
面试基操:MQ怎么保障消息可靠性?
Hollis
共 4784字,需浏览 10分钟
· 2022-03-07
RabbitMQ
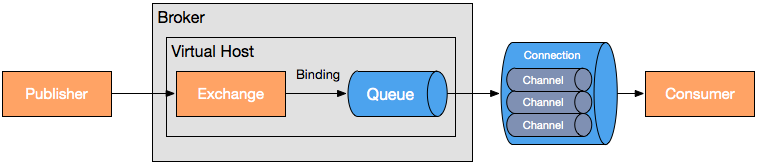
Exchange:接收发布应用程序发送的消息,并根据一定的规则将这些消息路由到消息队列 Queue:存储消息,直到这些消息被消费者安全处理完为止 Binding:定义了exchange和queue之间的关联,提供路由规则
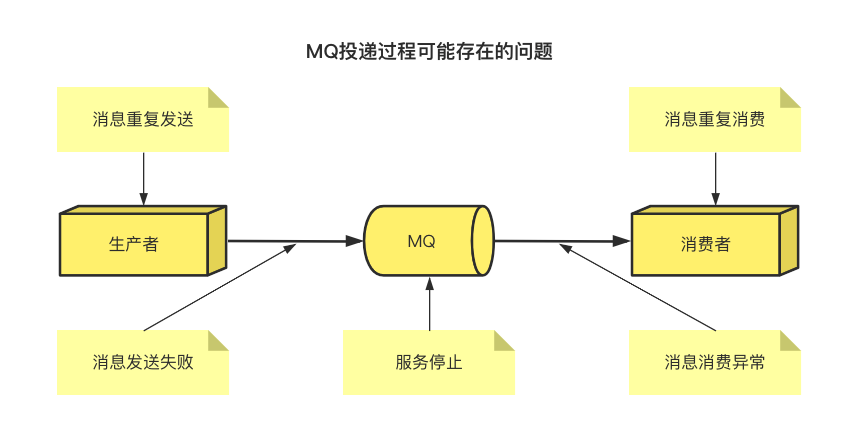
通过API将信道(channel)设置为confirm模式,则每条消息会被分配一个唯—ID 如果消息投递成功,也就是说消息已经到达broker了,信道会发送ack给生产者,回调ConfirmCallback接口,带上唯一ID 如果发生错误导致消息丢失,比如通过某个RoutingKey无法路由到某个Queue,则会发送nack给生产者,回调ReturnCallback接口,并带上唯一ID和异常信息 ack和nack只有一个被触发,只触发一次,而且是异步执行,意味着生产者不需要等待,可以继续发送新消息
声明队列时,指定noack=false, 表示消费者不会自动提交ack,broker会等待消费者手动返回ack、才会删除消息,否则立刻删除 broker的ack没有超时机制,只会判断链接是否断开,如果断开了(比如消费者处理消息过程中宕机),消息会被重新发送,所以消费者要做好消息幂等性处理
交换机持久化:exchange_declare创建交换机时通过参数durable=true指定,如:channel.exchangeDeclare(exchangeName, “direct/topic/header/fanout”, true);第三个参数就是设置durable值 队列持久化:queue_declare创建队列时通过参数durable=true指定,如:channel.queueDeclare("queue.persistent.name", true, false, false, null),第二个参数就是设置durable值 消息持久化:new AMPQMessage创建消息时通过参数指定,如:channel.basicPublish("exchange.persistent", "persistent", MessageProperties.PERSISTENT_TEXT_PLAIN, "persistent_test_message".getBytes()),或者设置参数deliveryMode=2来指定:AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();builder.deliveryMode(2);

Consumer Group:消费者组,消费者组内每个消费者负责消费不同分区的数据,提高消费能力,这是逻辑上的一个订阅者。 Topic:可以理解为一个队列,Topic将消息分类,生产者和消费者面向的是同一个Topic。 Partition:为了实现扩展性,提高并发能力,一个Topic以多个Partition的方式分布到多个Broker上,每个Partition是一个有序的队列,一个Topic的每个Partition都有若干个副本(Replica),一个Leader和若干个Follower;生产者发送数据的对象,以及消费者消费数据的对象,都是通过Leader,Follower负责实时从Leader中同步数据,保持和Leader数据的同步;当Leader发生故障时,某个Follower还会成为新的Leader。
设置ack参数:ack=0,表示不重试,Kafka不需要返回ack,极有可能各种原因造成丢失;ack=1,表示Leader写入成功就返回ack了,Follower不一定同步成功;ack=all或ack=-1,表示ISR列表中的所有Follower同步完成再返回ack。 设置参数unclean.leader.election.enable: false,禁止选举ISR以外的Follower为Leader,只能从ISR列表中的节点中选举Leader;可能会牺牲Kafka的可用性,但是能够提高消息的可靠性。 重试机制,设置tries > 1,表示消息重发次数。 设置最小同步副本数min.insync.replicas > 1,没满足该值前,Kafka不提供读写服务,写操作会异常。
磁盘的顺序读写:与RabbitMQ不同,Kafka是基于磁盘读写的,那为什么Kafka的吞吐量还这么大呢?原因是Kafka的读写是用顺序读写的,不需要寻址随机读写,而由于是用磁盘来写数据,消息堆积能力必然比内存型的RabbitMQ更强 利用了操作系统的零拷贝技术:避免CPU将数据从一块存储拷贝到另外一块存储,关于零拷贝这里不详述,与Java应用不同,Kafka的消息不需要在用户缓冲区处理磁盘数据再返回,所以才能用零拷贝技术 分区分段+索引:Kafka的消息实际上分布存储在一个一个小的segment中的,每次文件读写也是直接操作segment,为了进一步优化查询,Kafka又默认为分段后的数据文件建立了索引文件(就是文件系统上的.index文件),这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度(类似ConcurrentHashMap的分段锁机制)。 批量压缩&批量读写:多条消息一起压缩进行传输(比如gzip格式)与读写,节省带宽 直接操作page cache:虽然Kafka是Java写的,也基于JVM运行,但Kafka的消息读写是直接操作操作系统页存的,而不是在JVM的堆内存,这样就避免JVM的GC耗时及对象创建耗时,且读写速度更高,JVM进程重启缓存也不会丢失
log.flush.interval.messages //多少条消息刷盘1次 log.flush.interval.ms //隔多长时间刷盘1次 log.flush.scheduler.interval.ms //周期性的刷盘。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论