
轻松解决时序异常检测问题,pyfbad 这次火了!
共 3532字,需浏览 8分钟
· 2022-01-21
关注"Python学习与数据挖掘",
设为“置顶或星标”,第一时间送达干货
机器学习项目的典型流程从读取数据开始,然后是一些预处理、训练、测试、可视化,并与通知系统共享结果。
当然,所有步骤都可以在各种开源库的帮助下轻松完成。但是,在某些特定情况下,例如时间序列数据中的异常检测,减少库和硬编码步骤的数量将更有利于可解释性,为此开发了 pyfbad 库。
Github:https://github.com/Teknasyon-Teknoloji/pyfbad
简介
pyfbad 库是一个端到端的无监督异常检测包,这个包提供了前面提到的所有 ml-flow 步骤的源代码。也就是说,项目的整个周期都可以借助 pyfbad 提供的源代码来完成,无需使用任何其他库。
pyfbad 有 4 个主要模块:数据库、特征、模型和通知。在 Cookiecutter 的 Drivendata 的帮助下,这种结构在数据科学项目中几乎是标准化的。
数据库
此模块具有从各种数据库或文件读取数据的脚本,尤其是在 MongoDB 中,通过 Pyfbad 使用过滤步骤变得更加用户友好。
下面的代码片段可能会介绍如何将 pyfbad 用于数据库操作。
# connet to mongodb
from pyfbad.data import database as db
database_obj = db.MongoDB('db_name', PORT, 'db_path')
database = database_obj.get_mongo_db()
# check the collections
collections = dataset_obj.get_collection_names(database)
# buil mongodb query
filter = dataset_obj.add_filter(
[],
'time',
{
"column_name": "datetime",
"date_type": "hourly",
"start_time": "2019-02-06 00:00:00",
"finish_time": "2019-10-06 00:00:00"
}
)
# get data from db as dataframe
data = dataset_obj.get_data_as_df(
database=database,
collection=collections[0],
filter=filter
)
特征
时间序列异常检测需要两种类型的数据。其中一个是连续时间数据,另一个是我们想要检测异常的主数据,这两个数据应作为模型数据从原始数据中提取。Pyfbad 提供了从原始数据帧中检索模型数据的可选筛选功能。
下面的代码段显示了如何将 pyfbad 用于此操作。
from pyfbad.features import create_feature as cf
cf_obj = cf.Features()
df_model = cf_obj.get_model_data
(
df = data,
time_column_name = "_id.datetime",
value_column_name = "_id.count",
filter = ['_id.country','TR']
)
模型
该模块能够使用各种算法训练模型数据。Pyfbad 旨在检测时间序列数据上的异常。它提供了可以快速且稳健地应用的模型,比如:Facebook Prophet 和 Isolation Forrest。
作为一个例子,我们可以从下面的代码片段中看到 Prophet 是如何借助 pyfbad 实现的。
from pyfbad.models import models as md
models=md.Model_Prophet()
model_result = models.train_model(df_model)
anomaly_result = models.train_forecast(model_result)
通知
pyfbad 提供了各种通知系统来共享项目的结果,比如:电子邮件,它可以用作下面的代码片段。
from pyfbad.notification import notifications as nt
gmail_obj = nt.Email()
if 1 or -1 in anomaly_result['anomaly']:
gmail_obj.send_gmail('sample_from@gmail.com','password','sample_to@gmail.com')
案例
我们以案例方式快速了解如何使用 Pyfbad,以 Kaggle 比赛中一款推特产品的点击数据为例,数据和完整版代码,文末可以获取。
利用 pyfbad 库处理数据
import plotly.express as px
import pyforest
from plotly.offline import iplot
from pyfbad.data import database as db
from pyfbad.models import models as md
from pyfbad.features import create_feature as cf
from pyfbad.notification import notifications as ntf
import pandas as pd
conn=db.File()
df=conn.read_from_csv("/kaggle/input/nab/realTweets/realTweets/Twitter_volume_AAPL.csv")
df.head()

数据可视化,效果更直观。
import plotly.graph_objects as go
# plot value on y-axis and date on x-axis
fig = px.line(forcasted, x=forcasted.index, y="actual", title='TWEETS - UNSUPERVISED ANOMALY DETECTION', template = 'plotly_dark')
# create list of outlier_dates
fig.show()
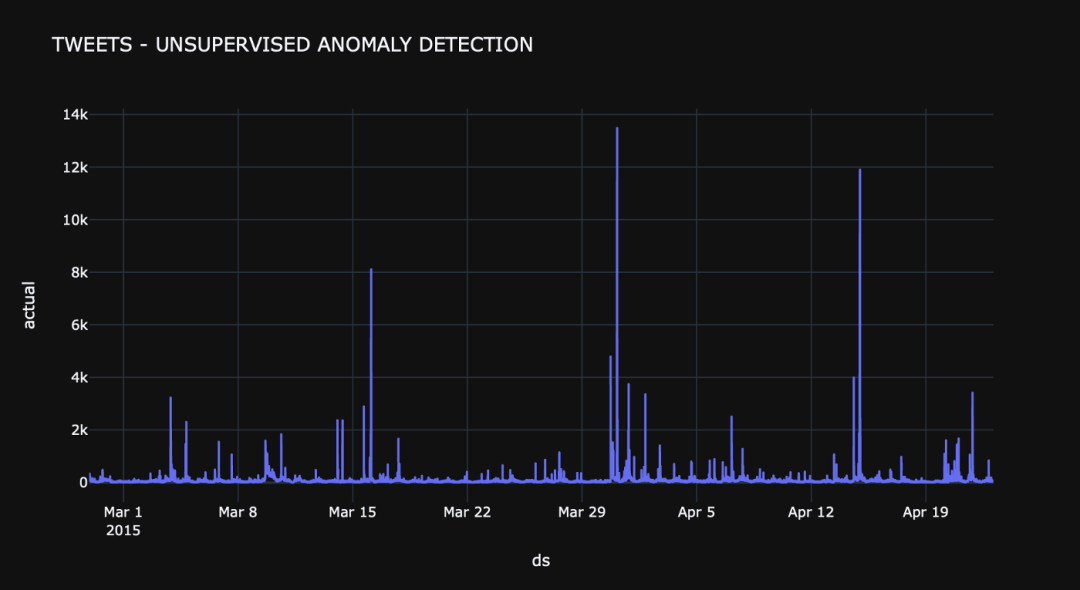
在此实现中使用 Prophet 算法来训练模型。在训练步骤之后,检测到的异常如图下图所示
forcasted=models.train_forecast(forecast)
outlier_dates = forcasted[forcasted['anomaly'] == 1].index
# obtain y value of anomalies to plot
y_values = [forcasted.loc[i]['actual'] for i in outlier_dates]
fig.add_trace(go.Scatter(x=outlier_dates, y=y_values, mode = 'markers',
name = 'anomaly',
marker=dict(color='red',size=10)))
fig.show()

结论
在本文中,我们对 Pyfbad 进行了详细介绍和实操案例分享,可以看得出,它使用起来简单方便,是一款不可多得的无监督异常检测库。
代码和数据获取方式
在本公众号后台回复:Pyfbad
长按或扫描下方二维码,后台回复:加群,即可申请入群。一定要备注:来源+研究方向+学校/公司,否则不拉入群中,见谅!
(长按三秒,进入后台)
推荐阅读
