 蚂蚁学Python
蚂蚁学Python




前言
学了一段时间爬虫,终于把进程、线程、协程给搞明白了,还没搞明白的强烈推荐看一下蚂蚁老师B站的视频:https://www.bilibili.com/video/BV1bK411A7tV?p=1,思路很清晰。爬虫属于IO密集型任务,且资源开销少,对于爬虫来说很有优势,对于使用爬虫下载视频,那效率就更高了。我们以人人影视最新一集的国王排名为例:https://www.rryy123.com/play/40479-1-18.html
一,页面分析
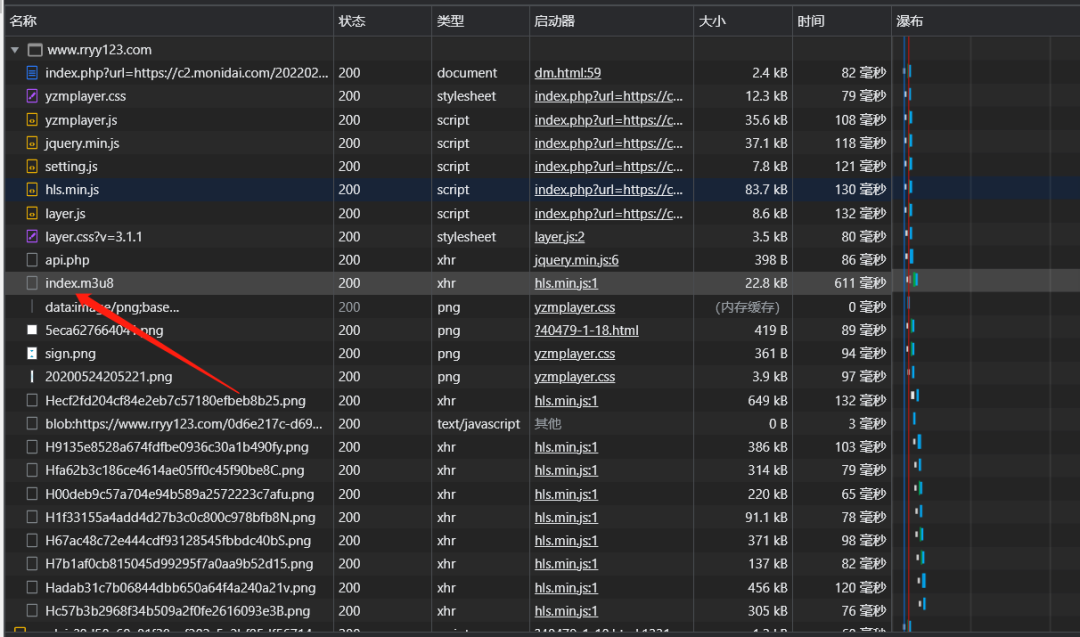
通过抓包我们很容易发现index.m3u8这个包,但是响应内容却没显示可用的数据。为了验证一下我们对这个网址https://c2.monidai.com/20220225/yOm07IlJ/index.m3u8发起请求,并保存为m3u8格式,打开发现得到的结果如下:
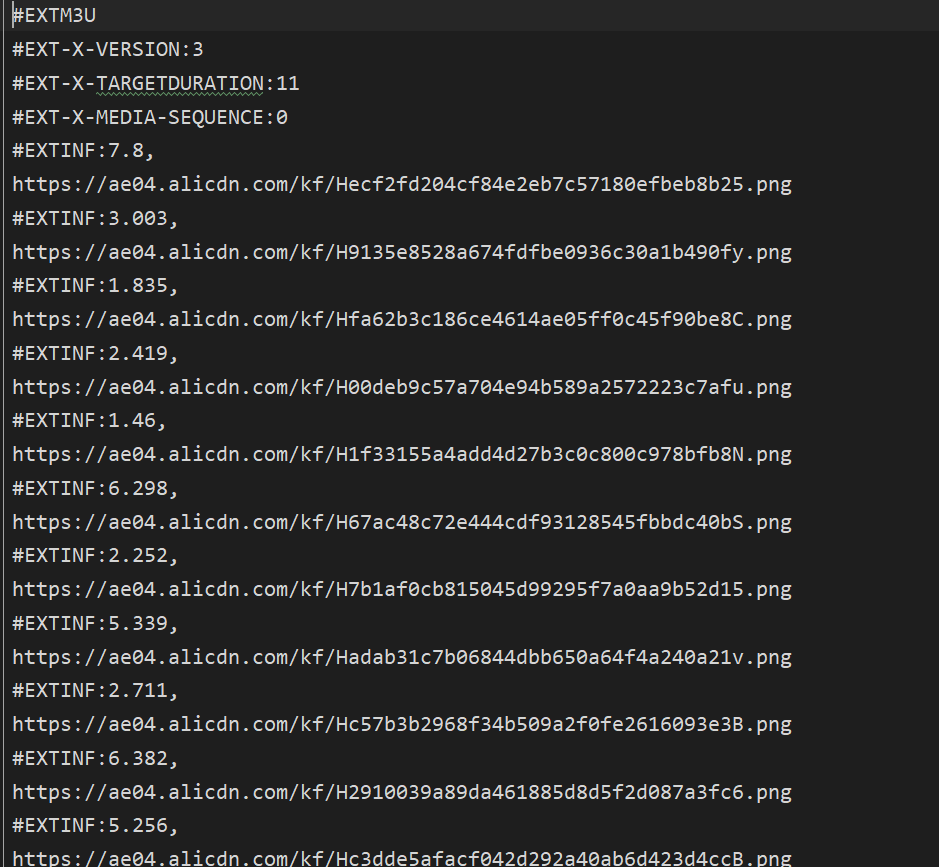
但是发现里面的网址是以png结尾?于是我们对上面的一个网址发起请求进行验证,并以二进制写入文件,文件名后缀以.ts结尾。下载完成后打开正是我们想要的视频文件!
那如何通过视频的URL定位到index.m3u8地址呢?通过检查网页源代码,搜索关键字m3u8很容易就定位到,如下图:
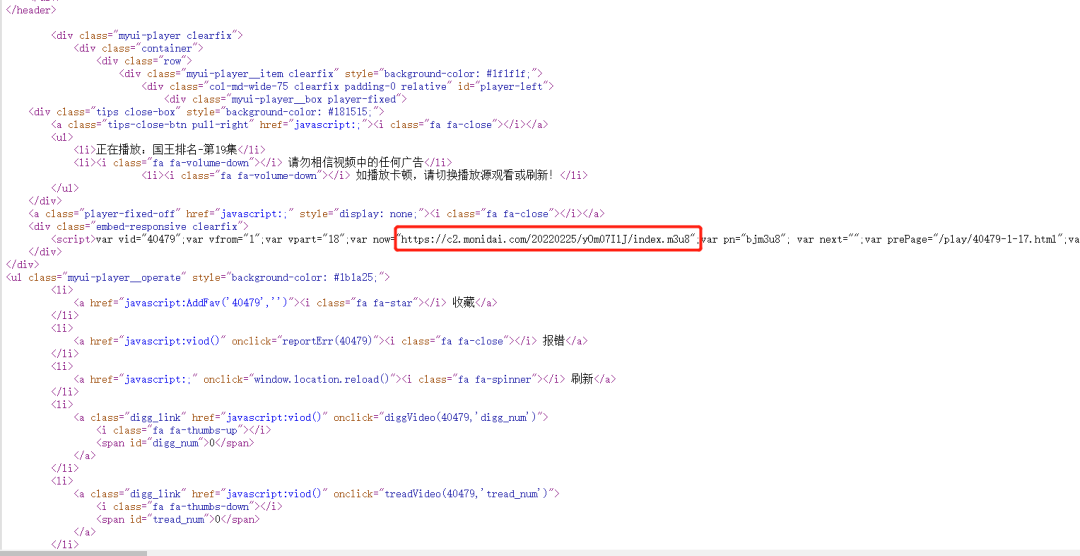
至此,第一步我们已经完成,通过正则匹配可以获得对应地址,代码如下:
def get_m3u8_url(self):
# 根据剧集网址,获取m3u8下载索引
res =requests.get(url=self.url,headers=self.headers).text
first_m3u8_url = re.findall(';var now="(.*?)"',res,re.S)[0] # 获取m3u8下载地址
self.name = re.findall("<li>正在播放:(.*?)</li>",res,re.S)[0] # 获取下载片名
print(self.name+"准备开始下载")
res_second = requests.get(url=first_m3u8_url,headers=self.headers).text
with open(self.name+".m3u8",'w',encoding='utf-8') as f:
f.write(res_second)
二,获取m3u8播放列表
根据上一步下载的m3u8文件,提取下载地址,代码如下:
def get_ts_url(self):
# 根据m3u8下载索引,获取各个下载地址
ts_url_list = []
with open(self.name+".m3u8",'r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'):
continue
line = line.strip()
ts_url_list.append(line)
return ts_url_list
三,编码实现
然后下一步我们就开始下载视频了,完整代码如下:
# -*- coding:utf-8 -*-
import time
import re
import os
import requests
import asyncio
import aiohttp
import aiofiles
import nest_asyncio
nest_asyncio.apply()
class RRyy123:
def __init__(self):
self.url = None
self.name = None
self.headers = {'User-Agent':'Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 95.0.4638.69Safari / 537.36'}
def get_m3u8_url(self):
# 根据剧集网址,获取m3u8下载索引
res =requests.get(url=self.url,headers=self.headers).text
first_m3u8_url = re.findall(';var now="(.*?)"',res,re.S)[0] # 获取m3u8下载地址
self.name = re.findall("<li>正在播放:(.*?)</li>",res,re.S)[0] # 获取下载片名
print(self.name+"准备开始下载")
res_second = requests.get(url=first_m3u8_url,headers=self.headers).text
with open(self.name+".m3u8",'w',encoding='utf-8') as f:
f.write(res_second)
def get_ts_url(self):
# 根据m3u8下载索引,获取各个ts文件地址
ts_url_list = []
with open(self.name+".m3u8",'r',encoding='utf-8') as f:
for line in f:
if line.startswith('#'):
continue
line = line.strip()
ts_url_list.append(line)
return ts_url_list
async def download_ts(self,url,session,sem):
# 使用协程下载单个ts文件
ts_name = os.path.splitext(url)[0].split("/")[-1]
async with sem: # 控制协程信号量
async with session.get(url =url) as res:
if not os.path.exists(f"./temp_{self.name}"):
os.makedirs(f"./temp_{self.name}/")
async with aiofiles.open(f"./temp_{self.name}/{ts_name}.ts",'wb') as f:
await f.write(await res.read())
print(f"{ts_name}.ts下载完成")
async def main(self):
# 根据m3u8文件中的ts网址,下载ts视频
tasks = []
self.get_m3u8_url()
ts_url_list = self.get_ts_url()
sem = asyncio.Semaphore(5) # 设置信号量,控制异步数量
async with aiohttp.ClientSession(headers=self.headers) as session:
for ts_url in ts_url_list:
tasks.append(asyncio.create_task(self.download_ts(url=ts_url,session=session,sem=sem)))
await asyncio.wait(tasks)
if __name__ == '__main__':
t = time.time()
f = RRyy123()
f.url = "https://www.rryy123.com/video/?40479-1-18.html"
asyncio.run(f.main())
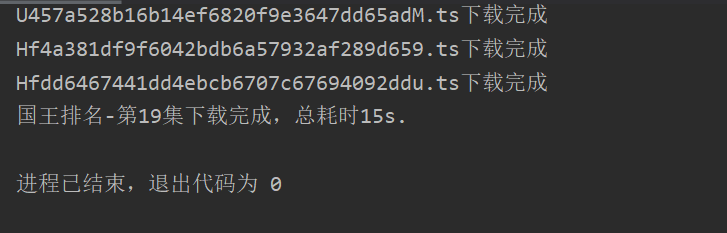
print(f"{f.name}下载完成,总耗时{int(time.time()-t)}s.")
我这是测了一下,下载一个128M的文件只要15s!!!
四,ts文件合并
下载完成后我们要对ts文件进行合并了,这里推荐使用ffmpeg,windows下载地址:http://ffmpeg.org/download.html#build-windows。这里要注意的是 将解压后的文件目录中 bin 目录(包含 ffmpeg.exe )添加进 path 环境变量中。使用 ffmpeg 合并ts 文件方法非常简单,只需要在终端输入一行命令:
ffmpeg -f concat -i filename.txt -c copy output.mp4
首先在ts文件相同目录中,把所有要合并的ts文件名保存在filename.txt:如下图:
然后使用命令行进行合并,这里要注意文件路径,合并完成后删除ts文件,这里为了防止误删使用send2trash库,删除内容可以放进回收站,代码如下:
import send2trash
import os
def merge_video(name):
# 合并视频
ts_url_list=[]
with open(name + ".m3u8", 'r', encoding='utf-8') as f:
for line in f:
if line.startswith('#'):
continue
line = line.strip()
ts_url_list.append(line)
f = open(f"./temp_{name}/filename.txt" ,'w' ,encoding="utf-8")
for ts_url in ts_url_list:
ts_name = os.path.splitext(ts_url)[0].split("/")[-1]
f.write("file "+ ts_name +".ts\n")
f.close()
print(f"{name}开始合并。。。。")
os.system(f"ffmpeg -f concat -i ./temp_{name}/filename.txt -c copy {name}.mp4")
print(f"{name}视频合成成功")
def remove_temp(name):
# 删除ts文件,放入回收站
send2trash.send2trash(f"./temp_{name}")
send2trash.send2trash(f"{name}.m3u8")
print("临时文件已删除。")
if __name__ == '__main__':
name = "国王排名-第19集"
merge_video(name)
remove_temp(name)
最后,推荐蚂蚁老师的Python课程:

如果购买课程,加微信:ant_learn_python
找蚂蚁老师,进群、领资料

