 大邓和他的Python
大邓和他的Python





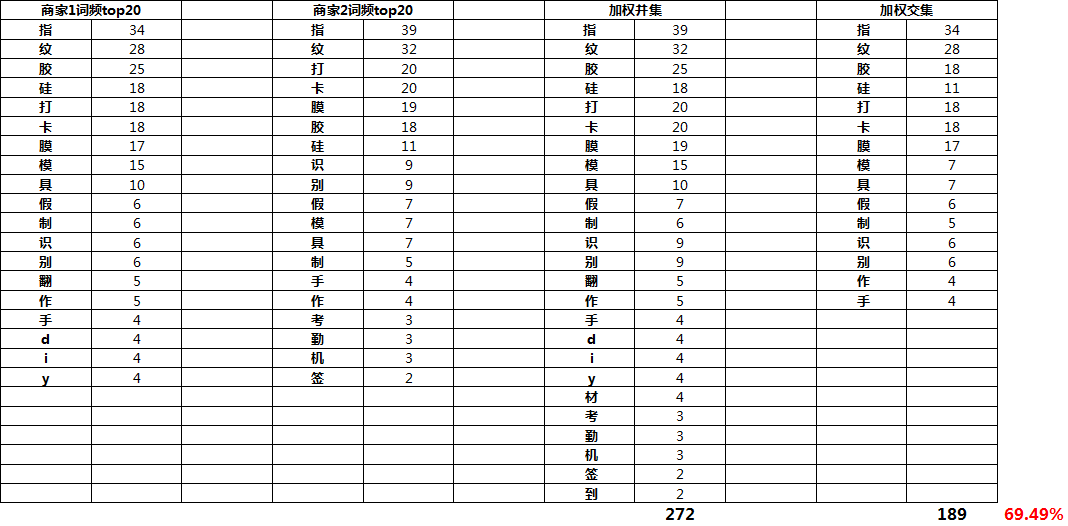
S1 = '模具硅胶 翻模硅胶 指纹签到手指摸 指纹假膜 模具硅胶 液态硅胶 半透明硅胶 指模自制 指纹识别硅胶 打卡指纹透明膜 指纹膜 指纹 胶膜 手机指纹打卡假膜 指纹打卡机指纹胶膜 指纹识别贴打卡 diy硅胶模具材料 指纹打卡 指纹打卡道具 指纹打卡假膜人脸 指纹识别膜 硅胶 硅胶模具diy 模型制作材料 指模 液体硅胶 考勤指纹胶 指纹打卡假膜科密 指纹打卡假膜 硅橡胶 指纹胶膜制作 打卡 翻模硅胶材料 食品级硅胶 打卡考勤指纹 指模具考勤 翻模硅胶 diy 指纹打卡膜 指纹打卡假膜 打卡机指纹识别膜 指纹制作 diy液体材料 指纹制作工具 指模具 手指打卡 手办工具 签到指纹胶膜制作 模具硅胶翻模 翻模硅胶 指纹识别胶打卡 硅胶 硅胶打卡 打卡指纹胶膜 指纹识别膜套'S2 = '指纹打卡假膜科密 指纹签到手指摸 指纹识别膜 硅胶 指模具 手指打卡 指纹打卡膜 指纹打卡假膜人脸 打卡考勤指纹 指模具考勤 指纹打卡机指纹胶膜 指纹制作工具 指纹打卡 指纹识别套 硅胶 硅橡胶 指模 diy硅胶模具材料 指纹制作 指纹识别硅胶 指模自制 打卡指纹胶膜 指纹打卡假膜 指纹打卡道具 手机指纹打卡假膜 指纹假膜 指纹膜 指纹打卡假膜 硅橡胶 打卡机指纹识别膜 指纹识别模具 硅胶 指纹识别膜套 硅胶模具diy 打卡指纹透明膜 上班 打卡指纹透明膜 指纹识别胶打卡 硅胶 指纹识别打卡膜假手指 硅胶 考勤指纹胶 硅胶打卡 指纹胶膜制作 打卡 签到指纹胶膜制作 指纹 胶膜 指纹识别贴打卡 abcdedf'from collections import Counterclass Similarty():def __init__(self,S1,S2,topn):self.S1 = S1self.S2 = S2self.topn = topn''' 标准杰卡德'''def normal_jaccard(self):return len(set(self.S1)&set(self.S2))/len(set(self.S1) | set(self.S2))''' 加权杰卡德'''def weight_jaccard(self):if self.S1 is not None and self.S2 is not None:sim_0 = self.S1.replace(' ','')sim_1 = self.S2.replace(' ','')collect0 = Counter(dict(Counter(sim_0).most_common(self.topn)))collect1 = Counter(dict(Counter(sim_1).most_common(self.topn)))jiao = collect0 & collect1bing = collect0 | collect1sim = float(sum(jiao.values()))/float(sum(bing.values()))return(sim)else:return 0.0sim = Similarty(S1,S2,50)#初始化sim.normal_jaccard()0.6964285714285714sim.weight_jaccard()0.7252396166134185



近期文章

