 老肥码码码
老肥码码码





老肥今天和大家分享的是刚刚结束的kaggle竞赛PetFinder.my-Pawpularity Contest,具体任务是使用一些元数据以及图像数据做出流行度预测(一个回归问题)。然而本题其实元数据并无用处(负收益),主要就是一个图像的竞赛。在本次比赛中,我犯了一些错误但也学习了很多,本文具体内容分成第一部分比赛回顾讲述我们队的具体方案,第二部分Top方案上分点总结对本次竞赛的上分点做一个盘点。
比赛回顾
本次比赛的主要思路就是把回归任务看作分类任务,使用BCEWithLogitsLoss损失函数,使用swin_large模型(本次竞赛的明星模型)进行训练预测,采用常规的数据增强手段,五折交叉验证。
我们队也采用了多种学习的策略,主要有一些几种:
策略一,使用额外的数据集训练一个 猫狗细分类器(分成37类,采用了efficientnet_b0),输出每一类的分类概率与swin_large输出的特征向量作为拼接,再输入全连接层作为最后的输出【PB17.081】。策略二,使用yolo模型识别有猫或是有狗的 粗分类,将标签送入模型进行学习【PB17.090】。策略三,使用 SVR Head对深度学习模型的输出做一个集成【PB17.123】。(此处采用原始的swin,未混合策略一与策略二,因为LB成绩过低,未在后续使用(当事人老肥非常后悔))
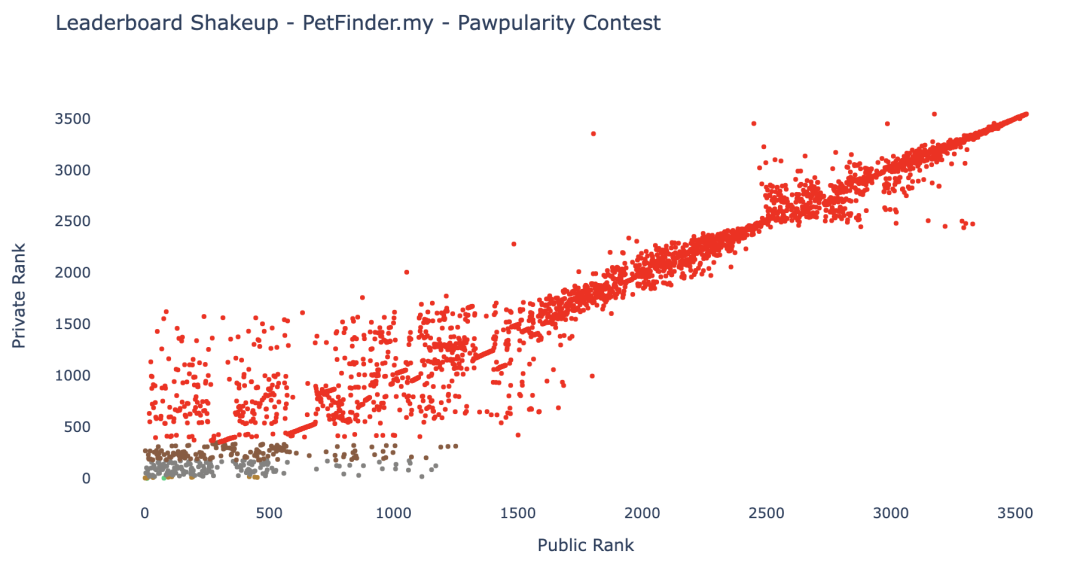
最后采用多模型平均融合的策略,这里有一个非常值得反思的地方,我们在本次比赛中没有好好的评测利用CV分数,而是使用了LB成绩最好的模型进行融合,导致切榜之后shake了三位数的排名,这是非常不应该的,
以后在每一次模型迭代的时候都应该保存一份OOF.csv来正确地计算CV得分,避免过度拟合公共排行榜,避免大幅shake down(下图是Leadboard shake图,来自[5])。
Top方案上分点总结
重复的图像放到同一个fold里面,保证验证集里图像未泄露导致过拟合[1]。
为了使它看起来像 petfinder 网站上的缩略图,
剪切图像的长边,然后再调整分辨率, 直接Resize会改变纵横比[1][2]。多任务学习,增加第二个学习的任务,预测是猫或者是狗[2]。使用额外的数据,在上一届PetFinder竞赛中,有约1700个图像与本次竞赛的训练集图像(约占17%)重复,由于测试集是从总体样本中抽样的,所以同样存在部分比例的测试集图像来自于上一届PetFinder竞赛, 而上一届竞赛中元数据是非常有用的(本次竞赛元数据对提高分数毫无用处),这便可以使用图像哈希进行匹配的方法找出对应图片并将元数据作为特征输入树模型(未匹配的全部为NaN),提高模型的预测能力[3]。使用SVR Head,训练深度学习模型时,在其头部拼接一个SVR头,该SVR使用深度学习模型提取的特征向量以及元数据并最后与该深度学习模型的输出做集成[2]。使用hill climbing算法做集成,先选择所有模型中oof得分最高的,然后选择新的模型与之前的模型做集成,得到集成分数最好的第二个模型,加入到集合之中,重复过程直至提升小于指定阈值[2][4]。
参考资料
[1]https://www.kaggle.com/c/petfinder-pawpularity-score/discussion/301072 [2]https://www.kaggle.com/c/petfinder-pawpularity-score/discussion/301015 [3]https://www.kaggle.com/c/petfinder-pawpularity-score/discussion/301091
[4]https://www.kaggle.com/c/siim-isic-melanoma-classification/discussion/175614 [5]https://www.kaggle.com/c/petfinder-pawpularity-score/discussion/301192
——END——

