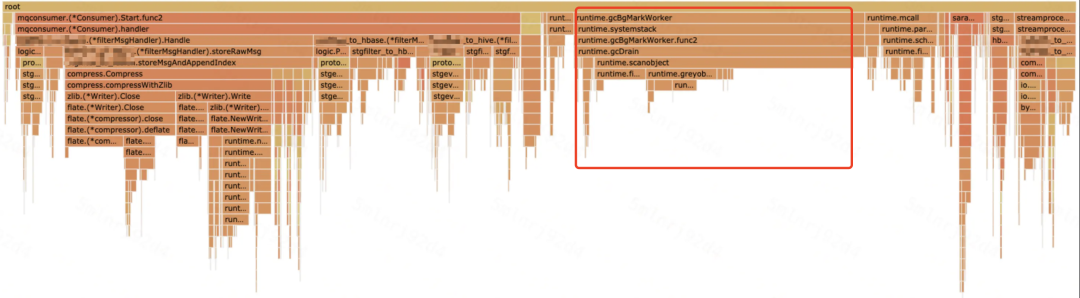
GC 优化前 pprof 图
方法一:使用 sync.pool()
通常来说使用 sync.pool() 缓存对象,减少对象分配数,是优化 GC 的最佳方式,因此我们在项目中使用其对 bytes.buffer 对象进行缓存复用,意图减少 GC 开销,但实际上线后 CPU Idle 却略微下降,且 GC 问题并无缓解。原因有二:
sync.pool 是全局对象,读写存在竞争问题,因此在这方面会消耗一定的 CPU,但之所以通常用它优化后 CPU 会有提升,是因为它的对象复用功能对 GC 带来的优化,因此 sync.pool 的优化效果取决于锁竞争增加的 CPU 消耗与优化 GC 减少的 CPU 消耗这两者的差值; GC 压力的大小通常取决于 inuse_objects,与 inuse_heap 无关,也就是说与正在使用的对象数有关,与正在使用的堆大小无关;
本次优化时选择对 bytes.buffer 进行复用,是想做到减少堆大小的分配,出发点错了,对 GC 问题的理解有误,对 GC 的优化因从 pprof heap 图 inuse_objects 与 alloc_objects 两个指标出发。

甚至没有依赖经验, 只是单纯的想当然了🤦♂️
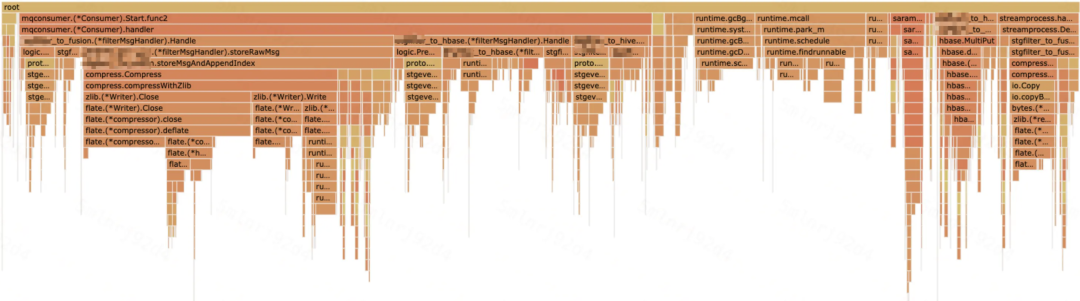
方法二:设置 GOGC
原理:GOGC 默认值是 100,也就是下次 GC 触发的 heap 的大小是这次 GC 之后的 heap 的一倍,通过调大 GOGC 值(gcpercent)的方式,达到减少 GC 次数的目的;
公式:gc_trigger = heap_marked * (1+gcpercent/100) gcpercent:通过 GOGC 来设置,默认是 100,也就是当前内存分配到达上次存活堆内存 2 倍时,触发 GC;heap_marked:上一个 GC 中被标记的(存活的)字节数;
问题:GOGC 参数不易控制,设置较小提升有限,设置较大容易有 OOM 风险,因为堆大小本身是在实时变化的,在任何流量下都设置一个固定值,是一件有风险的事情。这个问题目前已经有解决方案,Uber 发表的文章中提到了一种自动调整 GOGC 参数的方案,用于在这种方式下优化 GO 的 GC CPU 占用,不过业界还没有开源相关实现

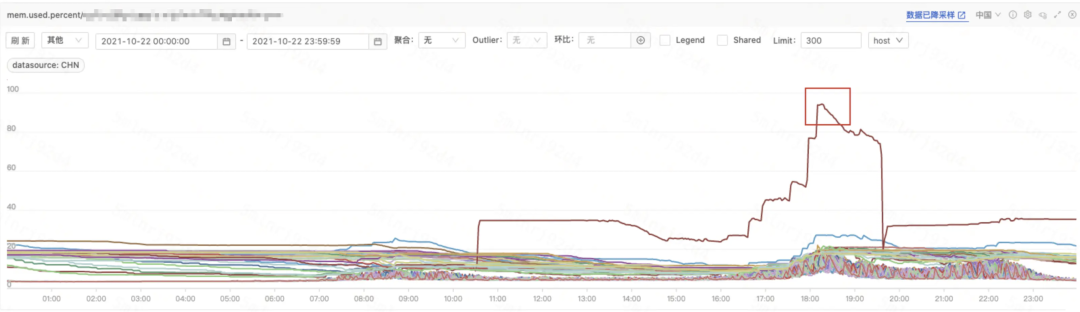
设置 GOGC 至 1000% 后,GC 占用大幅缩小
内存利用率接近 100%
方法三:GO ballast 内存控制
ballast 压舱物--航海。为提供所需的吃水和稳定性而临时或永久携带在船上的重型材料。来源:Dictionary.com
原理:仍然是从利用了下次 GC 触发的 heap 的大小是这次 GC 之后的 heap 的一倍这一原理,初始化一个生命周期贯穿整个 Go 应用生命周期的超大 slice,用于内存占位,增大 heap_marked 值降低 GC 频率;实际操作有以下两种方式
公式:gc_trigger = heap_marked * (1+gcpercent/100) gcpercent:通过 GOGC 来设置,默认是 100,也就是当前内存分配到达上次存活堆内存 2 倍时,触发 GC;heap_marked:上一个 GC 中被标记的(存活的)字节数;
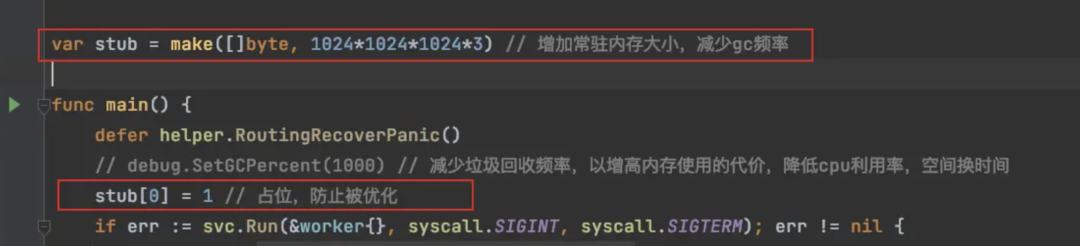
方式一
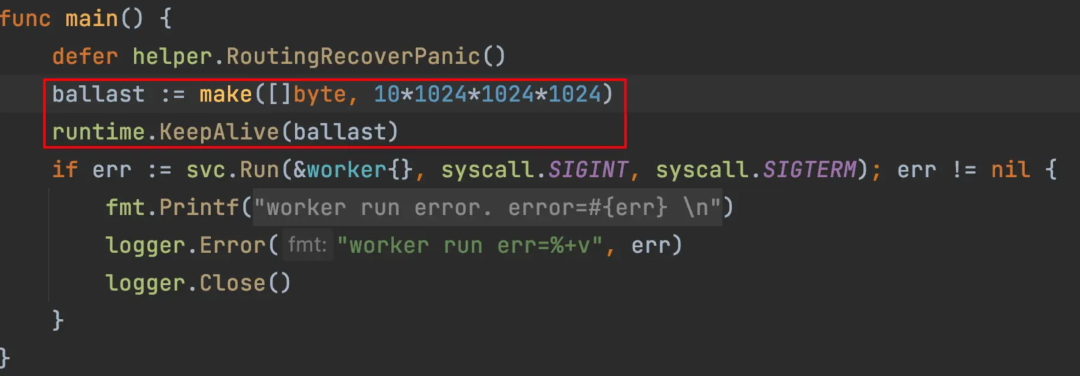
方式二
两种方式都可以达到同样的效果,但是方式一会实际占用物理内存,在可观测性上会更舒服一点,方式二并不会实际占用物理内存。
原因:Memory in ‘nix (and even Windows) systems is virtually addressed and mapped through page tables by the OS. When the above code runs, the array the ballast slice points to will be allocated in the program’s virtual address space. Only if we attempt to read or write to the slice, will the page fault occur that causes the physical RAM backing the virtual addresses to be allocated. 引用自:https://blog.twitch.tv/en/2019/04/10/go-memory-ballast-how-i-learnt-to-stop-worrying-and-love-the-heap/
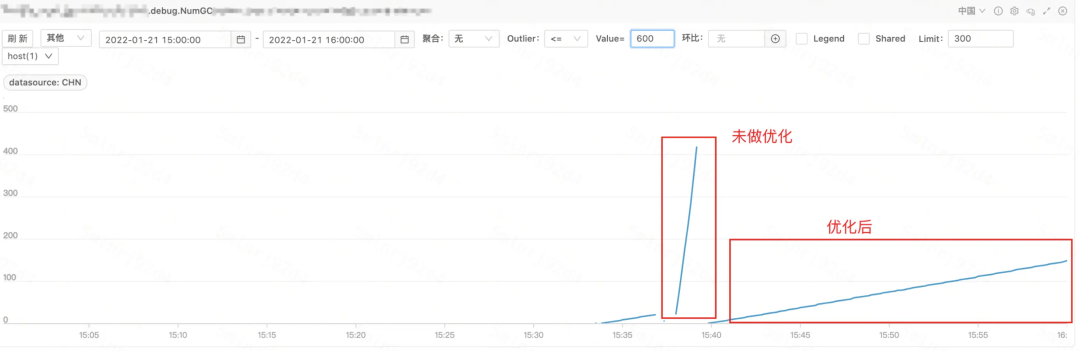
优化后 GC 频率由每秒 5 次降低到了每秒 0.1 次
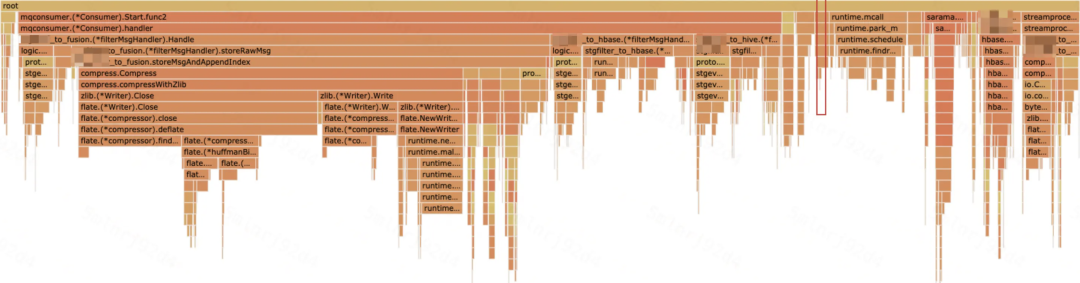
使用 ballast 内存控制后,GC 占用缩小至红框大小
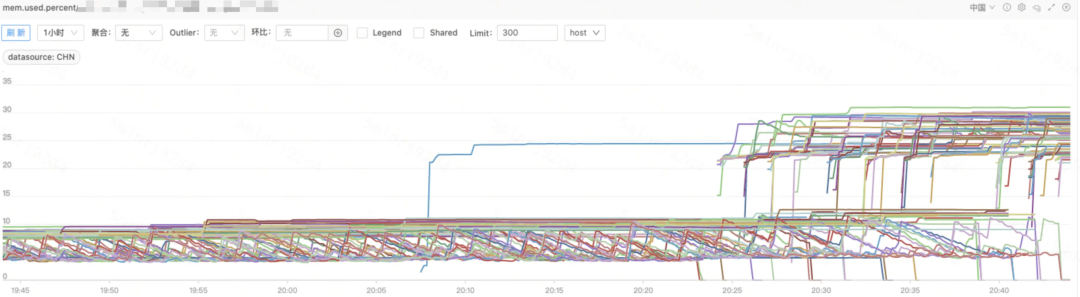
使用方式一后,内存始终稳定在 25% -30%,即 3G 大小
相比于设置 GOGC 的优势
安全性更高,OOM 风险小; 效果更好,可以从 pprof 图看出,后者的优化效果更大;
负面考量问:虽然通过大切片占位的方式可以有效降低 GC 频率,但是每次 GC 需要扫描和回收的对象数量变多了,是否会导致进行 GC 的那一段时间产生耗时毛刺?答:不会,GC 有两个阶段 mark 与 sweep,unused_objects 只与 sweep 阶段有关,但这个过程是非常快速的;mark 阶段是 GC 时间占用最主要的部分,但其只与当前的 inuse_objects 有关,与 unused_objects 无太大关系;因此,综上所述,降低频率确实会让每次 GC 时的 unused_objects 有所增长,但并不会对 GC 增加太多负担;
关于 ballast 内存控制更详细的内容请看:https://blog.twitch.tv/en/2019/04/10/go-memory-ballast-how-i-learnt-to-stop-worrying-and-love-the-heap/
关于 GC 调优
GC 优化手段的优先级:设置 GOGC、GO ballast 内存控制等操作是一种治标不治本略显 trick 的方式,在做 GC 优化时还应先从对象复用、减少对象分配角度着手,在确无优化空间或优化成本较大时,再选择此种方式; 设置 GOGC、GO ballast 内存控制等操作本质上也是一种空间换时间的做法,在内存与 CPU 之间进行压力置换; 在 GC 调优方面,还有很多其他优化方式,如 bigcache 在堆内定义大数组切片自行管理、fastcache 直接调用 syscall.mmap 申请堆外内存使用、offheap 使用 cgo 管理堆外内存等等。
优化效果
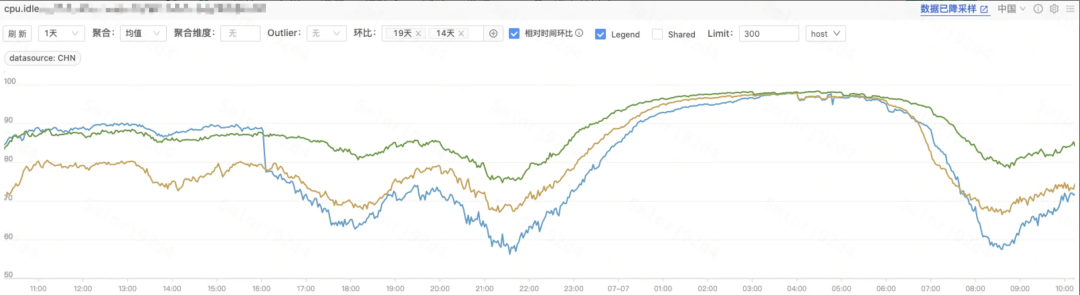
黄色线:调整压缩等级与更换 PB 序列化库;绿色线:Thrift 序列化更换带 buffer 的 transport;
蓝色曲线抖动是因为上游业务放量,后又做垂直伸缩将 CPU 由 8 核提至 16 核
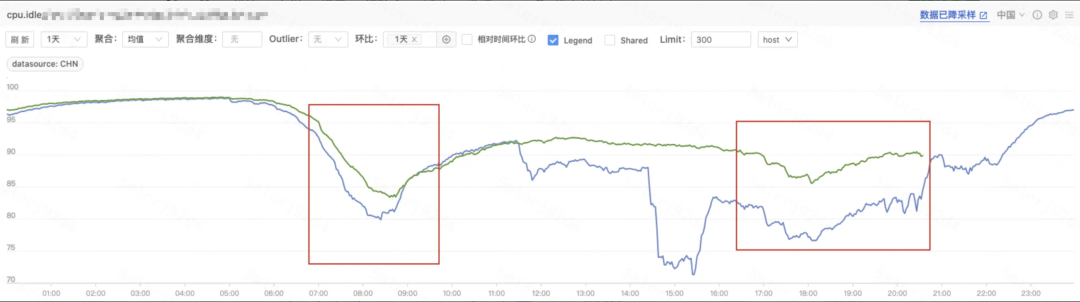
GC 优化(红框部分)
先后将 CPU 提升 **25%、10%**(假设不做伸缩); 支持上游数据 100% 放量; 通过对 CPU 瓶颈的解决,顺利合并服务,下掉 70 台容器。
总结
经验分享
做性能优化经验很重要,其次在优化之前掌握一部分前置知识更好; 平时多看一些资料学习,有优化机会就抓住实践,避免书到用时方恨少; 仔细观察 pprof 图,分析大块部分; 观察问题点的 api 使用,可能具有更高效的使用方式 记录优化过程和优化效果,以后分享、吹逼用的上; 最好可以构建稳定的基准环境,验证效果; 空间换时间是万能钥匙,工程问题不要只 case by case 的看,很多解决方案都是同一种思想的不同落地,尝试去总结和掌握这种思想,最后达到迁移复用的效果; 多和大佬讨论,非常重要,以上多项优化都出自与大佬(特别鸣谢 @李小宇@曹春晖)讨论后的实践;
参考
gogo/protobuf:https://jishuin.proginn.com/p/763bfbd4f993 改善 Go 语言编程质量的 50 个有效实践:第 15 章 注意Go 字符串是原生类型 字节跳动 Go RPC 框架 KiteX 性能优化实践:https://mp.weixin.qq.com/s/Xoaoiotl7ZQoG2iXo9_DWg 某高并发服务 GOGC 及 UDP Pool 优化:https://mp.weixin.qq.com/s/EuJ3Pw0s24Nr1h2edn5Sgg 性能优化 | Go Ballast 让内存控制更加丝滑:https://mp.weixin.qq.com/s/gc34RYqmzeMndEJ1-7sOwg Go 自底向上的性能优化实践:https://www.bilibili.com/video/BV1GT4y127SC?spm_id_from=333.999.0.0 Go memory ballast: How I learnt to stop worrying and love the heap:https://blog.twitch.tv/en/2019/04/10/go-memory-ballast-how-i-learnt-to-stop-worrying-and-love-the-heap/