
Redis夺命十二问,你能扛到第几问?
共 3394字,需浏览 7分钟
· 2022-01-23
Redis是面试中绕不过的槛,只要在简历中写了用过Redis,肯定逃不过。今天我们就来模拟一下面试官在Redis这个话题上是如何一步一步深入,全面考察候选人对于Redis的掌握情况。
小张:
面试官,你好。我是来参加面试的。
面试官:
你好,小张。我看了你的简历,熟练掌握Redis,那么我就随便问你几个Redis相关的问题吧。首先我的问题是,Redis是单线程还是多线程呢?
小张:
Redis不同版本之间采用的线程模型是不一样的,在Redis4.0版本之前使用的是单线程模型,在4.0版本之后增加了多线程的支持。
在4.0之前虽然我们说Redis是单线程,也只是说它的网络I/O线程以及Set 和 Get操作是由一个线程完成的。但是Redis的持久化、集群同步还是使用其他线程来完成。
4.0之后添加了多线程的支持,主要是体现在大数据的异步删除功能上,例如 unlink key、flushdb async、flushall async 等
面试官:
回答的很好,那为什么Redis在4.0之前会选择使用单线程?而且使用单线程还那么快?
小张:
选择单线程个人觉得主要是使用简单,不存在锁竞争,可以在无锁的情况下完成所有操作,不存在死锁和线程切换带来的性能和时间上的开销,但同时单线程也不能完全发挥出多核CPU的性能。
至于为什么单线程那么快我觉得主要有以下几个原因:
Redis 的大部分操作都在内存中完成,内存中的执行效率本身就很快,并且采用了高效的数据结构,比如哈希表和跳表。
使用单线程避免了多线程的竞争,省去了多线程切换带来的时间和性能开销,并且不会出现死锁。
采用 I/O 多路复用机制处理大量客户端的Socket请求,因为这是基于非阻塞的 I/O 模型,这就让Redis可以高效地进行网络通信,I/O的读写流程也不再阻塞。
面试官:
不错,那Redis是如何实现数据不丢失的呢?
小张:
Redis数据是存储在内存中的,为了保证Redis数据不丢失,那就要把数据从内存存储到磁盘上,以便在服务器重启后还能够从磁盘中恢复原有数据,这就是Redis的数据持久化。Redis数据持久化有三种方式。
AOF 日志(Append Only File,文件追加方式):记录所有的操作命令,并以文本的形式追加到文件中。 RDB 快照(Redis DataBase):将某一个时刻的内存数据,以二进制的方式写入磁盘。 混合持久化方式:Redis 4.0 新增了混合持久化的方式,集成了 RDB 和 AOF 的优点。
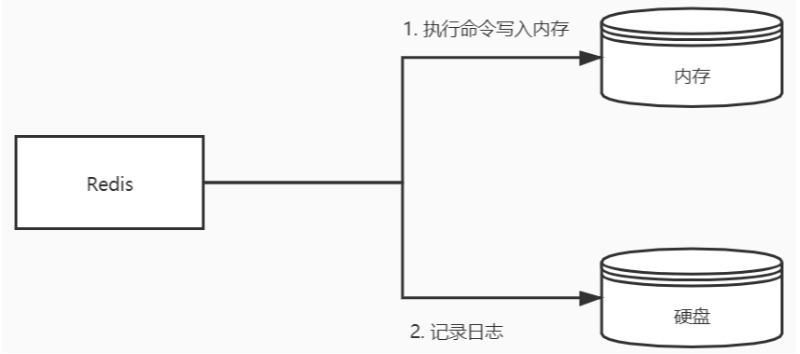
数据可能会丢失:如果 Redis 刚执行完命令,此时发生故障宕机,会导致这条命令存在丢失的风险。 可能阻塞其他操作:AOF 日志其实也是在主线程中执行,所以当 Redis 把日志文件写入磁盘的时候,还是会阻塞后续的操作无法执行。
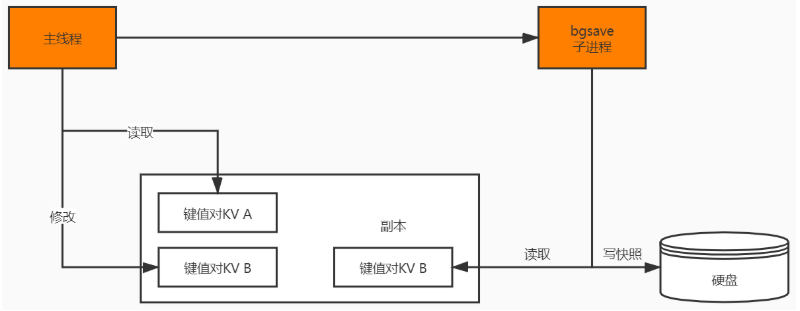
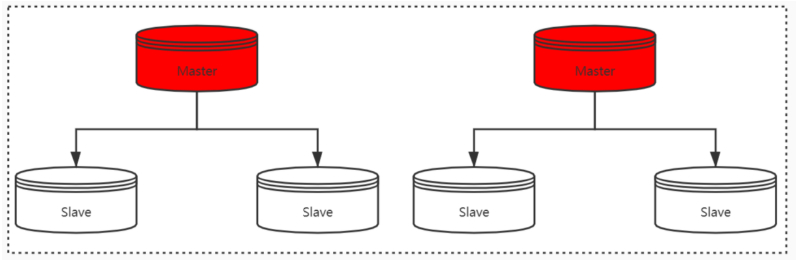
save 和 bgsave。save 命令在主线程中执行,会导致阻塞。而 bgsave 命令则会创建一个子进程,用于写入 RDB 文件的操作,避免了对主线程的阻塞,这也是 Redis RDB 的默认配置。
bgsave的子线程实现的,具体操作如下:如果主线程执行读操作,则主线程和 bgsave子进程互相不影响;如果主线程执行写操作,则被修改的数据会复制一份副本,然后 bgsave子进程会把该副本数据写入 RDB 文件,在这个过程中,主线程仍然可以直接修改原来的数据。

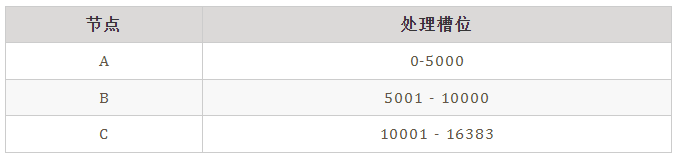
根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值。 再用 16bit 值对 16384 取模,得到 0~16383范围内的模数,每个模数代表一个相应编号的哈希槽。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️