
Disruptor高性能之道-等待策略
共 1718字,需浏览 4分钟
· 2022-03-06
我们接着介绍Disruptor高性能实现之道--等待策略。
❝等待策略waitStrategy是一种决定一个消费者如何等待生产者将event对象放入Disruptor的方式/策略。
等待策略waitStrategy是一个接口,它的所有实现都是针对消费者生效的。
❞
Disruptor中主要的等待策略有哪些?
Disruptor中,等待策略waitStrategy有四个实现,分别是:
BlockingWaitStrategy:使用锁和条件变量实现的阻塞策略。如果不是将吞吐量和低延迟放在首位,则可以使用该策略。一般来说,这个策略的表现是中规中矩比较稳定的,它不会使CPU的负载飙高。
❝虽然客观上说, BlockingWaitStrategy是最低效的策略,但其也是CPU使用率最低和最稳定的策略。
在BlockingWaitStrategy内部维护了一个重入锁ReentrantLock和Condition;
❞
SleepingWaitStrategy:性能表现和com.lmax.disruptor.BlockingWaitStrategy差不多,对CPU的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景;
❝SleepingWaitStrategy是一种无锁的方式,它的CPU使用率也比较低。具体的实现原理为:循环等待并且在循环中间调用LockSupport.parkNanos(1)来睡眠,(在Linux系统上面睡眠时间60µs).
SleepingWaitStrategy优点在于生产线程只需要计数,而不执行任何指令。并且没有条件变量的消耗。但是,事件对象从生产者到消费者传递的延迟变大了。SleepingWaitStrategy最好用在不需要低延迟,而且事件发布对于生产者的影响比较小的情况下。比如异步日志功能。
❞
YieldingWaitStrategy:性能最好,适合用于低延迟的系统,在要求极高性能且事件处理线程数小于CPU逻辑核心数的场景中推荐使用此策略,例如CPU开启超线程的特性;
❝虽然YieldingWaitStrategy性能最好,但是它的实现机制是让出cpu使用权,保证cpu不会空闲,从而使得cpu始终处于工作态,因此该策略会使用100%的CPU,因此建议慎用。
❞
BusySpinWaitStrategy:该策略原则上来说应当是性能最高的,它将线程绑定在特定的CPU内核,但是同时该策略也是部署过程中最为苛刻的策略。
❝BusySpinWaitStrategy发挥高性能的前提是事件处理线程比物理内核数目还要小的场景。例如:在禁用超线程技术的时候。
❞
BlockingWaitStrategy
❝BlockingWaitStrategy是Disruptor中唯一使用到锁的地方。
❞
public final class BlockingWaitStrategy implements WaitStrategy
{
// 可重入锁
private final Lock lock = new ReentrantLock();
// 条件变量
private final Condition processorNotifyCondition = lock.newCondition();
@Override
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
if (cursorSequence.get() < sequence)
{
lock.lock();
try
{
while (cursorSequence.get() < sequence)
{
barrier.checkAlert();
processorNotifyCondition.await();
}
}
finally
{
lock.unlock();
}
}
// 如果生产者新发布了事件,但是依赖的其他消费者还没处理完,则等待所依赖的消费者先处理
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking()
{
lock.lock();
try
{
processorNotifyCondition.signalAll();
}
finally
{
lock.unlock();
}
}
BlockingWaitStrategy的类长度不到100行,使用了Lock+Condition 实现了线程等待和唤醒操作。从而实现了生产者与消费者之间的同步。
消费者通过waitFor等待RingBuffer指定位置是否有可用数据,当存在可用数据,则消费者被唤醒。
/**
* @see Sequencer#publish(long)
*/
@Override
public void publish(long sequence)
{
cursor.set(sequence);
waitStrategy.signalAllWhenBlocking();
}
如果生产者新发布了事件,但是依赖的其他消费者还没处理完,则等待所依赖的消费者先处理 生产者新发布时间,会唤醒等待中的消费者。
SleepingWaitStrategy
SleepingWaitStrategy没有用到锁,这表明它无需调用signalAllWhenBlocking方法做唤醒处理。
❝SleepingWaitStrategy核心是通过「Thread.yield」 + 「LockSupport.parkNanos」,实现生产者和消费者之间的同步。
❞
也就是说省去了生产线程的通知操作,官方源码注释如下:
* This strategy is a good compromise between performance and CPU resource.
* Latency spikes can occur after quiet periods. It will also reduce the impact
* on the producing thread as it will not need signal any conditional variables
* to wake up the event handling thread.
大意是说,SleepingWaitStrategy策略在性能和CPU资源消耗之间取得了平衡,接下来去看看关键代码。
private static final int DEFAULT_RETRIES = 200;
private static final long DEFAULT_SLEEP = 100;
private final int retries;
private final long sleepTimeNs;
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException
{
long availableSequence;
int counter = retries; // 默认值为DEFAULT_RETRIES = 200;
while ((availableSequence = dependentSequence.get()) < sequence)
{
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking()
{
}
waitFor 方法核心是while循环,我们可以看到,while循环没有任何的break操作,他就是个死循环。
counter默认值为200,自旋重试一定次数,如果在重试过程中,出现了可用sequence,也就是生产者往RingBuffer中生产了数据,则直接返回可用的序列号。
只要消费者没有等到可用的数据,就会一直循环,执行applyWaitMethod。
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
barrier.checkAlert();
if (counter > 100)
{
--counter;
}
else if (counter > 0)
{
--counter;
Thread.yield();
}
else
{
LockSupport.parkNanos(sleepTimeNs);
}
return counter;
}
这里的核心就是counter计数器,完全是无锁的。
当计数器高于100时就执行减一的操作(最快响应),当计数器在100到0之间时每次都交出CPU执行时间(最省资源),其他时候就睡眠固定时间:
如果重试指定次数以后,还是没有可用序列号,则继续自旋重试:
0-100:每重试一次,便调用Thread.yield方法,让渡CPU的使用权,让其它线程可以使用CPU。当该线程再次获取CPU使用权时,继续重试,如果还没有可用的序列号,则继续放弃CPU使用权等待。此循环最多100次。 假如在等待过程中还是没有可用的序列号,则调用LockSupport.parkNanos方法阻塞消费线程,阻塞时长通过SleepingWaitStrategy构造方法设置,一直阻塞到出现了可用的sequence(一直阻塞到生产者生产了数据)。 当LockSupport.parkNanos方法由于超时返回后,还没有可用的sequence序列号,则该线程获取CPU使用权以后,可能继续调用LockSupport.parkNanos方法阻塞线程。
跟其它几种等待策略相比,它既没有直接使用锁,也没有直接自旋。属于一种在性能和CPU资源之间折中的方案。
BusySpinWaitStrategy
❝BusySpinWaitStrategy的实现代码行数只有几十行,从它的注释可以看出: 该策略将线程绑定到了特定的CPU内核。
❞
/**
* Busy Spin strategy that uses a busy spin loop for {@link EventProcessor}s waiting on a barrier.
*
* This strategy will use CPU resource to avoid syscalls which can introduce latency jitter. It is best
* used when threads can be bound to specific CPU cores.
*/
public final class BusySpinWaitStrategy implements WaitStrategy
{
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking()
{
}
}
当没有可用sequence时,消费者会一直执行while循环,具体的逻辑为 「ThreadHints.onSpinWait();」
private static final MethodHandle ON_SPIN_WAIT_METHOD_HANDLE;
public static void onSpinWait()
{
// Call java.lang.Thread.onSpinWait() on Java SE versions that support it. Do nothing otherwise.
// This should optimize away to either nothing or to an inlining of java.lang.Thread.onSpinWait()
if (null != ON_SPIN_WAIT_METHOD_HANDLE)
{
try
{
ON_SPIN_WAIT_METHOD_HANDLE.invokeExact();
}
catch (final Throwable ignore)
{
}
}
}
当ON_SPIN_WAIT_METHOD_HANDLE 不为空,则执行 ON_SPIN_WAIT_METHOD_HANDLE.invokeExact(); 底层是一个native方法。
那么我们可以猜想,如果ON_SPIN_WAIT_METHOD_HANDLE为空,那么这个外层的while循环就是一个纯粹的自旋操作,也就是说这个操作非常消耗CPU。
ON_SPIN_WAIT_METHOD_HANDLE为空是一个比较严重的场景,它的初始化逻辑为:
# com.lmax.disruptor.util.ThreadHints
static
{
final MethodHandles.Lookup lookup = MethodHandles.lookup();
MethodHandle methodHandle = null;
try
{
methodHandle = lookup.findStatic(Thread.class, "onSpinWait", methodType(void.class));
}
catch (final Exception ignore)
{
}
ON_SPIN_WAIT_METHOD_HANDLE = methodHandle;
}
可以看到,这里的methodHandle其实就是Thread类中的onSpinWait方法,
如果Thread类没有onSpinWait方法那么使用BusySpinWaitStrategy作为等待策略就在RingBuffer中没有数据时,消费线程就会执行自旋空转,这个操作很耗费CPU。
❝那么问题就变成了,Thread类中是否存在「onSpinWait」 方法的问题了。
❞
有趣的是,onSpinWait方法在JDK1.9之后才添加到了Thread类中,也就是说,对于JDK1.8(包括1.8)之前的用户而言,使用BusySpinWaitStrategy就意味着,找不到Thread类的onSpinWait方法,而最终导致消费者阻塞在waitFor方法上,执行无意义的自旋操作,把CPU负载打满(就是一个while(true)死循环)。
❝在jdk1.9及以上版本中,Thread.onSpinWait是有意义的。它会通知CPU当前线程处于循环查询的状态,CPU得知该状态后就会调度更多CPU资源给其他线程,从而缓解死循环对当前cpu核的压力。
❞
回过头来,BusySpinWaitStrategy的注释告诉我们:如果使用该策略,尽量绑定线程到固定的CPU核心。但是同样的,该策略与YieldingWaitStrategy策略相比,会出现当没有可用序列号时长期占用CPU而让出CPU使用权(死循环),导致其它线程无法获取CPU使用权。
如何实现利用线程亲和性绑定线程到具体的CPU?
那么这个操作又该如何实现呢?
❝通过使用net.openhft.affinity包,就可以实现线程亲和性,它会强制你的应用线程运行在特定的一个或多个cpu上。
❞
maven依赖为:
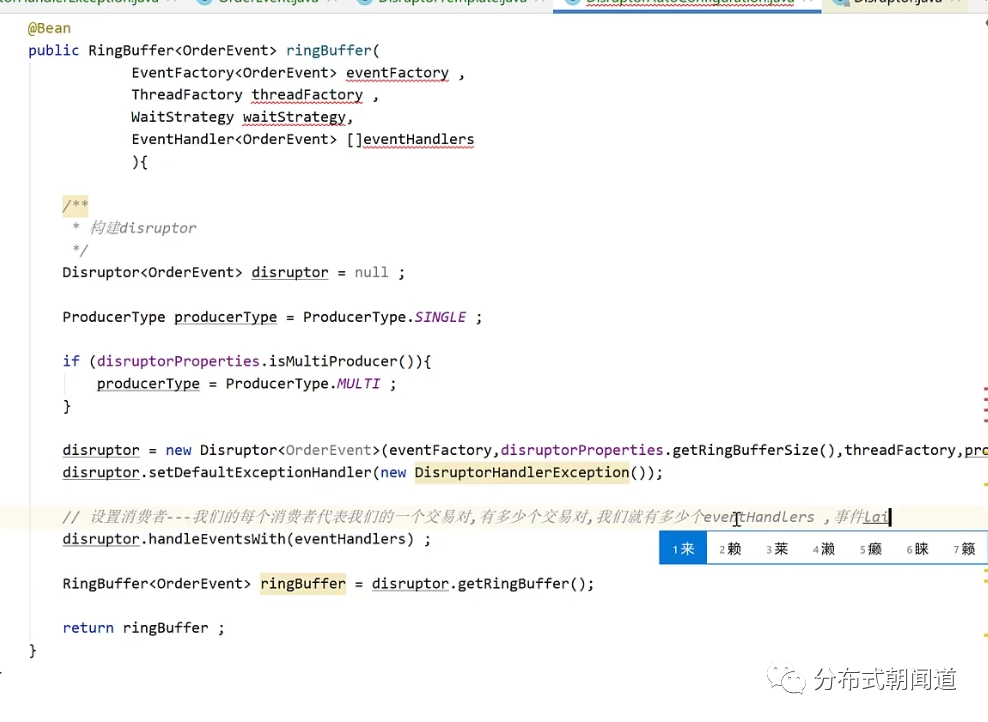
在初始化Disruptor实例时,ThreadFactory参数传入affinity线程亲和工厂。
❝以Spring项目中实例化Disruptor为例:
❞

YieldingWaitStrategy
❝YieldingWaitStrategy相比于SleepingWaitStrategy,实现机制就很激进,它完全基于Thread.yield出让cpu使用权,让CPU利用率保持在100%。
❞
public final class YieldingWaitStrategy implements WaitStrategy
{
private static final int SPIN_TRIES = 100;
@Override
public long waitFor(
final long sequence, Sequence cursor, final Sequence dependentSequence, final SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
int counter = SPIN_TRIES;
while ((availableSequence = dependentSequence.get()) < sequence)
{
counter = applyWaitMethod(barrier, counter);
}
return availableSequence;
}
@Override
public void signalAllWhenBlocking()
{
}
当消费者没有获取到可用的sequence,则循环执行applyWaitMethod。直到存在可用的sequence,就返回该sequence。
返回sequence之后就可以根据该sequence从RingBuffer中get出这个sequence对应的event,执行业务操作。
private int applyWaitMethod(final SequenceBarrier barrier, int counter)
throws AlertException
{
barrier.checkAlert();
// counter默认为100,在减小到0之前不会进入if分支
if (0 == counter)
{
Thread.yield();
}
else
{
--counter;
}
return counter;
}
}
首先,counter默认为100,在减小到0之前不会进入if分支,直接进入else,执行减1操作。
❝也就是说,首先会自旋重试100次(此值可设置,默认100次),如果在重试过程中,存在可用的序列号,则直接返回可用的序列号。
❞
如果自旋了100次,counter减到0了,还是没有得到可用的sequence序列号,那么就会调用Thread.yield方法,让渡CPU的使用权,让其它线程可以争抢到CPU使用权。当该线程再次获取CPU使用权时,继续该过程:如果没有可用的序列号,则继续放弃CPU使用权等待。
❝从分析我们可以看出,YieldingWaitStrategy基本上是在等待sequence期间,不断的通过Thread.yield出让CPU的使用权,因此这个策略会让CPU使用率保持在100%的满负荷,生产中强烈推荐 「不要使用」 !
❞
盘点等待策略
BlockingWaitStrategy:基于ReentrantLock的等待&&唤醒机制实现等待逻辑,该策略是Disruptor的默认策略,比较节省CPU,生产环境推荐使用; BusySpinWaitStrategy:持续自旋,不推荐使用,会造成CPU负载100%; DummyWaitStrategy:返回的Sequence值为0,正常情况下不使用 LiteBlockingWaitStrategy:基于BlockingWaitStrategy的轻量级等待策略,在没有锁竞争的时候会省去唤醒操作,但是作者说测试不充分,因此不建议使用 TimeoutBlockingWaitStrategy:带超时的等待策略,超时后会执行业务指定的处理逻辑 LiteTimeoutBlockingWaitStrategy:基于TimeoutBlockingWaitStrategy的策略,当没有锁竞争的时候会省去唤醒操作 SleepingWaitStrategy:三段式策略,第一阶段自旋,第二阶段执行Thread.yield让出CPU,第三阶段睡眠执行时间,反复的睡眠 YieldingWaitStrategy:二段式策略,第一阶段自旋,第二阶段执行Thread.yield交出CPU PhasedBackoffWaitStrategy:四段式策略,第一阶段自旋指定次数,第二阶段自旋指定时间,第三阶段执行Thread.yield交出CPU,第四阶段调用成员变量的waitFor方法,该成员变量可以被设置为BlockingWaitStrategy、LiteBlockingWaitStrategy、SleepingWaitStrategy三个中的一个
扩展:单一写原则
在并发系统中提高性能最好的方式之一就是单一写原则,Disruptor中的生产者就体现了这一原则。
如果在你的代码中仅仅有一个事件生产者,那么可以设置为单一生产者模式来提高系统的性能。
单一写的好处在于:完全不需要考虑同步多个写线程,写入操作没有上下文切换,并且是线程安全的(写入串行化)。
关于单一写原则,可以阅读:https://mechanical-sympathy.blogspot.com/2011/09/single-writer-principle.html