
【关于Bert】 那些的你不知道的事(上)
作者简介
作者:杨夕
论文名称:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文链接:https://arxiv.org/pdf/1706.03762.pdf
代码链接:https://github.com/google-research/bert
推荐系统 百面百搭地址:
https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:
https://github.com/km1994/NLP-Interview-Notes
个人 NLP 笔记:
https://github.com/km1994/nlp_paper_study
个人介绍:大佬们好,我叫杨夕,该项目主要是本人在研读顶会论文和复现经典论文过程中,所见、所思、所想、所闻,可能存在一些理解错误,希望大佬们多多指正。
引言
本博客 主要 是本人在学习 Bert 时的所遇、所思、所解,通过以 十二连弹 的方式帮助大家更好的理解 该问题。
十二连弹
【演变史】one-hot 是什么及所存在问题?
【演变史】word2vec 是什么及所存在问题?
【演变史】fastText 是什么及所存在问题?
【演变史】elmo 是什么及所存在问题?
【BERT】Bert 是什么?
【BERT】Bert 三个关键点?
【BERT】Bert 输入表征长啥样?
【BERT】Bert 预训练任务?
【BERT】Bert 预训练任务 Masked LM 怎么做?
【BERT】Bert 预训练任务 Next Sentence Prediction 怎么做?
【BERT】如何 fine-turning?
【对比】多义词问题及解决方法?
问题解答
【演变史】one-hot 是什么及所存在问题?
one-hot:
介绍:
用一个很长的向量来表示一个词,向量长度为词典的大小N,每个向量只有一个维度为1,其余维度全部为0,为1的位置表示该词语在词典的位置。
特点:
维度长:向量的维度为 词典大小;
一一其零:每个向量只有一个维度为1,其余维度全部为0,为1的位置表示该词语在词典的位置;
问题:
维度灾难:容易受维数灾难的困扰,每个词语的维度就是语料库字典的长度;
离散、稀疏问题:因为 one-Hot 中,句子向量,如果词出现则为1,没出现则为0,但是由于维度远大于句子长度,所以句子中的1远小于0的个数;
维度鸿沟问题:词语的编码往往是随机的,导致不能很好地刻画词与词之间的相似性。
【演变史】wordvec 是什么及所存在问题?
双剑客
CBOW vs Skip-gram
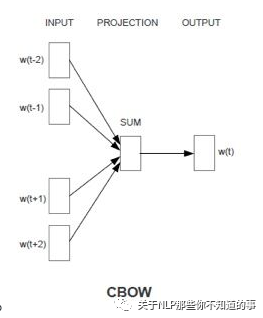
CBOW
思想:用周围词预测中心词
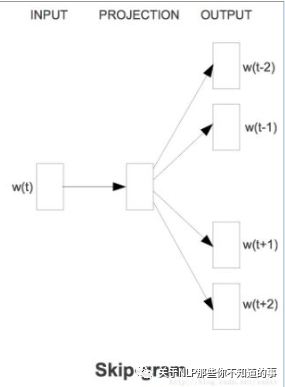
Skip-gram
思想:用中心词预测周围词
CBOW vs Skip-gram 哪一个好?
CBOW 可以理解为 一个老师教多个学生;(高等教育)
Skip-gram 可以理解为 一个学生被多个老师教;(补习班)
那问题来了?
最后 哪个学生 成绩 会更好?
存在问题:
因为 word2vec 为静态方式,即训练好后,每个词表达固定;
多义词问题
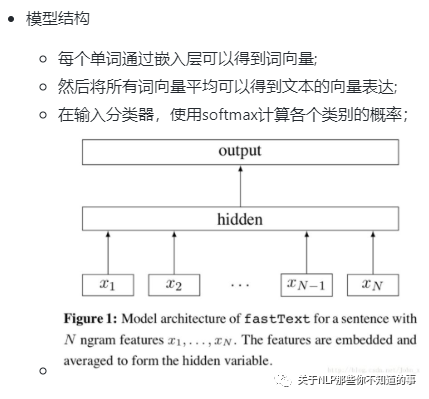
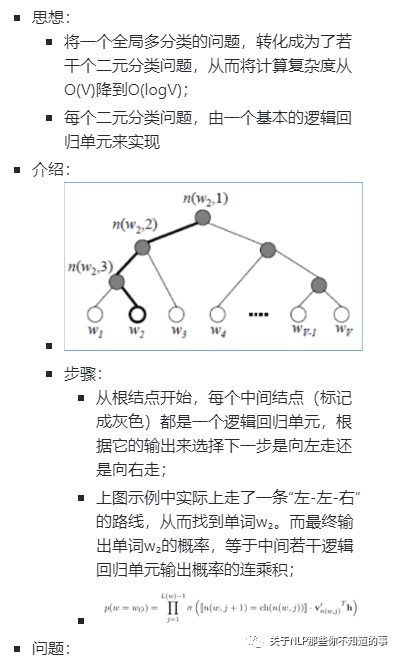
【演变史】fastText 是什么及所存在问题?











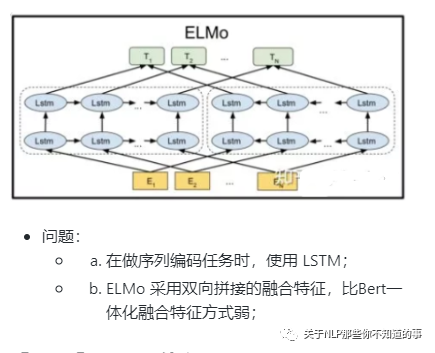
【演变史】elmo 是什么及所存在问题?

待续!!!
参考
CS224n
关于BERT的若干问题整理记录
所有文章
五谷杂粮
NLP百面百搭
Rasa 对话系统
知识图谱入门
转载记录
