 机器学习算法工程师
机器学习算法工程师




 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
本文作者:杨军
原文:https://zhuanlan.zhihu.com/p/463629676
单设备硬件架构
跨设备硬件架构
AI workload及应用场景的演进
AI软件栈的演进
生态发展
1
Fermi
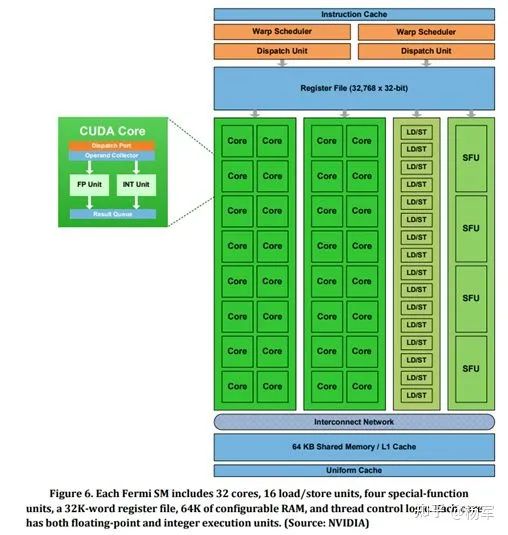
对流处理器(SM)进行了重新设计,包括:每个SM包含32个CUDA cores(这里需要提一下,CUDA core在概念上和通用计算的CPU core的性质其实是有差异的,不过并不影响从AI计算角度的讨论,所以在此先不展开)。每个SM里包括32浮点单元(FPU)和32个整数计算单元(INT Unit),16个Load/Store单元。4个特殊函数单元(SFU)。习惯上,我们会把FP32 ALU称为一个CUDA core,早期NV GPU因为INT 和 FP32 共享datapath,不能做ILP,所以那时候的CUDA core可以被认为包含一个INT和一个FP32 ALU。
对双精度算力进行了大幅提升。考虑到深度学习场景很少用到双精度计算,所以对这个细节不再展开。
引入了L1 cache,并增加了shared memory的容量。L1和shared memory的可配置总量是64KB,支持两种配置(48KB shared memory + 16KB L1或48KB L1 + 16KB L1)。shared memory从上一代的16KB增加到最多可达48KB。实际上,从Fermi开始,每一代GPU都会对shared memory,Register File,L1进行调整,支撑这些调整决策的是硬件推出后,通过和客户交互迭代所增加的对应用负载的理解,以及工艺进步带来了更多可供腾挪的片上硬件资源。
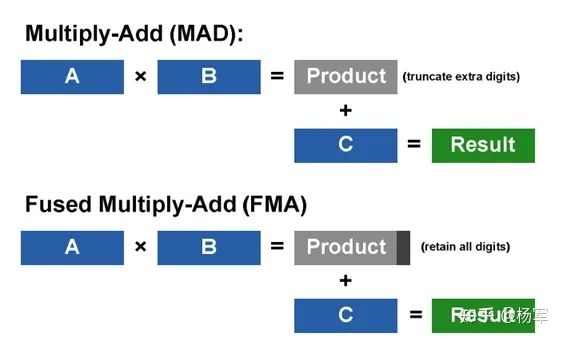
加入了对单精度浮点计算FMA的支持(Fermi之前的架构,支持双精度的FMA,对于单精度只支持MAD,FMA的精度更有保障,可参见这里的描述:https://en.wikipedia.org/wiki/Multiply%E2%80%93accumulate_operation),精度有了更高保障。
warp scheduler的数量从1增加到2,通过增加可调度发射的warp数量,来提升片上计算资源的利用率。Fermi的SM架构示意图如下(https://www.nvidia.com/content/PDF/fermi_white_papers/P.Glaskowsky_NVIDIA%27s_Fermi-The_First_Complete_GPU_Architecture.pdf)
引入了768KB的L2 cache。在Fermi之前,NV GPU是没有L2 cache的,从Fermi这一代开始,引入了L2 cache,并且随着代际演化,不断增加L2的尺寸。L2的引入,将之前需要由软件开发人员take的数据搬运优化的部分工作让渡给了硬件,从而部分减少了软件开发人员的心智负担。
对访存系统加入了ECC支持。对于ECC,我目前仍然怀疑其对于AI计算场景的必要性。因为我的认识是,AI计算过程本身可以通过系统层面的设计(比如阶段性的Checkpoint)来对冲ECC所针对修复检测的内存bits错误异常的影响,所以引入ECC这种会消耗访存带宽及存储资源的手段有些浪费。这也是我理解大量不包含ECC功能的桌面显卡能够应用在生产训练和推理集群的原因。
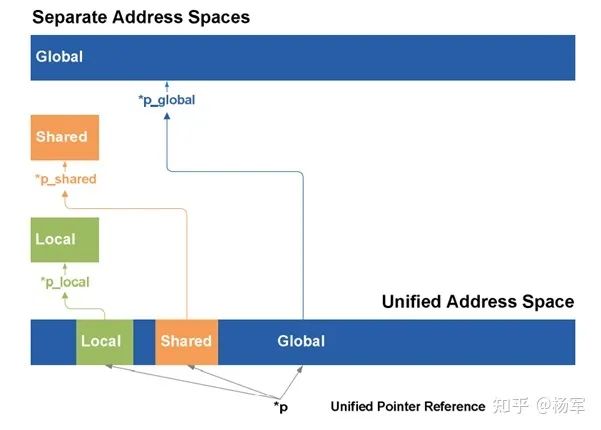
load/store地址位宽由32-bit提升到64-bit,为统一地址访问提供了基础条件。比如local memory,shared memory,global memory进行统一编址(参见下面的一张示意图)。
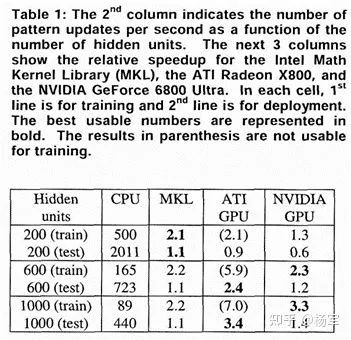
nehalem cpu 只有 port0 的 sse 支持 FP32 乘法,port1 的 sse 只支持 FP32 加法,所以对于深度学习里典型的乘法加法 1:1 的场景,i7-920 理论算力是 4-way*4core*2(FP add + mul ILP)*sse_freq,sse_freq 取 2.66G,那么算力约85Gflops,不过官方并没有公布sse密集情况下的多核频率,应该和这个数接近。

2
Kepler
去掉了SM里的双倍时钟。为了对冲去除SM内双倍时钟对性能的影响,Kepler大幅增加了CUDA core的数量。这里有一点用芯片空间换性能的味道。而Kepler采用的28nm的工艺升级,也为这个架构调整提供了相应的空间。
通过将部分指令依赖的判断逻辑从硬件层面上推到软件,节省了部分硬件资源消耗。
每个SM里的CUDA cores数量由前代的32个提升为192个(单精度计算)。
SM里的warp scheduler由Fermi的2个增加到4个,来适配CUDA core的数量增加。
将warp scheduler里硬件实现的调度依赖处理逻辑上推到软件编译器层(得益于NV GPU的计算流水线的确定延迟特性),节省了部分硬件资源消耗。
引入了warp shuffle指令,使得warp范围内的归约操作不需要经过shared memory中转,直接通过register的数据交互即可完成。而这类指令恰好为深度学习场景下特定尺寸workload的归约操作提供了相较于shared memory更高效的实现可能。
Google在2013年基于三台单机装配四块GTX680显卡的服务器,替换掉了之前使用的1000台CPU服务器,完成了猫脸识别任务。这对于NV GPU后续在深度学习计算场景的更多被采用,提供了非常好的背书。
虽然从第一性原理出发,我仍然认为NV GPU和Intel CPU不应该存在100X的性能差异,但很多时候,商业上的演化并不仅仅是基于第一性原理的技术论道(实际上从一些公开工作可以看得出来,至少Intel内部的技术团队对于NV GPU和自家硬件的优劣对比是有着清晰认知判断的,但似乎出于别的一些原因,这些技术认知未能最终转化成有效的公司决策操作)所能完整覆盖的,商业宣传布道、市场公关再加上不同企业面临相同场景因为自身组织特点和公司现状对客户反馈的反应不一,使得这种认知在相当长一段时间内深入建模人员的mindset中,这就为NV GPU扩大其在深度学习计算领域的覆盖率打下了很好的基础。
Google的GNMT模型在96块K80 GPU上完成其训练过程。在GNMT模型推出之后,工业界有若干头部公司先后参考其理念,将深度学习应用于机器翻译场景,并大抵都选择了GPU作为训练硬件。
2013年深度学习开源框架Caffe的发布。在Caffe发布之前,2002年Torch其实就已经发布,2007年Theano也已经发布,并且都提供了深度学习建模能力的支持。但是在深度学习领域,其接纳度远不如当时的后起之秀Caffe。Caffe推出之后,很快就收到了NV的关注,包括给Caffe开发团队免费提供GPU,以及推进cuDNN的集成,都是NV当时响应动作的部分。为什么是Caffe而不是先推出的Torch/Theano取得这样的成就呢?
我想,这里面的核心还是在于Caffe面对CV建模场景提供了更好的易用性(基于Caffe描述模型结构,以及定制Caffe的便利性)以及预训练好的模型checkpoint,使得CV建模人员可以把精力更多花在add-on的建模创新本身,而不是去折腾基础设施或是在复现其他SOTA结果上花费太多时间。
值得注意的是,如果我们回顾历史,会有这样一种感觉,Caffe开发过程中,关注的核心点首先是功能、易用性以及用户生态的建设,性能从一开始就不是其关注的第一优先级,性能方面,Caffe通过和硬件厂商的close合作来解决,而不是自己投入大量研发精力去解决。
一言以蔽,Caffe当时满足了更多DL建模人员的需求(当时的建模需求以CV为主),达到了第一代深度学习框架和使用用户之间更好的一个契合度。稍微形而上一些,从历史唯物主义的角度,在一个领域代表了大多数人利益的事物往往会得到更多的支持和认可,在2013年显然因为种种因素Caffe在CV建模领域达到了这个状态,于是Caffe得到了快速的推广。而NV则借着Caffe的推广普及,其GPU硬件更加深入深度学习建模人群了。
3
Maxwell
Maxwell架构在2014年被推出。和上一代Kepler架构相同,采用的也是28nm工艺。相同工艺通常意味着可供腾挪的硬件晶体管资源数量不会有显著增加,留给架构师的设计空间相对有限。不过在Maxwell时代,因为28nm工艺成熟度的改进,加上从前代产品迭代中学习到的经验,Maxwell仍然引入了一些比较出彩的变化:
将L1 cache和shared memory进行分离,而不是合成一段可灵活配置的连续存储资源资源。关于这一点,我们会注意到,Volta时代又将L1和shared memory进行了合并。架构设计的反复也体现了架构设计层面的螺旋式上升。
对L2尺寸进行了大幅调整,从512KB扩大到2MB。我的理解是,这种程度的调整往往是基于真实的workload反馈,数据驱动做出的架构决策。
增加了每个SM上active的thread blocks数量,从16增加到32,改善occupancy(https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/achievedoccupancy.htm)。我的理解是,这个调整也是为了配合下面的warp scheduler的改进所引入的协同动作,以确保有足够多的warp可够调度,来弥补去除全局warp scheduler损失掉的灵活性。
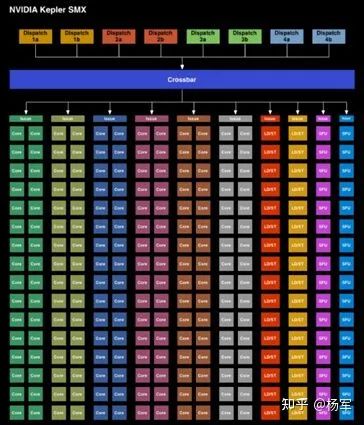
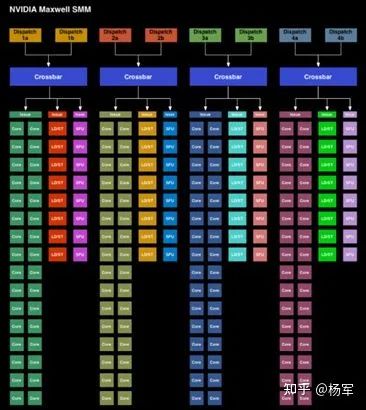
对warp scheduler的设计进行了调整(https://www.anandtech.com/show/7764/the-nvidia-geforce-gtx-750-ti-and-gtx-750-review-maxwell/3),每个warp scheduler只能看到SM内部四分之一的计算执行资源,牺牲了一定的灵活度,但节省了全局warp scheduling所需的SM范围内全局crossbar的功耗开销。
Kepler架构warp scheduling示意图。
Maxwell架构warp scheduling示意图(SM内的全局crossbar拆解为四个sub crossbar)
用户想加入新的模型结构(比如LSTM),相较第一代的Caffe,生产力有了显著的提升。曾经在Caffe里加入过RNN/LSTM支持的同学应该对这个是比较有体感的。在TensorFlow时代,如果只关注建模功能,对性能要求不picky的话,在Python层面就可以基于TF提供的原子operator完成LSTM结构的建模了。
从设计理念上,TF为不同的分布式执行策略提供了更好的基础。将计算图描述和运行期执行进行显式区分,对于后端优化,其实引入了更干净的抽象边界。
配套的TF Serving的引入。为深度学习提供了端到端的支撑能力,而不仅仅是训练环节。
4
Pascal
和CPU/内存资源配比的问题
机房运维新增复杂性的问题
对集群调度系统提出了更高要求

HBM。Pascal架构的一个突破性特性是首次将HBM技术引入到NV的硬件中(行业里最早将HBM引入到产品中的是AMD在2015年将其应用在Fji GPU产品中,第一块HBM内存芯片则是在2013年由SK hynix推出),提供相较上一代Maxwell架构最高3倍的访存带宽提升。HBM的引入为高访存压力的训练作业提供了更有力的硬件支持。
INT8。从Pascal时代开始,NV GPU首次引入了对INT8格式的支持(INT8首次引入是在基于GP102架构的P40 GPU,而不是基于GP100架构的P100 GPU)。INT8对于推理场景的必要性现在已经不需要过多说明,但是在16年的硬件里加入INT8支持,还是一件蛮激进的事情。Google TPU的消息也是在16年才对外正式expose,即便NV能够有渠道更早嗅到相关技术趋势,能够做到这么快将INT8加入量产GPU里,也是非常迅速的一个执行动作了。这也反映出NV的敏捷性和执行力。
2016年5月,MxNet 0.7版本的发布。其实很长一段时间,MxNet在业内都有着不错的认可度。包括我知道国内的一些AI公司在早期都是更倾向于基于MxNet进行扩展定制,而不是TensorFlow。以及NV在新款GPU上进行深度学习模型性能优化时,往往会先在MxNet上开展,比如MLPerf。
但一个发人深思的事实是,时至今日,基于MxNet发表的论文已经廖廖(参考Paperswithcode的一个趋势统计)。相近的项目启动时间,为什么最后出现这样的结果?我想,至少有一个信息是我们可以解读出来的,对于深度学习框架这个场景来说,性能可能并不是决定胜负的因素,因为至少在NV GPU上,MxNet的综合性能是最好的,但最后胜出的不是MxNet。PyTorch核心团队的一篇分享内容(https://soumith.ch/posts/2021/02/growing-opensource/),也许能部分回答这个问题。
2016年9月,PyTorch 0.1.1版本的发布,时至今日,PyTorch在研究领域,已经一骑绝尘,把其他深度学习框架远远甩在了后面,包括TensorFlow。与此同时,随着计算硬件的发展,PyTorch也开始暴露出一些局限性,最大的局限性也和其最大的优势有关——过于强调易用性使得用户建模代码里很容易充斥大量Pythonic的代码,导致引入大量host和加速器的数据以及控制依赖,在加速器不断push性能边界的大背景下,这个影响可能会吃掉易用性的红利。
5
Volta
Tensor Core的引入。已经有很多资料对Tensor Core进行过介绍,比如这篇介绍自动混合精度落地实践的文章(https://zhuanlan.zhihu.com/p/56114254),对Tensor Core的基本概念进行了介绍,Andrew Kerr的这份slides(https://developer.download.nvidia.cn/video/gputechconf/gtc/2020/presentations/s21745-developing-cuda-kernels-to-push-tensor-cores-to-the-absolute-limit-on-nvidia-a100.pdf)对使用Tensor Core开发高效计算kernel进行了比较详细的探讨。这里我想尽量减少一些不必要的重复。我想从两个角度来展开对Tensor Core的讨论,一个是硬件层面提供的基础支持,另一个是CUDA软件接口层面对外暴露的API。
从原先相对符合朴素直觉的SIMT过渡到了Warp-level的编程范式,同一个warp内的32个thread需要按照Tensor Core的数量分成8个分组(grouping),每个group内的四个thread需要协同完成shared memory到寄存器的数据加载,group与group之间也需要考虑协同。不同处理任务之间的依赖关系,增加了思考的复杂度度。
考虑到性能,shared memory里的数据组织方式需要注意规避bank conflict,这就引入了另一个反朴素直觉的维度。
Tensor Core的粗计算粒度,使得程序员需要显式地将计算过程进行细致的拆解。有兴趣的同学可以参考这里(https://arxiv.org/pdf/1804.06826.pdf)和这里(https://arxiv.org/pdf/1811.08309.pdf)的两份材料,可以看到CUDA层面为16x16x16规模矩阵计算暴露的wmma::mma_sync API映射为64(FP32累加)或32条HMMA指令(FP16累加)的细节拆解过程。如果想直接使用PTX的mma指令进行编程来获得更好的灵活性,就需要自行完成相应的拆解。
只支持FP16。虽然NV的技术团队设计了精巧的loss scaling策略(https://arxiv.org/abs/1710.03740),并通过自动混合精度插件化的手段完成了和主流深度学习框架的集成,但是对模型训练精度仍然存在一定影响,导致其在实际业务中被启用的比例并不算高。
可编程性相较SIMT时代的CUDA差了很多。CUDA层面暴露的WMMA API的粒度很粗,灵活性较差。即便使用PTX层面的WMMA指令,也只能提供相似灵活度。使用HMMA SASS指令虽然足够灵活,但又会影响到程序的可移植性,并且过于hacky。不过从PTX 6.4版本开始(对应于CUDA 10.1),在PTX层面对外暴露了MMA指令(https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-mma), 该指令的粒度和HMMA SASS指令已经一一对应,这就使得NV之外的工程师也拥有了更精细的Tensor Core编程API了。不过总体来说,Tensor Core编程本身的复杂性,导致NV之外能够基于Tensor Core开发CUDA程序的工程师数量显著下降。
NVLink带宽的增加。Volta时代的NVLink 2.0,单条link提供的单向带宽由Pascal时代的NVLink 1.0的20GB/s提升到25GB/s,双向向带宽由40GB/s提升提升到50GB/s,GPU之间的Link数量也由4条扩展为6条,加总在一起,GPU之间的双向互联带宽达到了300GB/s,相较NVLink 1.0带来了80%的带宽提升。
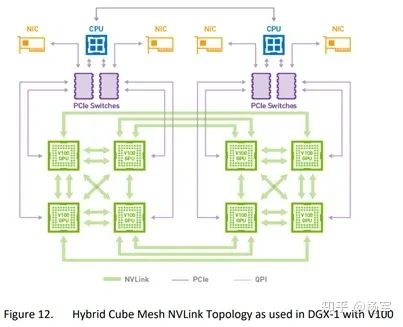
NVSwitch。在NVLink的基础上,2018年NV基于NVSwitch推出了DGX-2机型。NVSwitch的出现使得单机内部卡间通信带宽呈现出了均匀性。单机八卡机型,每块GPU通过6根links连接到NVSwitch上,再通过NVSwitch和其他GPU进行互联。所以理论上,任意两块GPU之间,都可以达到最高达300GB/s的双向带宽。这就为reduce-to-one乃至all2all这种通信模式提供了极大便利性。
HBM带宽的增加。经过Pascal时代引入HBM的试水,在Volta时代,NV对HBM的带宽进行了扩展,16GB显存配置的卡型,显存带宽由732GB/s提升到900GB/s,并且对HBM的实际访存效率进行了改善。
为SM的整数计算加入了单独的data path,使得整数计算指令(在AI场景通常对应于地址计算逻辑)不会阻塞浮点计算或Tensor Core指令的发射。引入这个特性是对Tensor Core毫无疑问是有benefit的,因为随着计算能力的提升,增加了其他操作成为瓶颈的可能,所以期望把地址计算操作所需的整数计算放在单独的data path里,从而缓解瓶颈。同时INT data path的引入也可以使其他非Tensor Core计算,但存在浮点和整数指令混合的场景受益,Volta 上不使用 Tensor Core 的 SGEMM优化难度相比 Pascal 更低就有这方面原因(感谢 @李少侠 同学指出这一点 )。
6
Turing
加入了INT8/INT4/INT1的Tensor Core支持。
使用GDDR6替换掉HBM,面向推理场景,提供更好的性价比,推理场景因为不涉及反向传播计算,并且推理过程可以更激进的启用算子融合技术,所以访存压力显著小于训练场景。
大幅去除用于FP64的计算资源(从Volta时代的1:2的FP64:FP32比例下降到Turing的1:32),因为DL推理场景并不需要使用FP64,所以大幅提升了能效比。
7
Ampere
采用7nm工艺,GPU die的尺寸相较V100略增(826mm^2 v.s. 815mm^2 ),片上晶体管数量从21B激增到54B,这就为更激进的架构创新提供了更多腾挪空间。
引入了BF16和TF32的Tensor Core,后者对于AI训练场景,具备更大的潜力成为开箱即用的精度格式。TF32的引入也得益于NV从Pascal时代对低精度训练的持续投入迭代,通过多轮实际系统的交付以及客户互动,获得了宝贵的反馈输入,最终催生了TF32的数据格式。看到TF32格式的引入,还是会对NV这家公司充满了敬意,因为这是一家在不断push自身边界的公司,期望未来能够保持这种态势。
对Tensor Core的尺寸进行了增加,由Volta/Turing代际的4x4x4增大到8x8x4,每个cycle可以完成128~256个FMA操作,进一步改善数据复用,提升了计算密度(GA100是256,GA10x是128)。
第三代NVLink(NVSwitch)。Ampere架构的NVSwitch和上一代的区别是将带宽提升了一倍,理论上,任意两块GPU之间,都可以达到最高达600GB/s的双向带宽。
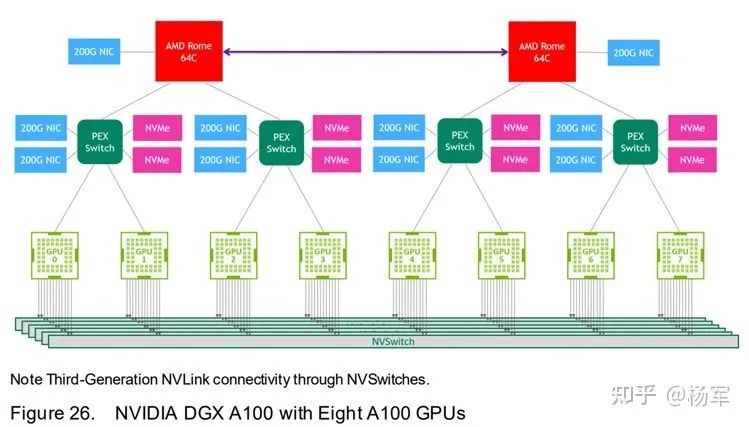
引入了MIG。用于提供硬件层面的单GPU多任务安全隔离。不过坦率说,我听到这个特性的使用案例似乎并不多。
结构化稀疏。这个特性从刚引入的很受关注,到现在渐渐有些期望回调。究其原因,涉及到侵入用户训练过程的优化手段,如果不是非常显著的收益,接受起来往往会有一定门坎。
HBM显存增加到40GB/80GB的配置,适配大模型训练的显存压力。带宽相较V100代际也有1.7X的提升,达到1.5TB/s。
大幅提升片上L2容量,从V100的6MB激增到40MB,这往往意味着基于工作负载反馈拿到了重要的架构决策所需的数据输入才可能支撑这么激进的的架构决策。L2访问带宽相较V100提升2.3X。Ampere架构里,L2到SM的crossbar不再是全连接,而是分拆成两个L2 sub-partition,每个sub-partition只服务于直接和其相连的SM。L2尺寸的增加和L2 sub-partition的引入其实是整个架构决策的一体两面(减少L2和SM互联的crossbar的开销),互为补充。
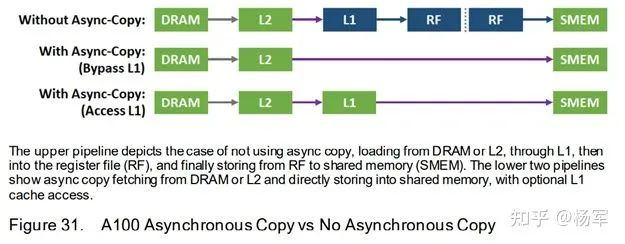
引入了用于异步数据copy的LDGSTS指令,可以bypass寄存器的中转,直接从global memory里将数据加载到shared memory,减少了寄存器的压力和不必要的数据中转,进一步节省了功耗。并且因为这条指令的异步性,可以作为背景操作和前台的计算指令overlap执行,进一步提升整体计算效率。
CUDA Graph在2018年被引入,用于优化小kernel的launch开销。在Ampere代际,为其加入了专门的硬件支持。时至今日,CUDA Graph已经是AI性能优化的重要依赖特性了,比如MLPerf里的诸多刷榜优化,以及Facebook也在2021年将CUDA Graph正式集成进PyTorch中。
加入了专用于JPEG格式解码的硬件decoder NVJPG,用于对数据预处理环节加速。以及大幅增加了用于视频解码的NVDEC的硬件资源,同理,也是为了对数据预处理环节加速。
今日口令红包秘语:2022我们在一起
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号



