
煎蛋网全站妹子图爬虫
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
春节到了,老板都回去过新年了,咱们打工人也忙了一年了,这几天就抓点妹子图,摸摸鱼吧。
导入模块
首先把用到的模块贴进来。
import requests
from bs4 import BeautifulSoup
import time
import random
抓取
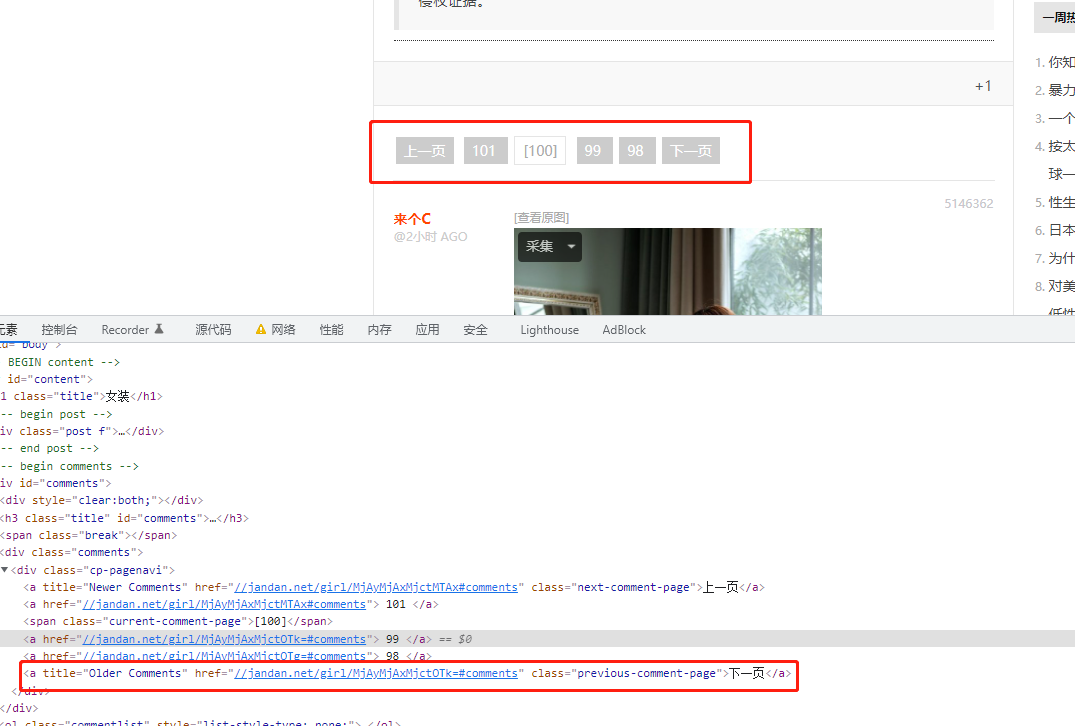
煎蛋网的抓取流程:从第 101 页开始抓取,提取页面上的女装图片 url,请求 url 后保存图片,点击下一页,重复循环...。
当访问煎蛋网的 http://jandan.net/girl 页面的时候,它是显示的最后一页。通过上面的分页控件获取下一页的 url。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
def get_html(url):
resp = requests.get(url = url, headers = headers)
soup = BeautifulSoup(resp.text)
return soup
def get_next_page(soup):
next_page = soup.find(class_='previous-comment-page')
next_page_href = next_page.get('href')
return f'http:{next_page_href}'
可以看到每个图片上都有[查看原图] 的超链接,提取这个 href 就是可以下载图片了。
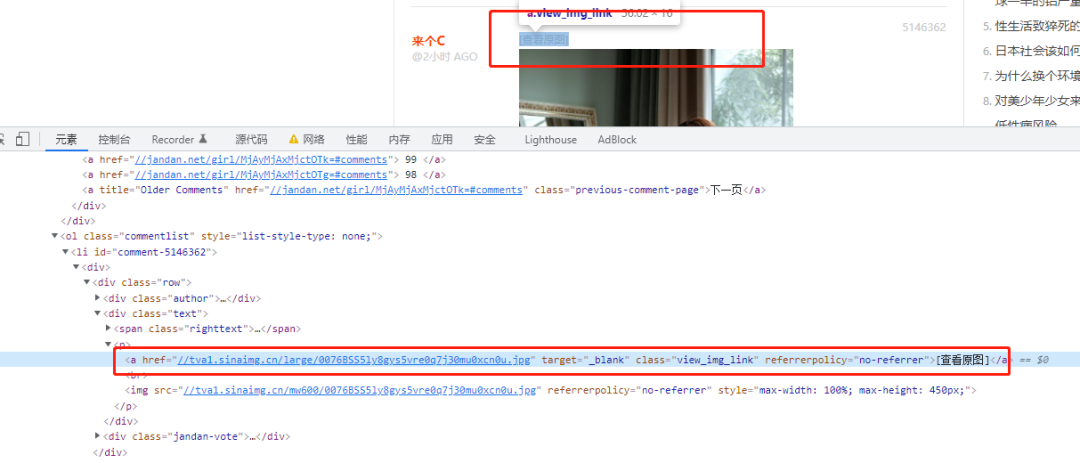
def get_img_url(soup):
a_list = soup.find_all(class_ = 'view_img_link')
urls = []
for a in a_list:
href = 'http:' + a.get('href')
urls.append(href)
return urls
保存图片就更简单了,request 请求后直接写入文件。
def save_image(urls):
for item in urls:
name = item.split('/')[-1]
resp = requests.get(url=item, headers = headers)
with open('D:/xxoo/' + name, 'wb') as f:
f.write(resp.content)
time.sleep(random.randint(2,5))
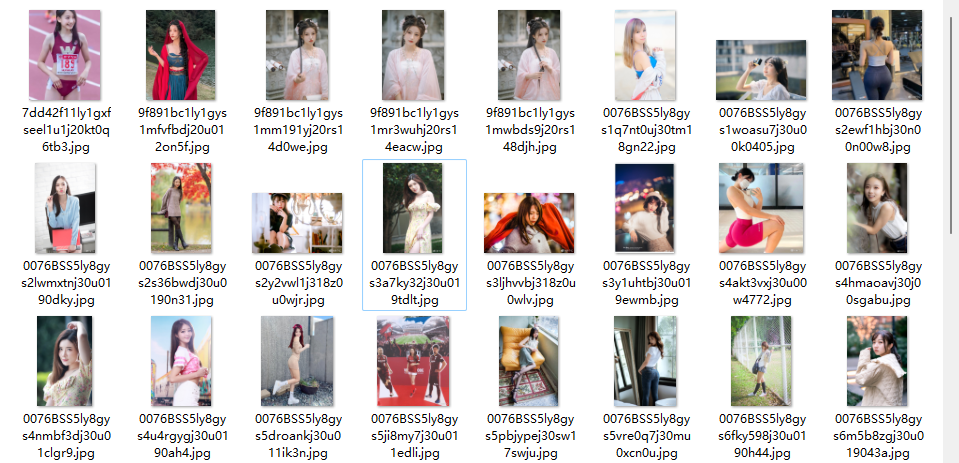
最后来看一下抓取结果吧。
总结
这篇 request 爬虫适合刚入 python 和没学过 soup 模块的小伙伴。春节来了,就不卷了,弄一个女装爬虫摸摸鱼、养养眼。
推荐阅读
您看此文用 
分

秒,转发只需1秒哦
评论