
Pandas在数据分析中的应用
写在文章的最前面,Python办公自动化有什么用?使用Python代码脚本取代繁复的手工操作,自动化,流程化处理数据。本文借助Python中的Pandas库进行数据导入,关于如何学习Pandas,我们可以在其官方文档进行学习,官网的地址如下。
Pandas官网https://www.pypandas.cn/
总结来说,使用pandas可以做数据整理与清洗、数据分析与建模、数据可视化与制表等。
灵活的分组功能:group by数据分组、聚合、转换数据;
直观地合并功能:merge数据连接;
灵活地重塑功能:reshape数据重塑;

一、数据导入、导出
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,usecols=None, squeeze=False,dtype=None,engine=None,converters=None,true_values=None,false_values=None,skiprows=None,nrows=None,na_values=None,parse_dates=False,date_parser=None,thousands=None, comment=None, skipfooter=0, convert_float=True, **kwds)
使用read_excel命令导入数据,写入路径即可导入数据。
#导入数据df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx")df.head()

nrows导入前4行数据。
#导入前4行数据df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",nrows=4)df
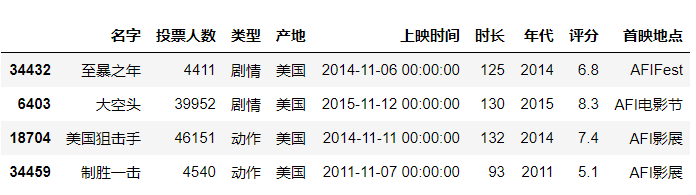
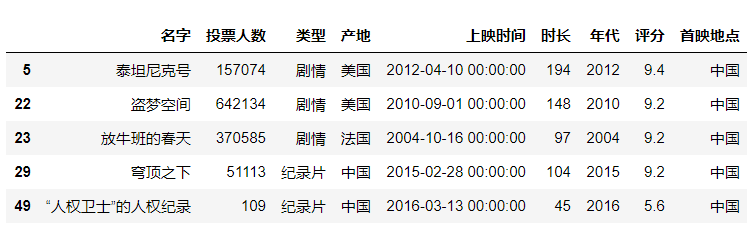
sheet_name指定导入的sheet表,在首映地点中选择中国首映的sheet表。
#导入具体的sheet数据df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",sheet_name = "中国首映")df.head()
header指定第一行是否为列名,header=0,表示数据第一行为列名,header=None,表明数据没有列名。
#header为0时,第一行作为列索引df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",header = 0)df.head()
index_col指定列作为行索引。
#index_col为1时,第二列作为行索引df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",index_col = 1)df.head()

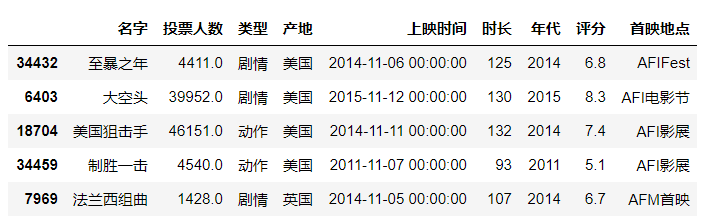
usecols可以指定读取的列名。
#选择第二列,第六列数据df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",usecols =[1,5])df.head()
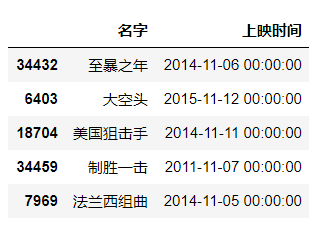
skiprows跳过多少行再读取数据。
#跳过第二行和第四行数据df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",header=0,skiprows=[1,3])df.head()

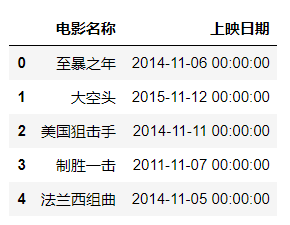
names对选取的列重命名。
#对列命名df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",usecols =[1,5],names=["电影名称","上映日期"])df.head()
数据类型转化
types查看字段的数据类型。
df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx")df.dtypes

dtype转化数据类型。
#转化数据类型df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",dtype={'投票人数':'int','评分':'int'})df.dtypes

数据导出
使用to_excel,写入导出的路径,进行数据导出,index=False消行索引。
import pandas as pda={'销量':[10,20],'售价':[100,200]}df=pd.DataFrame(a)df.to_excel(r'C:\Users\尚天强\Desktop\learn.xlsx',index=False) #取消行索引

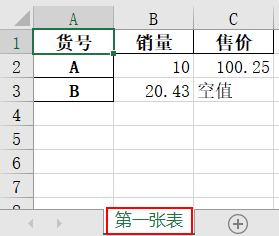
加入行索引,并使用index.name对其命名。
import pandas as pda={'销量':[10,20],'售价':[100,200]}df=pd.DataFrame(a,index=['A','B']) #加入一个行索引df.index.name='货号'df.to_excel(r'C:\Users\尚天强\Desktop\learn.xlsx')

float_format设置浮点型数据的小数位,na_rep空值进行填充。
import pandas as pda={'销量':[10,20.43],'售价':[100.25,None]}df=pd.DataFrame(a,index=['A','B']) #加入一个行索引df.index.name='货号'df.to_excel(r'C:\Users\尚天强\Desktop\learn.xlsx',sheet_name='第一张表',float_format='%.2f',na_rep='空值')
导入.csv文件
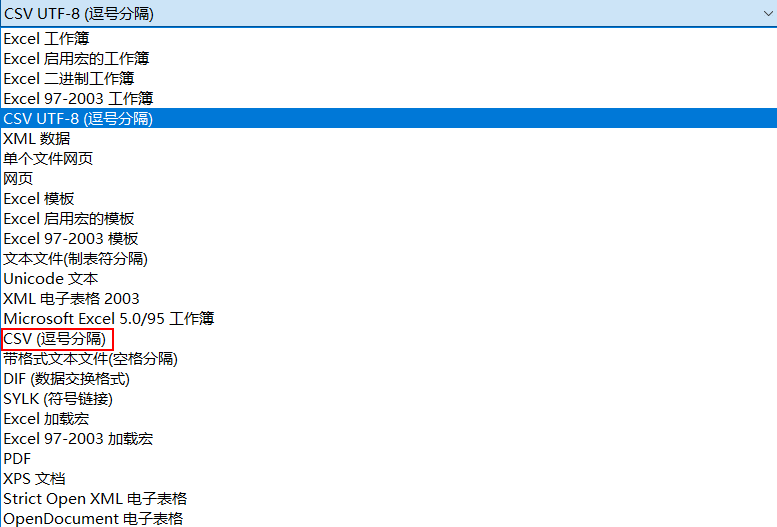
我们常使用的CSV文件有CSV UTF-8(逗号分隔)和CSV(逗号分隔)这两种。
编码方式设置
如果导出的文件为gbk编码方式,导入数据的时候用gbk的编码方式。encoding指定数据读入的编码方式。
# 如果导出的文件为gbk编码方式,导入数据的时候用gbkdf = pd.read_csv(r"C:\Users\尚天强\Desktop\score.csv",encoding="gbk",nrows =2)#导入前两行df
中文路径导入数据
当文件路径或文件名为中文时,如果是CSV UTF-8(逗号分隔)的格式文件,需要把编码格式更改为utf-8-sig,如果是CSV(逗号分隔)的格式文件,需要把编码格式更改为gbk。
当文件路径或文件名为中文时,如果是CSV UTF-8(逗号分隔)的格式文件,需要把编码格式更改为utf-8-sig
如果是CSV(逗号分隔)的格式文件,需要把编码格式更改为gbk 。
df = pd.read_csv(r'C:\Users\尚天强\Desktop\cars_scoreCSV.csv',engine="python",encoding="gbk")df.head()
df = pd.read_csv(r'C:\Users\尚天强\Desktop\cars_scoreUTF-8.csv',engine="python",encoding="utf-8-sig")df.head()
二、数据字段、数据值筛选
一张表会包含很多字段,造成数据冗余,在做数据分析时,我们仅需要提取数据分析所需要的字段,这里就需要用到数据选取的知识点。本文构建数据表做数据索引,然后对数据内容进行调整,包含修改数据类型、去除空格、数据替换、截取字符等,最后做数据规整。
构建数据表
首先导入常用的库,设置一些数据字段,构建一张数据表。
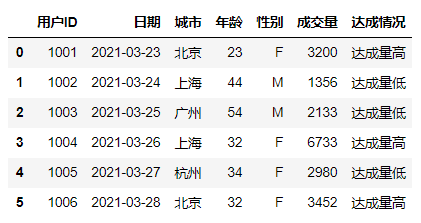
import pandas as pdimport numpy as npimport datetimedf = pd.DataFrame({'用户ID':[1001,1002,1003,1004,1005,1006],'日期':pd.date_range(datetime.datetime(2021,3,23),periods=6),'城市':['北京', '上海', '广州', '上海', '杭州', '北京'],'年龄':[23,44,54,32,34,32],'性别':['F','M','M','F','F','F'],'成交量':[3200,1356,2133,6733,2980,3452]},columns =['用户ID','日期','城市','年龄','性别','成交量'])df
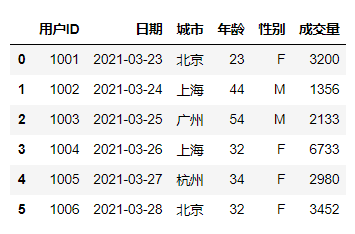
数据索引
将数据索引进行修改,赋值一个列表。
#修改索引,直接赋值给Index即可df.index=list('abcdef')df
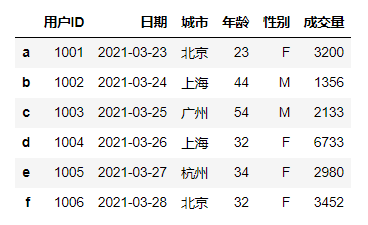
数据索引索引某行
有三种方法,一种是loc按照名字索引,另一种是iloc按照下标索引,Ix是loc和iloc的混合,既能按索引标签提取,也能按位置进行数据提取。
#索引两列df.loc[:,['城市','成交量']]

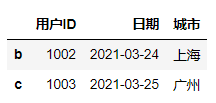
#索引前两行,两列df.loc[['a','b'],['城市','成交量']]

#获取第一列、第二列数据df.iloc[:,0:2]
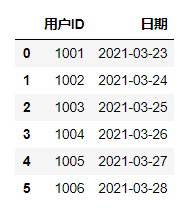
#获取第二行、第三行,第一、二、三列的数据df.iloc[[1, 2],[0, 1, 2]]
# 仅取出第1行的数据df.iloc[0]

#索引全部行数据df.iloc[:,[0, 1, 2]]
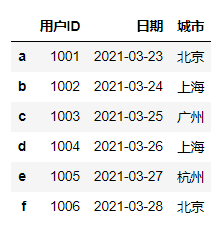
#使用ix按索引标签和位置混合提取数据df.ix[:'2021-03-26',:3]

条件筛选
#筛选性别为F的数据df[df['性别']=='F']
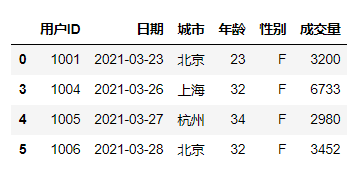
df[(df['城市']=='北京') & (df['年龄']>30)]
#布尔索引加普通索引选择指定的行和列df[df['年龄']>30][['用户ID','城市','成交量']]
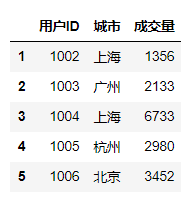
#切片索引加普通索引选择指定的行和列df.iloc[0:3][['用户ID','城市','成交量']]

数值排序
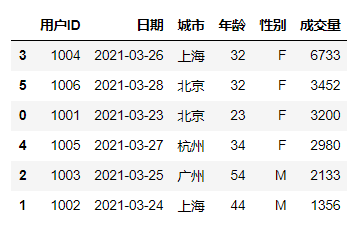
df.sort_values(['成交量'],ascending=False)
数据分类
df['达成情况']=np.where(df['成交量']>3000,'达成量高','达成量低')df
三、数据预处理
数据分析时,首先应对数据进行清洗,这里将数据清洗分为重复值处理、缺失值处理、异常值处理三个部分,重复值处理可删除重复的字段,缺失值处理可以用线性插值、填充为0或用均值填充等,异常值处理用描述性分析、散点图、箱形图、直方图查找异常并处理。本文使用超市商品交易数据,详细介绍重复值处理、缺失值处理、异常值处理的方法,并实际运用数据进行演示,代码操作如下所示。
#导入数据import pandas as pddf=pd.read_csv(r"C:\Users\尚天强\Desktop\超市商品交易.csv",engine="python",encoding="utf-8-sig")df.head()

重复值处理
首先对重复值计数。
df.duplicated().value_counts()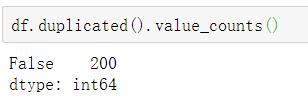
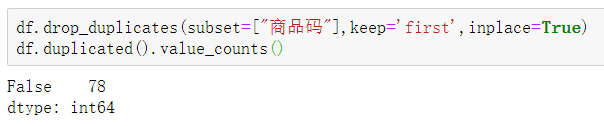
用drop_duplicates的方法对某几列下面的重复行删除,subset:以某列作为基准列,判断是否重复;keep: 保留哪个字段,fisrt参数保留首次出现的数值;inplace: 是否替换当前数据,True选择替换当前数据。
df.drop_duplicates(subset=["商品码"],keep='first',inplace=True)df.duplicated().value_counts()
缺失值处理
通过isnull函数看一下是否有空值,结果是有空值的地方显示为True,没有的显示为False。
df.head(11).isnull()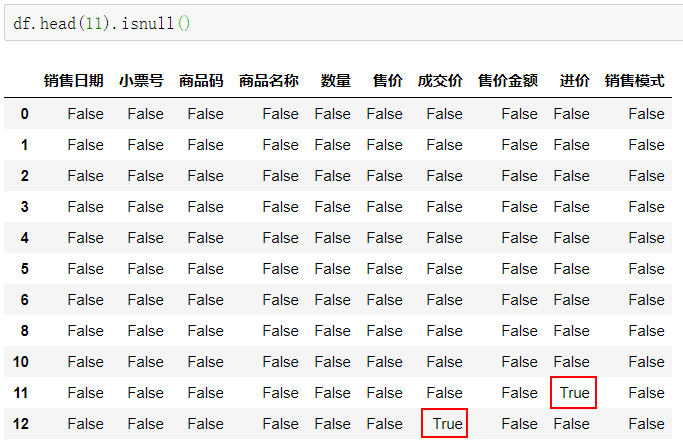
使用info查看各个字段的属性,标记的部分为缺失的部分。
df.info()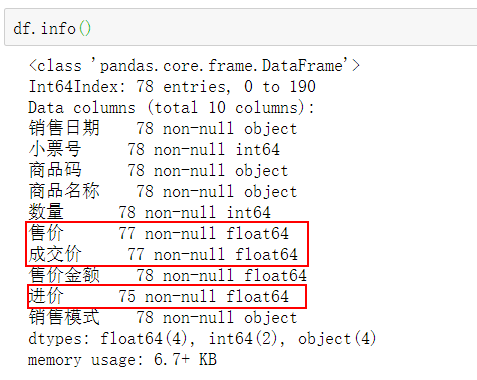
通过isnull().any()查看每一列是否有空值,True返回缺失值。
df.isnull().any()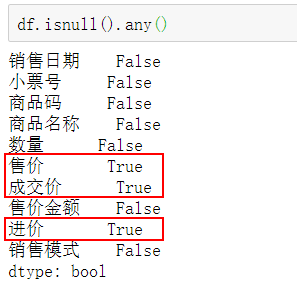
用df.isnull().values==True来定位哪几行是有空值的。
df[df.isnull().values==True]
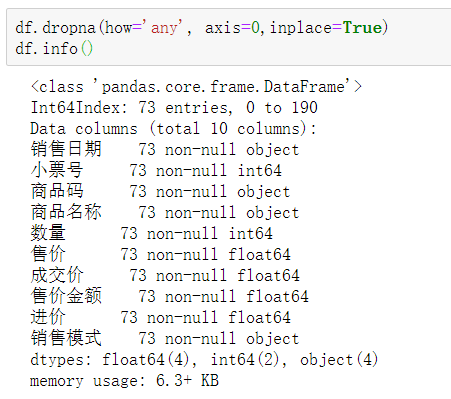
how='any'只要有一个缺失值就删除,axis=0,删除的是行,默认删除的是行,inplace=True替换原始数据。
df.dropna(how='any', axis=0,inplace=True)df.info()
缺失值填充
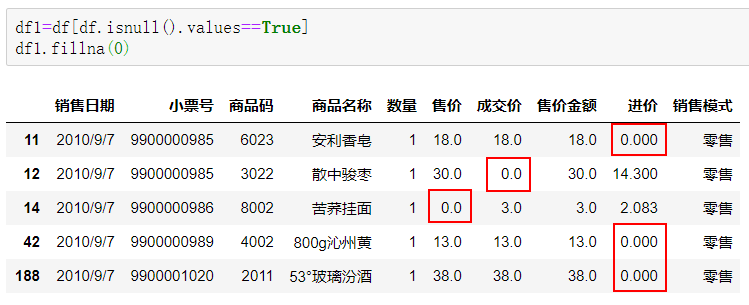
fillna(0)用0对缺失值进行填充。
df1=df[df.isnull().values==True]df1.fillna(0)
limit用来限定填充的数量。
df1.fillna(0,limit=3)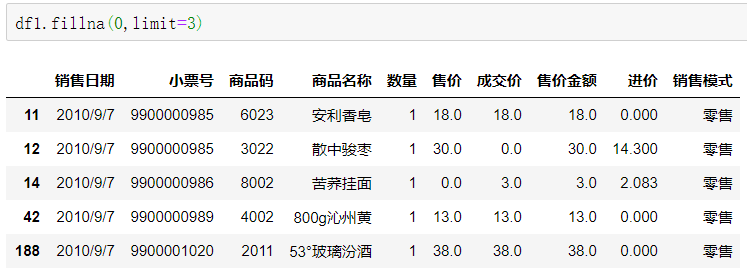
{ }对不同的列填充不同的值,其中键作为列,值作为缺失值填充的值。
df1.fillna({"售价":0 ,"成交价":0 ,"进价": "#N/A"})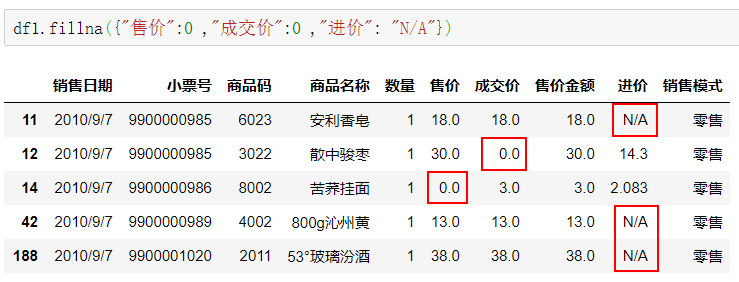
method方法使用ffill,表示用前一个值作为填充的值。
df1.fillna(method="ffill")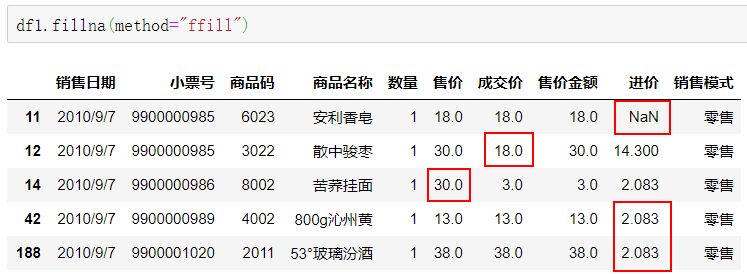
median方法使用中位数的值进行填充。
df1.fillna(df1.median())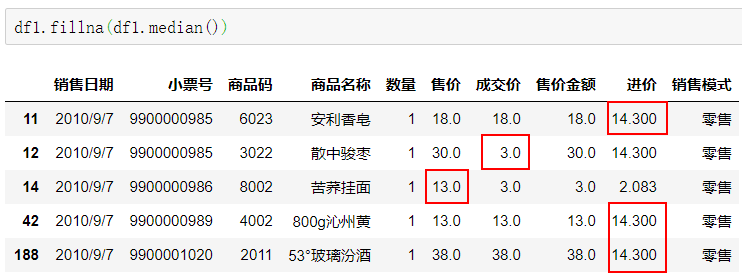
interpolate表示线性插值。
df[df.isnull().values==True].interpolate() #线性插值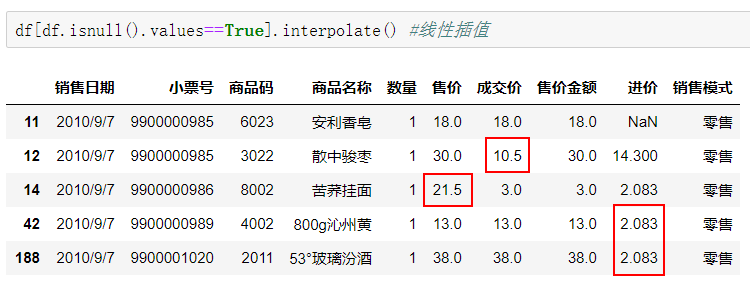
四、数据可视化
对于一些异常值的处理,可以使用散点图和箱线图进行数据标记,describe( )对统计字段进行描述性分析,从平均值、标准差,看数据的波动情况,最大值查看数据的极值。
df[['售价','进价']].describe()
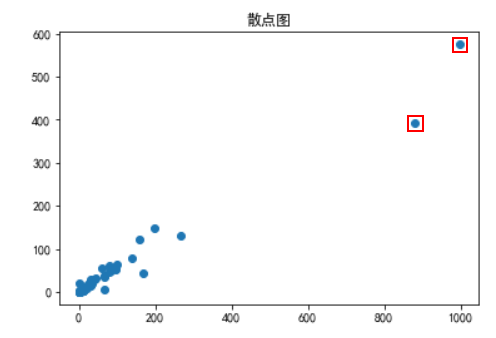
散点图
做出散点图,查看数据中异常的点,图中标记的点就是异常的点。
from matplotlib import pyplot as pltplt.rcParams["font.sans-serif"]='SimHei' #解决中文乱码问题plt.scatter(df["售价"], df["进价"])plt.title("散点图",loc = "center")plt.show()
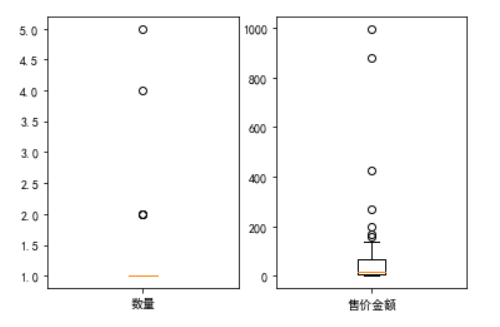
箱线图
做出箱线图,反映原始数据分布的特征。
plt.subplot(1,2,1)plt.boxplot(df["数量"],labels = ["数量"])plt.subplot(1,2,2)plt.boxplot(df["售价金额"],labels = ["售价金额"])plt.show()
折线图
做售价金额的折线图,售价金额呈波动趋势。
plt.plot(df["售价金额"])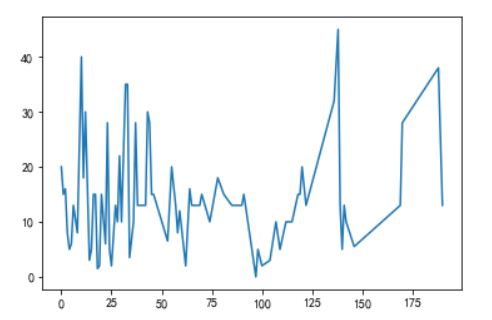
用箱形图的办法,超过了上四分位1.5倍四分位距或下四分位1.5倍距离都算异常值,用中位数填充。
import numpy as npa = df["售价金额"].quantile(0.75)b = df["售价金额"].quantile(0.25)c = df["售价金额"]c[(c>=(a-b)*1.5+a)|(c<=b-(a-b)*1.5)]=np.nanc.fillna(c.median(),inplace=True)c.describe()

用标准差和均值,定义超过4倍就算异常值,同样用中位数填充。
a = df["售价金额"].mean()+df["售价金额"].std()*4b = df["售价金额"].mean()-df["售价金额"].std()*4c = df["售价金额"]c[(c>=a)|(c<=b)]=np.nanc.fillna(c.median(),inplace=True)c.describe()

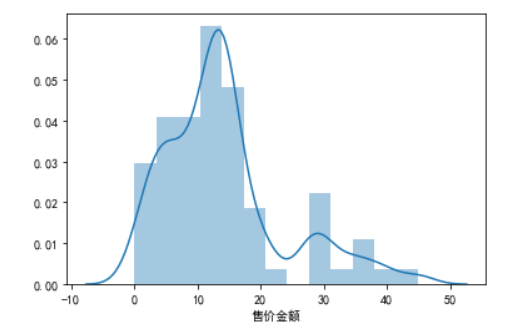
import seaborn as snssns.distplot(df['售价金额'])#解决负号无法正常显示问题plt.rcParams["axes.unicode_minus"]= Falseplt.show()
对比Excel系列图书累积销量达15w册,让你轻松掌握数据分析技能,可以在全网搜索书名进行了解:
