 C语言题库
C语言题库




综合自网络
背景
相信很多人遇到过这样的问题:printf("%d,%d",i++,++i);
int a,b;int i=10,j=10;a=i++;b=++j;
int a,b;int i=10,j=10;a=(i++)+(i++)+(i++);b=(++j)+(++j)+(++j);




当然,就C语言代码来看,i++ 和 ++i 都只有一行,看起来似乎二者的执行效率一样了?其实不是的,在学习C语言时,教材和老师一般都会强调 i++ 和 ++i 的区别,例如下面这段C语言代码:
int i , j, k;i = 0;j = i++;i = 0;k = ++i;
这段C语言代码执行后,j 和 k 的值并不相等:j 等于 0,k 等于 1。既然执行结果有差异,那么执行效率很有可能也是有差异的,事实的确如此。查看上述C语言代码对应的汇编代码,如下:
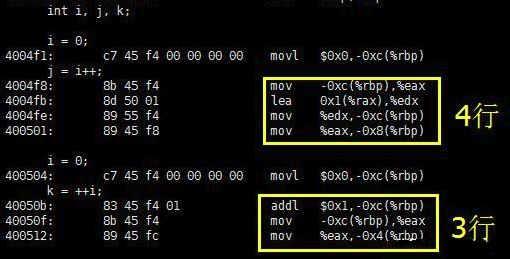
编译器版本为gcc 4.8.4
可见,j=i++; 计算机需要 4 条指令来解释,比执行 k=++i; 多出了一条指令。多出的一条指令为:在对 i 执行自加操作之前,先保存 i 的当前值留作稍后使用(赋值为j)。
关注公众号:C语言中文社区,免费领取300G编程资料
而且这样看来,似乎 ++i 的执行效率比 i++ 高一些?
例如,语句:states = 50;
一个顺序点(sequence point)是程序执行中的一点;在该点处,所有的副作用都在进入下一步之前被计算。在C中,语句里的分号标志了一个顺序点。它意味着在一个语句中赋值运算符、增量预算符及减量运算符所做的全部改变必须在程序进入下一个语句前发生。任何一个完整的表达式的结束也是一个顺序点。
什么是完整的表达式呢?一个完整的表达式(full expression)是这样一个表达式—-它不是一个更大的表达式的子表达式。完整的表达式的例子包括一个表达式语句里的表达式和在一个while循环里作为判断条件的表达式。
顺序点帮助阐明后缀增量动动作何时发生。例如,考虑下面的代码:
while(guests++<10)printf(“%d\n”,guests);
现在考虑这个语句:
Y=(4+ x++)+(6+ x++);没错,那就是对于i=10;(++i)+(++i)+(++i);这样的语句。C语言标准并没有作规定。有的编译器计算出来是39,因为会使i的值自增三次变为13,然后使用增加三次之后也就是13的3个值相加为39。而有的编译器计算结果则为37,如VisaulC++6.0则会先计算前两个i的值为12,第三个i的值变成了加三次以后的值为13,因此结果是12+12+13=37。如果有心的话,您可以分别在VC6和TC上本别测试;(++i)+(++i)+(++i) +(++i)的值来洞悉不同编译器的处理规则。
那么,回到最初的printf的问题,明白求值的顺序之后,再来看printf的求值问题,printf的参数都是从左到右依次压入栈内,所以计算起来求值运算的时候则是由右至左(栈的特点:即先进后出),那么至此,想必您已经完全想明白了这类问题的全部了!
为何++i比i++执行效率高一些呢?
那为了写出效率更高的C语言程序,以后是不是应该尽量使用 ++i,而不是 i++ 了呢?例如下面这样的C语言代码:
for(i=0; i<10; i++);for(i=0; i<10; ++i);
是不是上面那行C语言代码的执行效率低于下面的呢?只能说理论如此,实际上,现代C语言编译器已经足够聪明,它会根据上下文编译C语言代码。
应该明白,i++ 和 ++i 的效率差异主要来自于处理 i++ 时,需要先保存 i 的当前值留作稍后使用。如果之后没有人使用 i 的当前值,也就是说没有C语言代码读取 i++ 的值,编译器实在没有必要保存 i 的当前值了,因此就会将这一步优化掉。
为了便于分析,我们编写下面这样的C语言代码:
int i = 0;i++;++i;
与上面的例子相比,区别在于在执行 i++ 时,没有人关心 i 的当前值了。查看这段C语言代码对应的汇编代码:

显然,i++ 和 ++i 对应的指令是一模一样的,不再有执行效率上的差异。
C语言中的 i++ 和 ++i 是有区别的,这就有可能带来效率上的差异。如果有代码关心 i++ 执行时的 i 当前值,程序在对 i 进行自加操作时,将不得不先保存 i 的当前值,而 ++i 就无需保存当前值,这就会带来效率上的差异。如果没人关心 i++ 的当前值,那么现代大多数C语言编译器将会将这一差异优化掉,此时 i++ 和 ++i 不再有效率上的差异。
仅供大家学习参考与知识传播,版权归原作者所有,如有侵权,麻烦联系进行删除,感谢~
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧


