 小白学视觉
小白学视觉




点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
https://github.com/HOD101s/RockPaperScissor-AI-
简介
收集和处理数据 建立一个合适的人工智能模型 部署使用
收集我们的数据

PATH = os.getcwd()+'\\'
cap = cv2.VideoCapture(0)
label = sys.argv[1]
SAVE_PATH = os.path.join(PATH, label)
try:
os.mkdir(SAVE_PATH)
except FileExistsError:
pass
ct = int(sys.argv[2])
maxCt = int(sys.argv[3])+1
print("Hit Space to Capture Image")
while True:
ret, frame = cap.read()
cv2.imshow('Get Data : '+label,frame[50:350,100:450])
if cv2.waitKey(1) & 0xFF == ord(' '):
cv2.imwrite(SAVE_PATH+'\\'+label+'{}.jpg'.format(ct),frame[50:350,100:450])
print(SAVE_PATH+'\\'+label+'{}.jpg Captured'.format(ct))
ct+=1
if ct >= maxCt:
break
cap.release()
cv2.destroyAllWindows()
C:.
├───paper
│ paper0.jpg
│ paper1.jpg
│ paper2.jpg
│
├───rock
│ rock0.jpg
│ rock1.jpg
│ rock2.jpg
│
└───scissor
scissor0.jpg
scissor1.jpg
scissor2.jpg
预处理我们的数据
DATA_PATH = sys.argv[1] # Path to folder containing data
shape_to_label = {'rock':np.array([1.,0.,0.,0.]),'paper':np.array([0.,1.,0.,0.]),'scissor':np.array([0.,0.,1.,0.]),'ok':np.array([0.,0.,0.,1.])}
arr_to_shape = {np.argmax(shape_to_label[x]):x for x in shape_to_label.keys()}
imgData = list()
labels = list()
for dr in os.listdir(DATA_PATH):
if dr not in ['rock','paper','scissor']:
continue
print(dr)
lb = shape_to_label[dr]
i = 0
for pic in os.listdir(os.path.join(DATA_PATH,dr)):
path = os.path.join(DATA_PATH,dr+'/'+pic)
img = cv2.imread(path)
imgData.append([img,lb])
imgData.append([cv2.flip(img, 1),lb]) #horizontally flipped image
imgData.append([cv2.resize(img[50:250,50:250],(300,300)),lb]) # zoom : crop in and resize
i+=3
print(i)
np.random.shuffle(imgData)
imgData,labels = zip(*imgData)
imgData = np.array(imgData)
labels = np.array(labels)
cv2.imread()函数 https://www.geeksforgeeks.org/python-opencv-cv2-imread-method/
https://towardsdatascience.com/data-augmentation-for-deep-learning-4fe21d1a4eb9
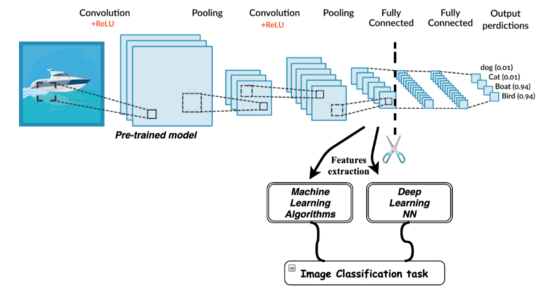
InceptionV3 VGG16/19 ResNet MobileNet
https://ruder.io/transfer-learning/
https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
densenet = DenseNet121(include_top=False, weights='imagenet', classes=3,input_shape=(300,300,3))
densenet.trainable=True
def genericModel(base):
model = Sequential()
model.add(base)
model.add(MaxPool2D())
model.add(Flatten())
model.add(Dense(3,activation='softmax'))
model.compile(optimizer=Adam(),loss='categorical_crossentropy',metrics=['acc'])
return model
dnet = genericModel(densenet)
history = dnet.fit(
x=imgData,
y=labels,
batch_size = 16,
epochs=8,
callbacks=[checkpoint,es],
validation_split=0.2
)
由于我们的图片尺寸为300x300,因此指定的输入形状也为3x300x300,3代表RGB的维度信息,因此该层具有足够的神经元来处理整个图像。 我们将DenseNet层用作第一层,然后使用我们自己的Dense神经网络。 我已将可训练参数设置为True,这也会重新训练DenseNet的权重。尽管花了很多时间,但是这给了我更好的结果。我建议你在自己的实现中尝试通过更改此类参数(也称为超参数)来尝试不同的迭代。 由于我们有3类Rock-Paper-Scissor,最后一层是具有3个神经元和softmax激活的全连接层。 最后一层返回图像属于3类中特定类的概率。 如果你引用的是GitHub repo(https://github.com/HOD101s/RockPaperScissor-AI-) 的train.py,则要注意数据准备和模型训练!
OpenCV实现:
启动网络摄像头并读取每个帧 将此框架传递给模型进行分类,即预测类 用电脑随意移动 计算分数
def prepImg(pth):
return cv2.resize(pth,(300,300)).reshape(1,300,300,3)
with open('model.json', 'r') as f:
loaded_model_json = f.read()
loaded_model = model_from_json(loaded_model_json)
loaded_model.load_weights("modelweights.h5")
print("Loaded model from disk")
for rounds in range(NUM_ROUNDS):
pred = ""
for i in range(90):
ret,frame = cap.read()
# Countdown
if i//20 < 3 :
frame = cv2.putText(frame,str(i//20+1),(320,100),cv2.FONT_HERSHEY_SIMPLEX,3,(250,250,0),2,cv2.LINE_AA)
# Prediction
elif i/20 < 3.5:
pred = arr_to_shape[np.argmax(loaded_model.predict(prepImg(frame[50:350,100:400])))]
# Get Bots Move
elif i/20 == 3.5:
bplay = random.choice(options)
print(pred,bplay)
# Update Score
elif i//20 == 4:
playerScore,botScore = updateScore(pred,bplay,playerScore,botScore)
break
cv2.rectangle(frame, (100, 150), (300, 350), (255, 255, 255), 2)
frame = cv2.putText(frame,"Player : {} Bot : {}".format(playerScore,botScore),(120,400),cv2.FONT_HERSHEY_SIMPLEX,1,(250,250,0),2,cv2.LINE_AA)
frame = cv2.putText(frame,pred,(150,140),cv2.FONT_HERSHEY_SIMPLEX,1,(250,250,0),2,cv2.LINE_AA)
frame = cv2.putText(frame,"Bot Played : {}".format(bplay),(300,140),cv2.FONT_HERSHEY_SIMPLEX,1,(250,250,0),2,cv2.LINE_AA)
cv2.imshow('Rock Paper Scissor',frame)
if cv2.waitKey(1) & 0xff == ord('q'):
break
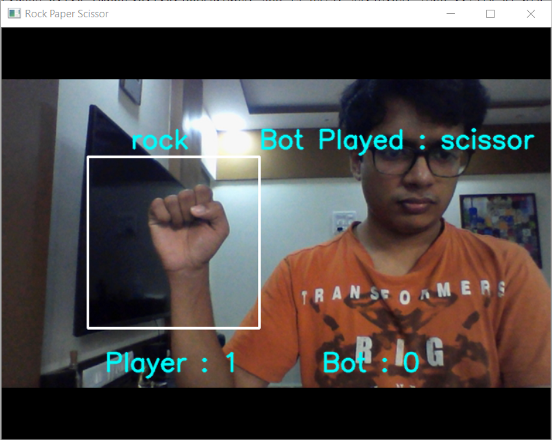
结论:
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



