
谷歌提出model soup,将ImageNet准确度刷新到新高度:90.94%!
共 2874字,需浏览 6分钟
· 2022-03-15
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近日,谷歌等研究机构在论文Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time提出了一种提升模型准确度的简单方法model soups:用不同的超参数来对预训练模型进行finetune得到多个模型权重然后求平均。他们将model soups方法应用JFT-3B预训练的ViTG/14模型,在ImageNet1K数据集上达到了SOTA:90.94% top-1 acc,超过之前的CoAtNet-7(90.88%)。
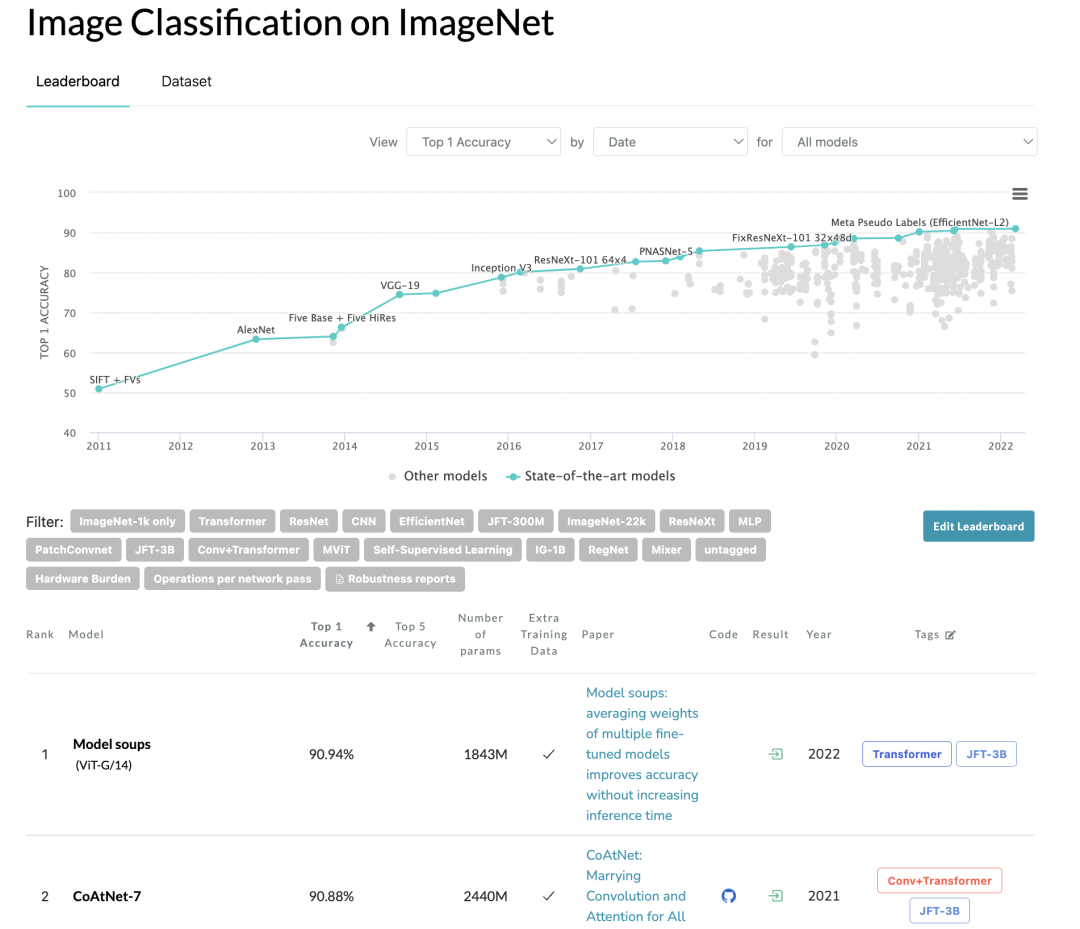 目前无论是图像还是文本任务,大家往往会采用pretrain+finetune的范式来迁移到其它任务上,比如我们一般会采用ImageNet1K数据集上预训练的ResNet在其它图像分类任务上进行微调,具体的做法是:选择不同的超参数来finetune模型,然后选择在验证集上效果最好的模型。而论文提出的model soups方法是对这些不同超参数finetune后的模型的权重进行平均来获取最后的模型。假定为某个预训练模型在不同的超参数finetune后得到的模型权重集合,下面为不同方法的对比:
目前无论是图像还是文本任务,大家往往会采用pretrain+finetune的范式来迁移到其它任务上,比如我们一般会采用ImageNet1K数据集上预训练的ResNet在其它图像分类任务上进行微调,具体的做法是:选择不同的超参数来finetune模型,然后选择在验证集上效果最好的模型。而论文提出的model soups方法是对这些不同超参数finetune后的模型的权重进行平均来获取最后的模型。假定为某个预训练模型在不同的超参数finetune后得到的模型权重集合,下面为不同方法的对比: 其中Best on val. set即前面说到的常规做法,直接选择验证集上准确度最高的模型;还有一种可以采用的方法就是模型集成,但是这个会增加推理时间。对于model soup这里列举了3种方法,其中最简单的是uniform soup,即直接对全部的模型权重求平均,第2种方法是greedy soup,首先按照验证集上准确度降序排列,然后逐个增加模型来进行权重平均,只有当得到的平均模型效果有提升时才考虑将当前的模型加入进来,这是一种简单的贪心策略,根据论文的实验结果,greedy soup往往要比uniform soup效果要好,也是论文最后采用的策略。最后一种方法learned soup是要通过学习来得到不同模型的混合权重系数。
其中Best on val. set即前面说到的常规做法,直接选择验证集上准确度最高的模型;还有一种可以采用的方法就是模型集成,但是这个会增加推理时间。对于model soup这里列举了3种方法,其中最简单的是uniform soup,即直接对全部的模型权重求平均,第2种方法是greedy soup,首先按照验证集上准确度降序排列,然后逐个增加模型来进行权重平均,只有当得到的平均模型效果有提升时才考虑将当前的模型加入进来,这是一种简单的贪心策略,根据论文的实验结果,greedy soup往往要比uniform soup效果要好,也是论文最后采用的策略。最后一种方法learned soup是要通过学习来得到不同模型的混合权重系数。 对于权重平均其实也不是什么新奇事物,比如常用的SWA(Stochastic Weight Averaging)方法:通过对某个模型训练过程的不同step或者epochs下产生的权重进行平均来提升模型泛化性。model soup与它的区别是它是用不同超参数独立训练的模型权重(用同一个预训练参数初始化)进行平均,这其实不太常见,这种思路来自对误差 landscape的可视化分析。对于一个预训练权重,通过不同的超参数(不同的随机seed和lr)进行finetune得到两个新的模型:和,然后画出它们的训练损失和测试误差的2D landscape(可视化方法见论文Visualizing the Loss Landscape of Neural Nets),如下所示:
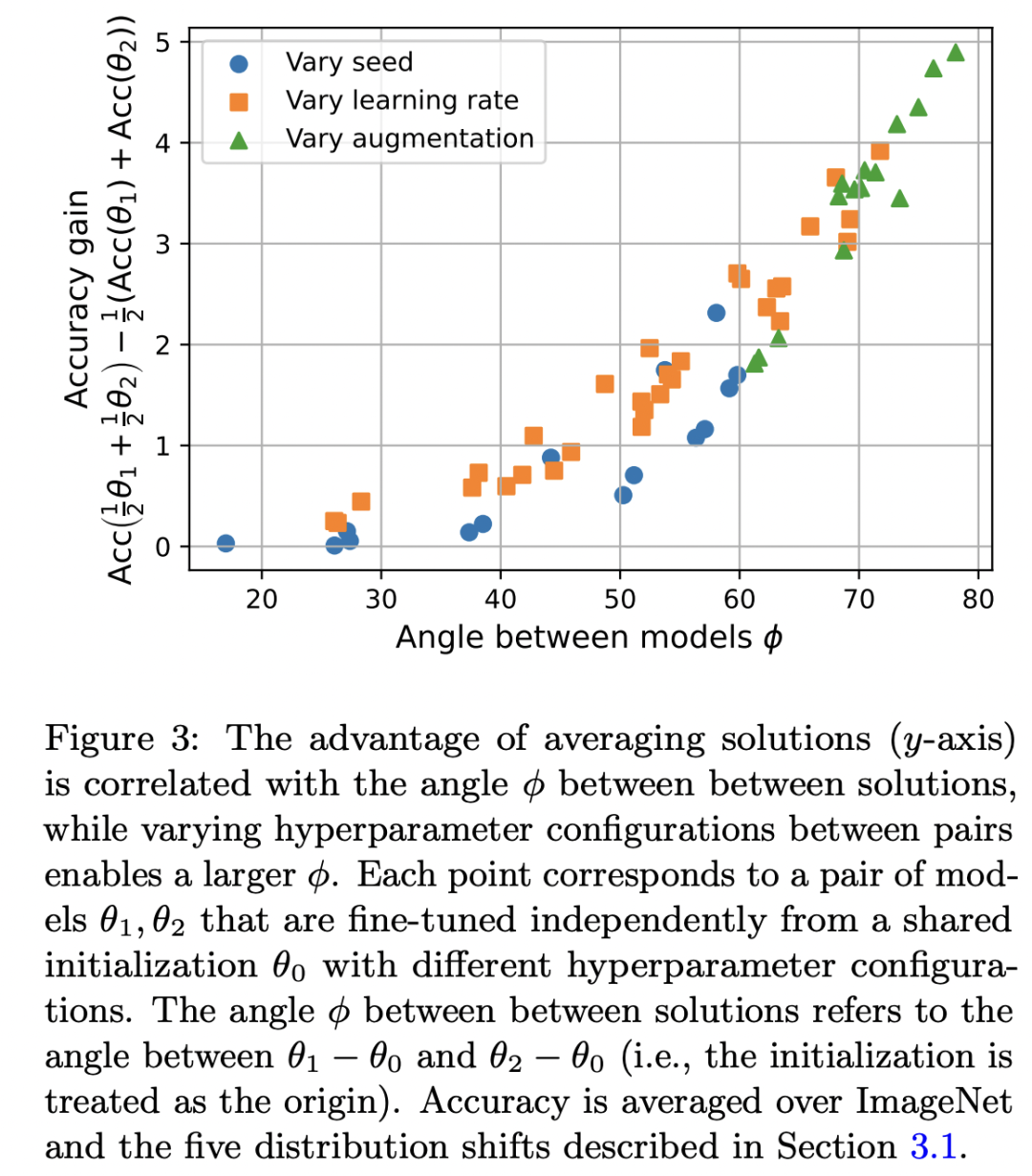
对于权重平均其实也不是什么新奇事物,比如常用的SWA(Stochastic Weight Averaging)方法:通过对某个模型训练过程的不同step或者epochs下产生的权重进行平均来提升模型泛化性。model soup与它的区别是它是用不同超参数独立训练的模型权重(用同一个预训练参数初始化)进行平均,这其实不太常见,这种思路来自对误差 landscape的可视化分析。对于一个预训练权重,通过不同的超参数(不同的随机seed和lr)进行finetune得到两个新的模型:和,然后画出它们的训练损失和测试误差的2D landscape(可视化方法见论文Visualizing the Loss Landscape of Neural Nets),如下所示: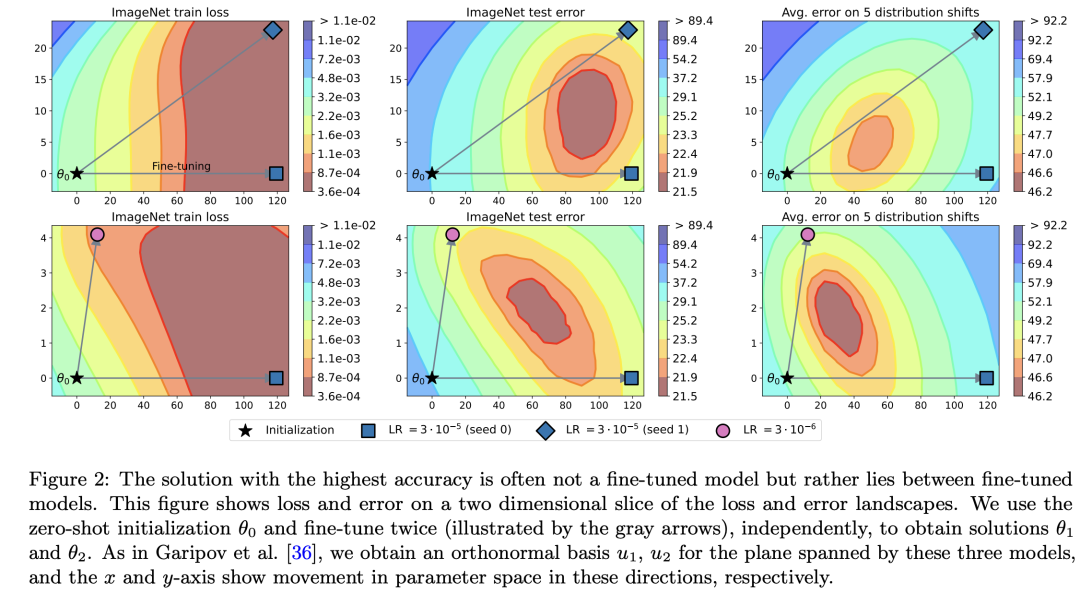 可以看到无论是域内还是域外测试误差,其2D landscape的轮廓都呈盆状,这意味着和都不是最优的,而是在两者之间,这提示我们是否可以通过对两个模型的权重插值来获得更好的模型,而且从图上可以看到似乎两个模型(和这两个矢量线)的夹角越接近90度,通过插值可能得到模型效果越好。为了验证这个猜想,作者训练了一系列的模型,它们采用不同的超参数进行finetune,如随机种子,学习速率和数据增强,对于每两个模型,计算用权重平均得到模型准确度和两个模型平均准确度的差值:。具体的实验结果如下图所示,可以看到用权重平均得到的模型准确度要超过两个模型准确度平均值,而且两个模型越正交(角度越接近90度),带来的提升越大。
可以看到无论是域内还是域外测试误差,其2D landscape的轮廓都呈盆状,这意味着和都不是最优的,而是在两者之间,这提示我们是否可以通过对两个模型的权重插值来获得更好的模型,而且从图上可以看到似乎两个模型(和这两个矢量线)的夹角越接近90度,通过插值可能得到模型效果越好。为了验证这个猜想,作者训练了一系列的模型,它们采用不同的超参数进行finetune,如随机种子,学习速率和数据增强,对于每两个模型,计算用权重平均得到模型准确度和两个模型平均准确度的差值:。具体的实验结果如下图所示,可以看到用权重平均得到的模型准确度要超过两个模型准确度平均值,而且两个模型越正交(角度越接近90度),带来的提升越大。
 那么既然对两个模型权重求平均有效,那是不是可以对多个权重求平均,这就是model soups了。论文基于CLIP ViT-B/32和ALIGN EfficientNet-L2两个模型分别进行实验,其中CLIP模型采用不同的学习速率,weight decay,训练时长,label smoothing和数据增强共产生72个finetune后的模型;而ALIGN模型采用不同的学习速率,数据增强和mixup产生12个模型。对于greedy soup,通过贪心算法只选择5个模型。下图为model soup和原始预训练以及单个最好模型的对比图,可以看到greedy soup可以比单个最好模型提升0.7和0.5。
那么既然对两个模型权重求平均有效,那是不是可以对多个权重求平均,这就是model soups了。论文基于CLIP ViT-B/32和ALIGN EfficientNet-L2两个模型分别进行实验,其中CLIP模型采用不同的学习速率,weight decay,训练时长,label smoothing和数据增强共产生72个finetune后的模型;而ALIGN模型采用不同的学习速率,数据增强和mixup产生12个模型。对于greedy soup,通过贪心算法只选择5个模型。下图为model soup和原始预训练以及单个最好模型的对比图,可以看到greedy soup可以比单个最好模型提升0.7和0.5。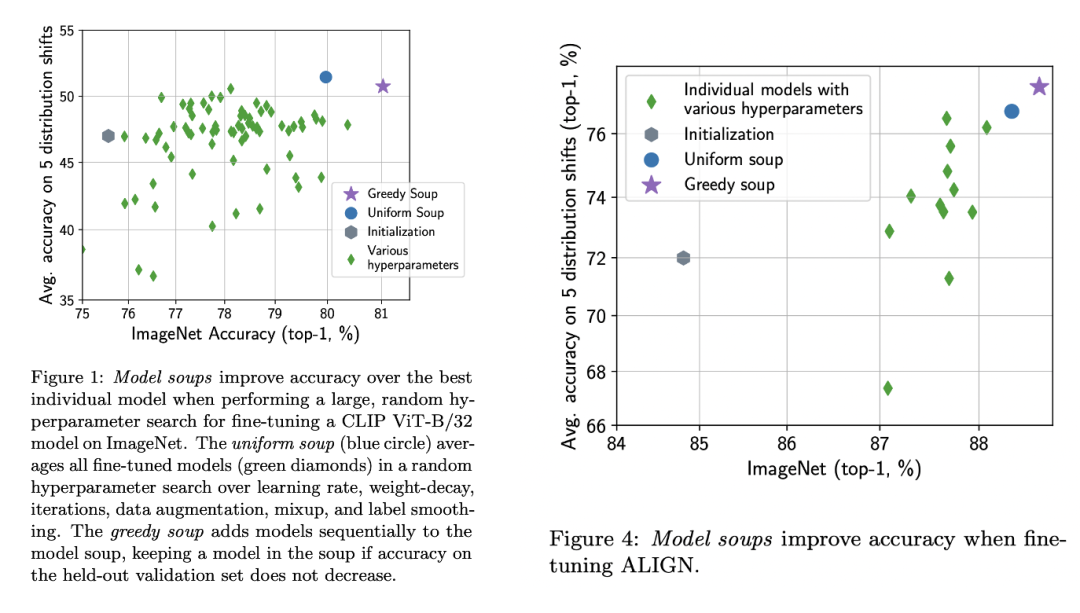 论文还研究了不同模型数量下greedy soup和其它方法的结果对比,可以看到在域内测试上效果虽然不如模型集成,但是要超过单个模型和uniform soup,而在域外测试上greedy soup效果最好。这其实也说明greedy soup相比单个最好模型达到相同的效果所需要训练的模型量要少。
论文还研究了不同模型数量下greedy soup和其它方法的结果对比,可以看到在域内测试上效果虽然不如模型集成,但是要超过单个模型和uniform soup,而在域外测试上greedy soup效果最好。这其实也说明greedy soup相比单个最好模型达到相同的效果所需要训练的模型量要少。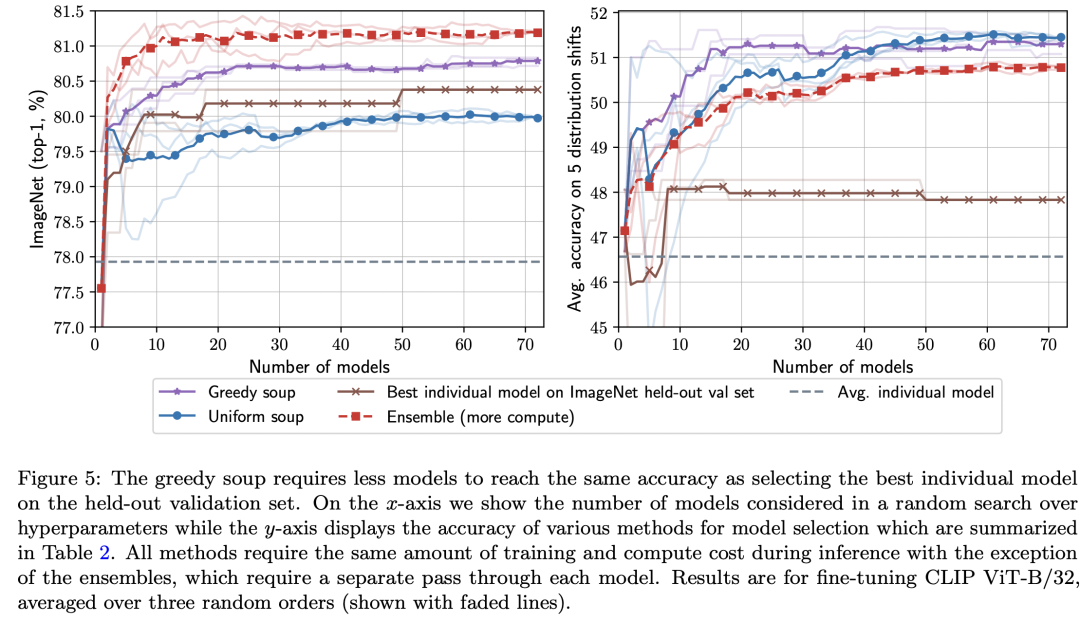 如果将greedy soup应用在JFT-3B预训练的ViT-G/14模型上,可以将ImageNet1K上的top1-acc由原来的90.47提升至90.94。
如果将greedy soup应用在JFT-3B预训练的ViT-G/14模型上,可以将ImageNet1K上的top1-acc由原来的90.47提升至90.94。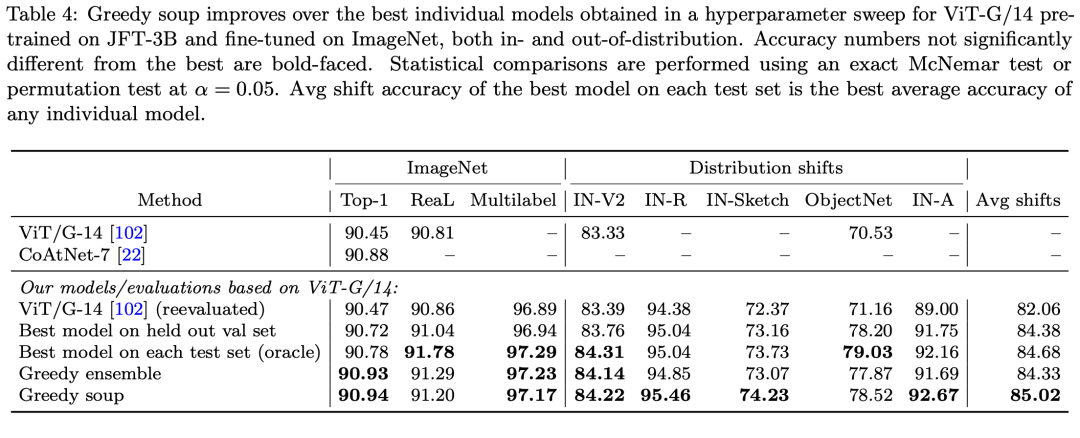 model soup不仅在图像分类任务上有效,同样可以应用在文本分类上,基于BERT和T5模型进行实验,均可以带来一定的性能提升:
model soup不仅在图像分类任务上有效,同样可以应用在文本分类上,基于BERT和T5模型进行实验,均可以带来一定的性能提升: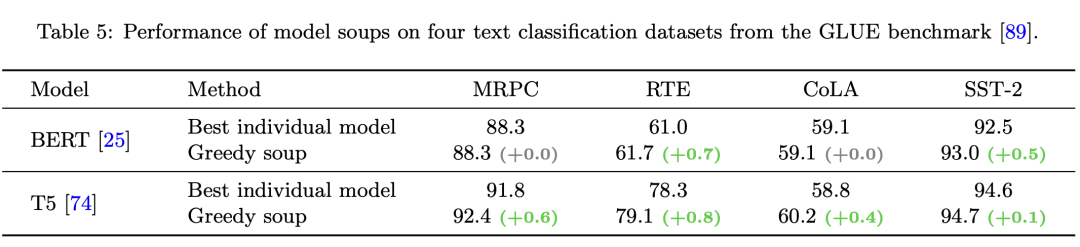 除此之外,论文还理论分析了model soups和model ensembles之间的关联,感兴趣的可以看论文中具体分析。
除此之外,论文还理论分析了model soups和model ensembles之间的关联,感兴趣的可以看论文中具体分析。
虽然model soups看起来很有效,但是论文也指出来它的局限性,首先论文的实验模型都是基于大规模数据集上的预训练模型,论文实验了ImageNet-22k数据集上预训练模型,发现虽然有提升,但是没有CLIP和ALIGN那么明显。而且模型集成可以提升模型校准,但是model soups没有这种效果。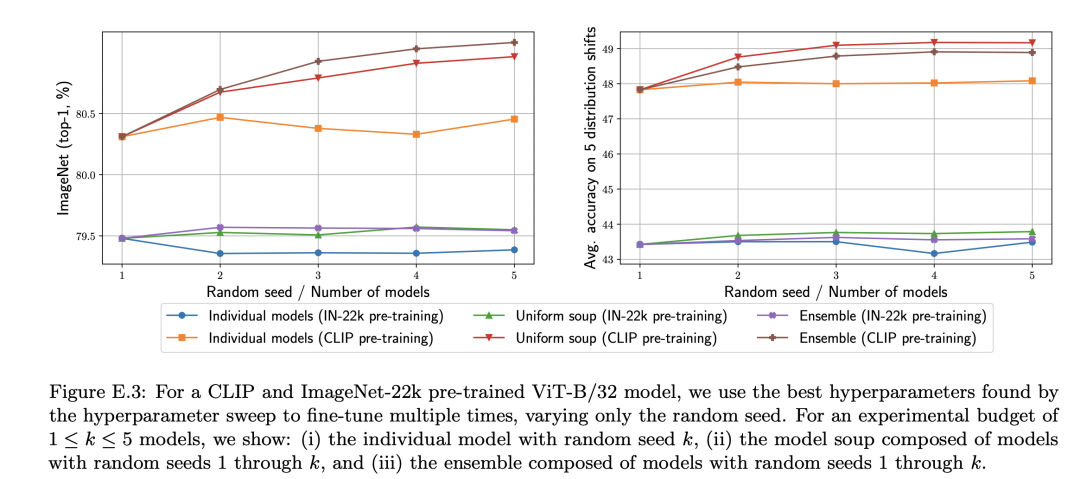 虽然model soups这种方法看起来非常简单,但却比较实用,因为它不像模型集成那样额外增加计算量。对于model soups另外一个点是,虽然我们需要采用不同超参数来产生尽量差异化的模型来进行平均,但是如果两个模型偏离很大,即论文中所说的error barrier(采用较高的学习速率),那么可能就起不到较好的效果,这也就是为什么greedy soup效果会更好的原因,毕竟它可以剔除这种情况。
虽然model soups这种方法看起来非常简单,但却比较实用,因为它不像模型集成那样额外增加计算量。对于model soups另外一个点是,虽然我们需要采用不同超参数来产生尽量差异化的模型来进行平均,但是如果两个模型偏离很大,即论文中所说的error barrier(采用较高的学习速率),那么可能就起不到较好的效果,这也就是为什么greedy soup效果会更好的原因,毕竟它可以剔除这种情况。
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
