
老黄狂拼CPU!英伟达掏出800亿晶体管显卡,外加世界最快AI超算Eos

新智元报道
编辑:编辑部
【新智元导读】「拼装」CPU,4纳米显卡,世界最快AI超算,还有游戏开发者的元宇宙。这次,老黄的百宝箱里都有啥?
 虽然没有了那个熟悉的厨房,但这次的阵仗反而更加豪华。 英伟达用Omniverse把新总部从内到外渲染了一遍!
虽然没有了那个熟悉的厨房,但这次的阵仗反而更加豪华。 英伟达用Omniverse把新总部从内到外渲染了一遍! 800亿个晶体管的Hopper H100
随着拔地而起的平台,英伟达推出了为超算设计的最新AI显卡Hopper H100。 相比于「只有」540亿个晶体管的前辈A100,英伟达在H100中装入了800亿个晶体管,并采用了定制的台积电4纳米工艺。 也就是说,H100将具有更好的功率/性能特性,并在密度方面有一定程度上的改进。 在算力上,H100的FP16、TF32以及FP64性能都是A100的3倍,分别为2000 TFLOPS、1000 TFLOPS和60 TFLOPS。 此外,H100还增加了对FP8支持,算力高达4000 TFLOPS,比A100快6倍。毕竟在 这方面,后者由于缺乏原生FP8支持而不得不依赖FP16。 内存方面,H100也将默认支持带宽为3TB/s的HBM3,比A100的HBM2E提升1.5倍。
在算力上,H100的FP16、TF32以及FP64性能都是A100的3倍,分别为2000 TFLOPS、1000 TFLOPS和60 TFLOPS。 此外,H100还增加了对FP8支持,算力高达4000 TFLOPS,比A100快6倍。毕竟在 这方面,后者由于缺乏原生FP8支持而不得不依赖FP16。 内存方面,H100也将默认支持带宽为3TB/s的HBM3,比A100的HBM2E提升1.5倍。  H100支持的第四代NVLink接口可以提供高达128GB/s的带宽,是A100的1.5倍;而在PCIe 5.0下也可以达到128GB/s的速度,是PCIe 4.0的2倍。 同时,H100的SXM版本将TDP增加到了700W,而A100为400W。而75%的功率提升,通常来说可以预计获得2到3倍的性能。 为了优化性能,Nvidia还推出了一个新的Transformer Engine,将根据工作负载在FP8和FP16格式之间自动切换。
H100支持的第四代NVLink接口可以提供高达128GB/s的带宽,是A100的1.5倍;而在PCIe 5.0下也可以达到128GB/s的速度,是PCIe 4.0的2倍。 同时,H100的SXM版本将TDP增加到了700W,而A100为400W。而75%的功率提升,通常来说可以预计获得2到3倍的性能。 为了优化性能,Nvidia还推出了一个新的Transformer Engine,将根据工作负载在FP8和FP16格式之间自动切换。 | H100 | A100 (80GB) | |
| CUDA核心 | 16896 | 6912 |
| 张量核心 | 528 | 432 |
| 超频频率 | 约1.78GHz | 1.41GHz |
| 内存 | 4.8Gbps HBM3 | 3.2Gbps HBM2e |
| 内存带宽 | 3TB/s | 2TB/s |
| FP32矢量 | 60 TFLOPS | 19.5 TFLOPS |
| FP64矢量 | 30 TFLOPS | 9.7 TFLOPS(1/2 FP32) |
| INT8张量 | 2000 TOPS | 624 TOPS |
| FP16张量 | 1000 TFLOPS | 312 TFLOPS |
| TF32张量 | 500 TFLOPS | 156 TFLOPS |
| FP64张量 | 60 TFLOPS | 19.5 TFLOPS |
| 总线 | NVLink 418条 (900GB/s) | NVLink 312条 (600GB/s) |
| GPU | GH100(814平方毫米) | GA100(826平方毫米) |
| 晶体管数量 | 800亿 | 542亿 |
| TDP | 700W | 400W |
| 制造工艺 | TSMC 4N | TSMC 7N |
| 架构 | Hopper | Ampere |
DGX服务器系统
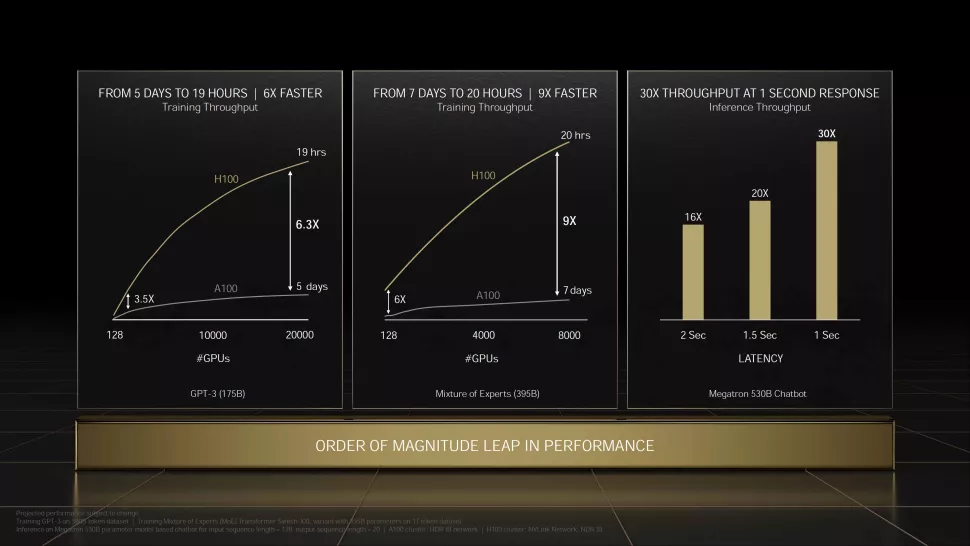
第四代英伟达DGX服务器系统,将世界上第一个采用H100显卡构建的AI服务器平台。 DGX H100服务器系统可提供满足大型语言模型、推荐系统、医疗保健研究和气候科学的海量计算需求所需的规模。 其中,每个服务器系统包含8个H100显卡,通过NVLink链接为单个整体,晶体管总计6400亿个。 在FP8精度下,DGX H100可以提供32 PFLOPS的性能,比上一代高6倍。 此外,每个DGX H100系统还包括两个NVIDIA BlueField-3 DPU,用于卸载、加速和隔离网络、存储和安全服务。 8个NVIDIA ConnectX-7 Quantum-2 InfiniBand网络适配器提供每秒400 Gb的吞吐量来连接计算和存储模块——速度是上一代系统的两倍。 第四代NVLink与NVSwitch相结合,可在每个DGX H100系统中的每个GPU之间提供每秒900 GB的连接,是上一代的1.5倍。 而最新的DGX SuperPOD架构则可连接多达32个节点、总共256个H100显卡。 DGX SuperPOD可提供1 EFLOPS的FP8性能,同样也是前代的6倍。
此外,每个DGX H100系统还包括两个NVIDIA BlueField-3 DPU,用于卸载、加速和隔离网络、存储和安全服务。 8个NVIDIA ConnectX-7 Quantum-2 InfiniBand网络适配器提供每秒400 Gb的吞吐量来连接计算和存储模块——速度是上一代系统的两倍。 第四代NVLink与NVSwitch相结合,可在每个DGX H100系统中的每个GPU之间提供每秒900 GB的连接,是上一代的1.5倍。 而最新的DGX SuperPOD架构则可连接多达32个节点、总共256个H100显卡。 DGX SuperPOD可提供1 EFLOPS的FP8性能,同样也是前代的6倍。 
世界上最快的AI超算
由576个DGX H100服务器系统和4608个DGX H100显卡组成的「Eos」超级计算机预计将提供18.4 EFLOPS的AI计算性能,比目前世界上最快的超算——日本的「富岳」快4倍。 对于传统的科学计算,Eos有望提供275 PFLOPS的性能。
Transformer Engine
作为新Hopper架构的一部分,将显著提高AI的性能,大型模型的训练可以在数天甚至数小时内完成。 传统的神经网络模型在训练过程中采用的精度是固定的,因此也难以将FP8应用在整个模型之中。 而Transformer Engine则可以在FP16和FP8之间逐层训练,并利用英伟达提供的启发式方法来选择所需的最低精度。 此外,Transformer Engine可以用2倍于FP16的速度打包和处理FP8数据,于是模型的每一层可以用FP8处理的数据都可以提升2倍的速度。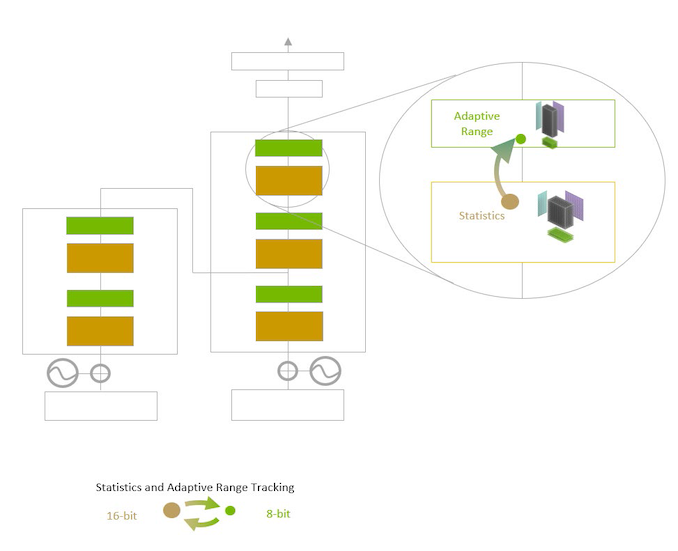
Grace CPU超级芯片
除了显卡,英伟达今天还推出了其首款基于Arm Neoverse架构的处理器——Grace CPU超级芯片。 它基于此前发布的Grace Hopper CPU+GPU设计,只不过把显卡换成了CPU。 据英伟达实验室估计,在使用同类编译器时,Grace CPU超级芯片性能可以提升1.5倍以上。 在技术规格上,可以概括为:- 2个72核芯片,高达144个Arm v9 CPU核心
- 采用ECC技术的新一代LPDDR5x内存,总带宽为1TB/s
- SPECrate 2017_int_base得分预计超过740
- 900GB/s 一致性接口,比PCIe 5.0快7倍
- 封装密度比DIMM解决方案提高了2倍
- 每瓦性能2倍于当今领先的CPU
 超级芯片中的两个CPU通过英伟达最新的NVLink「芯片到芯片」(C2C) 接口进行通信。 这种「裸晶到裸晶」和「芯片到芯片」的互连支持低延迟内存一致性,允许连接的设备同时在同一个内存池上工作。
超级芯片中的两个CPU通过英伟达最新的NVLink「芯片到芯片」(C2C) 接口进行通信。 这种「裸晶到裸晶」和「芯片到芯片」的互连支持低延迟内存一致性,允许连接的设备同时在同一个内存池上工作。  Grace CPU超级芯片拥有更先进的能效和内存带宽,其创新的内存子系统由带有ECC的LPDDR5x内存组成。 LPDDR5x可以提供两倍于传统DDR5的带宽,同时还能使CPU加内存的功耗显著降低至500瓦。 相比之下,AMD的芯片在基准测试中的结果从382到424不等,且每个芯片的功耗最高可达280W(还不包括内存)。 此外,Grace CPU超级芯片与NVIDIA ConnectX-7 NIC一起提供了配置到服务器中的灵活性,可作为独立的纯CPU系统或作为具有1 个、2个、4个或8个基于Hopper显卡的加速服务器。
Grace CPU超级芯片拥有更先进的能效和内存带宽,其创新的内存子系统由带有ECC的LPDDR5x内存组成。 LPDDR5x可以提供两倍于传统DDR5的带宽,同时还能使CPU加内存的功耗显著降低至500瓦。 相比之下,AMD的芯片在基准测试中的结果从382到424不等,且每个芯片的功耗最高可达280W(还不包括内存)。 此外,Grace CPU超级芯片与NVIDIA ConnectX-7 NIC一起提供了配置到服务器中的灵活性,可作为独立的纯CPU系统或作为具有1 个、2个、4个或8个基于Hopper显卡的加速服务器。 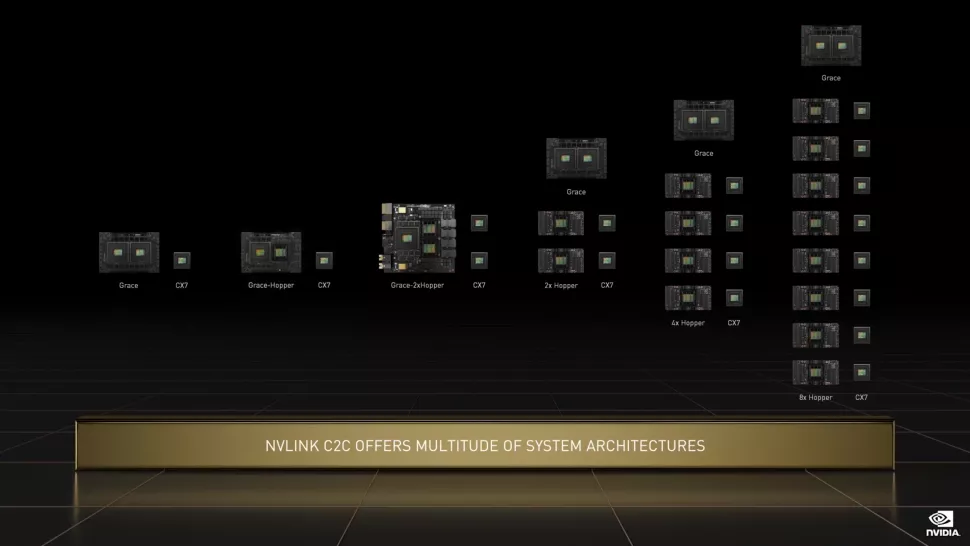
安培架构再添新品
今天,英伟达为笔记本电脑和台式机提供了七种基于Ampere架构的显卡——RTX A500、RTX A1000、RTX A2000 8GB、RTX A3000 12GB、RTX A4500和RTX A5500。 新的RTX A5500台式机显卡可实现出色的渲染、AI、图形和计算性能。其光线追踪渲染比上一代快2倍,其运动模糊渲染性能最高可提高9倍。 第二代RT核心:吞吐量高达第一代的2倍,能够同时运行光线追踪、着色和去噪任务。 第三代Tensor Cores:训练吞吐量是前一代的12倍,支持新的TF32和Bfloat16数据格式。CUDA核心。比上一代的单精度浮点吞吐量高达3倍。 高达48GB的GPU内存:RTX A5500具有24GB的GDDR6内存,带有ECC(纠错码)。使用NVLink连接两个GPU,RTX A5500的内存可扩展至48GB。 虚拟化:RTX A5500支持NVIDIA RTX虚拟工作站(vWS)软件,用于多个高性能虚拟工作站实例,使远程用户能够共享资源,推动高端设计、AI和计算工作负载。 PCIe 4.0:带宽是上一代的2倍,加快了数据密集型任务的数据传输,如AI、数据科学和创建3D模型。
第二代RT核心:吞吐量高达第一代的2倍,能够同时运行光线追踪、着色和去噪任务。 第三代Tensor Cores:训练吞吐量是前一代的12倍,支持新的TF32和Bfloat16数据格式。CUDA核心。比上一代的单精度浮点吞吐量高达3倍。 高达48GB的GPU内存:RTX A5500具有24GB的GDDR6内存,带有ECC(纠错码)。使用NVLink连接两个GPU,RTX A5500的内存可扩展至48GB。 虚拟化:RTX A5500支持NVIDIA RTX虚拟工作站(vWS)软件,用于多个高性能虚拟工作站实例,使远程用户能够共享资源,推动高端设计、AI和计算工作负载。 PCIe 4.0:带宽是上一代的2倍,加快了数据密集型任务的数据传输,如AI、数据科学和创建3D模型。 游戏开发者也有元宇宙了
已经在元宇宙拥有一席之地的Omniverse再次得到了加强。 本次大会上,英伟达发布了NVIDIA Omniverse的全新功能,使开发者能够更轻松地共享资产、对资产库进行分类、开展协作,并在全新游戏开发流程中部署AI来为角色制作面部表情的动画。 借助NVIDIA Omniverse实时设计协作和模拟平台,游戏开发者可以使用支持AI和NVIDIA RTX的工具,轻松构建自定义工具,以简化、加速和改进其开发工作流。其组件包括:
本次大会上,英伟达发布了NVIDIA Omniverse的全新功能,使开发者能够更轻松地共享资产、对资产库进行分类、开展协作,并在全新游戏开发流程中部署AI来为角色制作面部表情的动画。 借助NVIDIA Omniverse实时设计协作和模拟平台,游戏开发者可以使用支持AI和NVIDIA RTX的工具,轻松构建自定义工具,以简化、加速和改进其开发工作流。其组件包括: - Omniverse Audio2Face,一款由NVIDIA AI驱动的应用,使角色艺术家通过音频文件生成高质量的面部动画。Audio2Face支持完整的面部动画,艺术家们还能控制表演的情感。有了Audio2Face,游戏开发者可以快速、轻松地为其游戏角色添加逼真的表情,促进玩家和游戏角色之间更强的情感连接,增强沉浸感。
- Omniverse Nucleus Cloud现已开放抢先体验版,可实现Omniverse场景的一键式简单共享,无需在本地或私有云中部署Nucleus。通过Nucleus Cloud,游戏开发者可轻松地在内、外部开发团队之间实时分享和协作3D资产。
- Omniverse DeepSearch是一项AI服务,现在可供Omniverse企业用户使用,它允许游戏开发者使用自然语言输入和图像来即时搜索其整个未标记的3D资产、物体对象和角色目录。
- Omniverse Connectors实现第三方设计工具和Omniverse之间的「实时同步」协作工作流的插件。全新虚幻引擎5 Omniverse Connector允许游戏艺术家在游戏引擎和Omniverse之间交换USD和材料定义语言数据。
将数据中心转变为「AI工厂」
不管是Hopper显卡架构还是AI加速软件,抑或是强大的数据中心系统。 所有的这些都将由Omniverse汇集起来,从而更好地模拟和理解现实世界,并作为新型机器人的试验场,即所谓「下一波AI」。 由于加速计算技术的发展,AI的进展惊人,人工智能已经从根本上改变了软件可以做什么,以及如何开发软件。 老黄表示,Transformer摆脱了对人类标记数据的需求,使自监督学习成为可能,而人工智能一跃以空前的速度发展。 用于语言理解的谷歌BERT,用于药物发现的英伟达MegaMolBART,以及DeepMind AlphaFold2都是Transformer带来的突破。 英伟达的AI平台也得到了重大的更新,包括Triton推理服务器、用于训练大型语言模型的NeMo Megatron 0.9框架,以及用于音频和视频质量增强的Maxine框架。
 「我们将在未来十年再争取实现百万倍的算力提升,」老黄在结束他的演讲时说,「我迫不及待地想看看下一个百万倍会带来什么了。」
「我们将在未来十年再争取实现百万倍的算力提升,」老黄在结束他的演讲时说,「我迫不及待地想看看下一个百万倍会带来什么了。」参考资料:
https://www.nvidia.cn/gtc-global/keynote/

评论