 Python绿色通道
Python绿色通道




↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包

文 | 某某白米饭
来源:Python 技术「ID: pythonall」

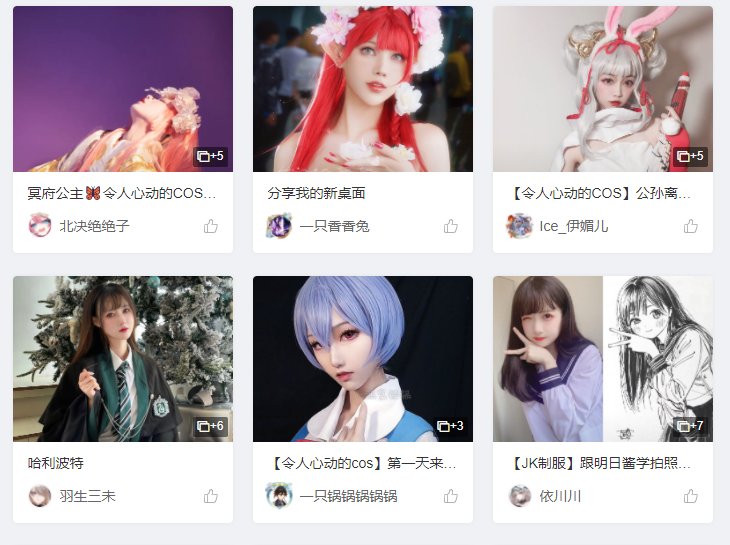
米哈游不仅有原神,还有 coser 小姐姐和 coser 女装大佬,上班的时候用 python 爬虫偷偷下载,加班的时候摸摸鱼,谨防猝死。
防爬虫
打开米哈游的 coser 界面 https://bbs.mihoyo.com/dby/topicDetail/547,并且在打开 F12 控制面板的时候,刷新页面。意外的是居然有 js 的防爬虫机制,表现为如下图:

js 代码是
(function anonymous() {
debugger
})
点击下面的倒数第二个按钮,破解掉它。

列表页
想要快速找到返回页面内容的 url 地址,可以在网络面板中使用 Ctrl+F 查找,然后对呀返回值一条条查看是否是需要的那条,这里找到了一条 getTopicPostList 地址的 url。
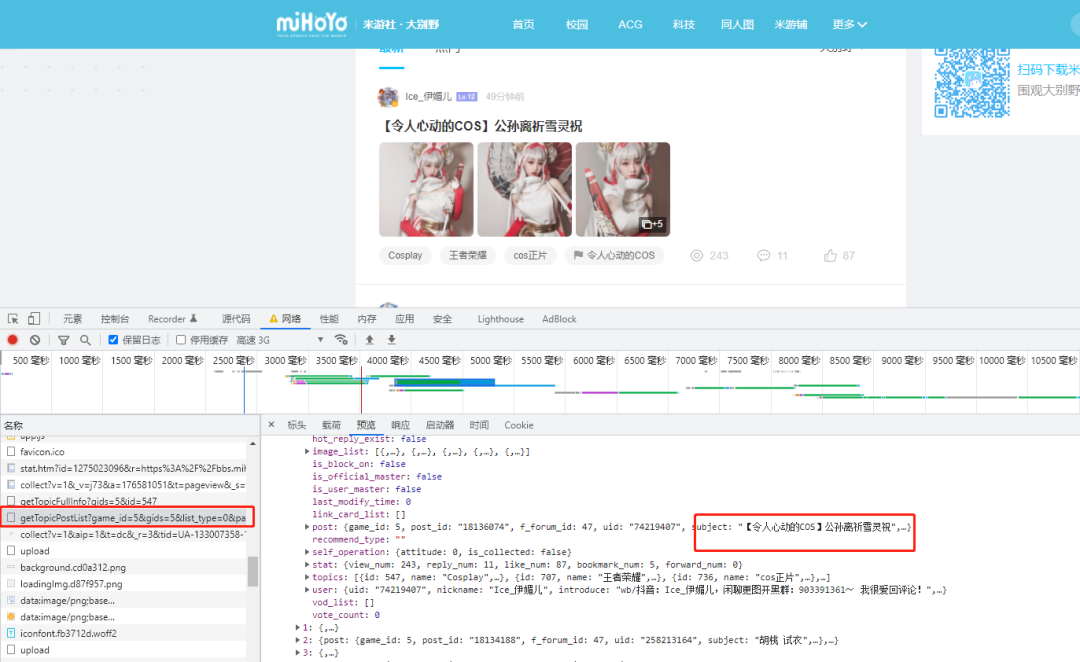
这个页面是没有翻页的,对比第二页的 getTopicPostList 请求地址,比第一个多了 last_id 参数,最终的参数为:
gids: 5,未知 last_id: 18114983,最后一个的 id is_good: false,未知 is_hot: false,是否热门 page_size: 20,每页条数 forum_id: 47,板块 id sort_type: 排序
import requests
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
"Origin": "https://bbs.mihoyo.com",
"Referer": "https://bbs.mihoyo.com/",
"Host": "bbs-api.mihoyo.com"
}
def request_get(url, ret_type):
res = requests.get(url=url, headers=headers, timeout=5)
res.encoding = "utf-8"
if ret_type == "text":
return res.text
elif ret_type == "image":
return res.content
elif ret_type == "json":
return res.json()
def main(last_id):
url = f'https://bbs-api.mihoyo.com/post/wapi/getForumPostList?forum_id=47&gids=5&is_good=false&is_hot=false&last_id={last_id}&page_size=20&sort_type=2'
res_json = request_get(url, "json")
if res_json["retcode"] == 0:
for item in res_json["data"]["list"]:
post_id = item["post"]["post_id"]
detail(post_id)
if res_json["data"]["last_id"] != "":
return main(res_json["data"]["last_id"])
详细页
详细的 url 地址也是返回的 json 串,而且只需要传递 post_id 参数就好了,比较简单。图片的 url 地址就在 ["data"]["post"]["image_list"] 下,在返回的图片中有违规的图片,需要提前处理下。
def detail(post_id):
url = f"https://bbs-api.mihoyo.com/post/wapi/getPostFull?gids=5&post_id={post_id}&read=1"
res_json = request_get(url, "json")
if res_json["retcode"] == 0:
image_list = res_json["data"]["post"]["image_list"]
for img in image_list:
img_url = img["url"]
if (img_url.find("weigui")) < 0:
save_image(img_url)
保存图片
保存图片就是普通的 with open 函数和文件的 write 函数。
def save_image(image_src):
r = requests.get(image_src)
content = r.content
name = image_src.split('/')[-1]
with open('D://mhy//' + name, "wb") as f:
f.write(content)
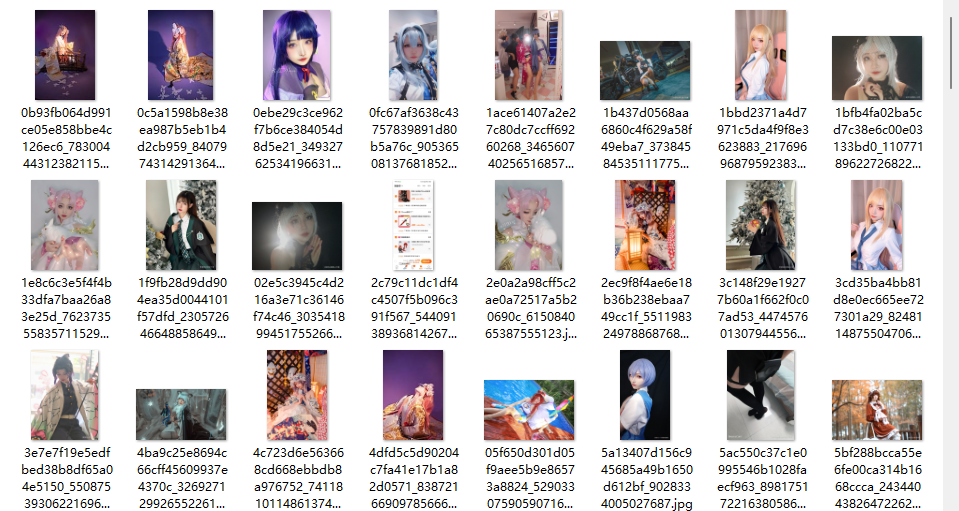
总结
这篇文章的技术就使用了 requests 和 json 以及一点点的控制面板反爬虫。小伙伴们学会了吗?
推荐阅读
您看此文用 
分

秒,转发只需1秒哦

