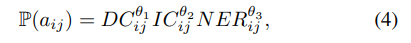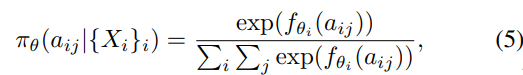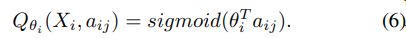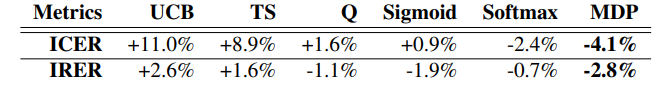- 1.2.3 策略梯度 softmax 策略排名器(Policy-gradient Softmax-policyRankers)
策略梯度 softmax-policy 排名器使用线性函数计算当前上下文 Xd 中假设的分数。然后,在所有域排名器的假设分数之上应用 softmax 函数。这个 softmax 的结果被用作策略来采样假设作为最终输出。具体公式如下:其中 θ=[θ1,θ2, . . . , θk],k 是域的总数。Xi 是第 i 个域的上下文,aij 是第 i 个域中的第 j 个假设, 是第 i 个域排名器对假设 aij 的得分。1.3 Q 学习排名器(Q-learning rankers)Q 学习排名器在特征的线性函数之上使用 sigmoid 函数来计算假设的 Q 值(即分数)。对于第 i 个域,让
是第 i 个域排名器对假设 aij 的得分。1.3 Q 学习排名器(Q-learning rankers)Q 学习排名器在特征的线性函数之上使用 sigmoid 函数来计算假设的 Q 值(即分数)。对于第 i 个域,让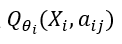 表示上下文 Xi 的假设 aij 的 Q 值,其中 aij 是第 i 个域中的第 j 个假设,然后:Q 学习排名器和策略梯度排名器有两个区别。首先,使用-贪婪策略对假设进行采样:以概率选择具有最高 Q 值的假设,以概率从所有可用假设中随机均匀地选择一个假设。其次,通过最小化假设 Q 值的均方误差来优化 Q 学习排序器的参数。所提出的方法依赖于隐式用户反馈信号来计算与记录数据中的样本相关联的奖励,而不是人工注释。如果选择的 NLU 假设符合客户的需求,则给予正奖励,如果不符合则给予负奖励。这种方法可以快速赶上趋势请求,因为训练方法允许在运行时自动修改模型。
表示上下文 Xi 的假设 aij 的 Q 值,其中 aij 是第 i 个域中的第 j 个假设,然后:Q 学习排名器和策略梯度排名器有两个区别。首先,使用-贪婪策略对假设进行采样:以概率选择具有最高 Q 值的假设,以概率从所有可用假设中随机均匀地选择一个假设。其次,通过最小化假设 Q 值的均方误差来优化 Q 学习排序器的参数。所提出的方法依赖于隐式用户反馈信号来计算与记录数据中的样本相关联的奖励,而不是人工注释。如果选择的 NLU 假设符合客户的需求,则给予正奖励,如果不符合则给予负奖励。这种方法可以快速赶上趋势请求,因为训练方法允许在运行时自动修改模型。
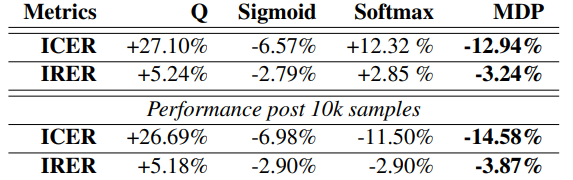
1.带注释的数据,其中预期答案是真实情况,由人工注释者决定;2.未注释的记录历史数据,其中真实情况未知, 预期响应(被认为是真实的)由隐式用户输入决定。本文使用 IRER(精确匹配假设错误率)和 ICER(意图分类错误率)两个指标来解释在这些试验中的发现。本文利用内部数据集。训练和测试数据分别包含 503,000 和 1,154,000 条话语。在测试中,每个域排名器的参数从训练结果中初始化,并在整个测试过程中保持固定。基线模型是生产模型,其中领域排名器使用等式(4)计算假设的分数,并通过离线监督学习对相同的带注释的训练数据进行训练。表 1 提供了与基线模型相比,不同排名器在对带注释的数据进行训练和测试时的相对性能。从表 1 中可以看出,非线性排序器的性能优于线性排序器。在 IRER 方面,sigmoid-policy 和 MDP-policy 的策略梯度排名器表现最好,相对 IRER 分别降低了 1.87% 和 2.77%。表 1 中的结果表明,本文的训练方案比具有相同标注数据的传统监督学习更有效。表 1. 与注释数据的基线相比,排序器的相对性能。负值意味着错误率降低在下一组实验中,本文从未注释的历史数据中进行采样,其中本文使用隐式用户反馈信号来筛选出正样本,即没有消极用户反馈信号的影响。生产模型输出被视为用户请求的真实假设。本文从历史数据中进行子采样,以构建一个包含超过 800,000 条话语的数据集。基线模型与第 2.1 节中的模型相同,但以半监督方式使用未注释的训练数据进行训练。表 2 提供了与基线模型相比,不同排序器在对未注释的测试数据进行训练和测试时的相对性能。本文针对这种情况报告了两组评估指标:所有测试数据的整体指标(第 2 行到第 4 行),以及测试数据的稳定指标,不包括前 10,000 个样本(最后两行),用于衡量模型学习参数收敛后的性能。从表 2 中可以看出,三个策略梯度排序器在从 10,000 个样本中学习后表现优于基线模型,而策略梯度 MDP-policy 排序器表现最好,IRER 相对提高了 3.87%。本文推测是因为 MDP-policy 框架中分数的乘法处理,如等式(4)中给出的。这允许具有较低分数的正确假设在探索过程中相对更容易“冒泡”,更有效的在线学习有助于模型在不太频繁的话语上表现得更好。表 2. 排名器在无注释正数据上的相对性能。负值意味着错误率的降低。在最后的实验中,本文遵循与第 2.2 节中相同的数据设置,但同时还使用消极用户反馈信号筛选的负样本。训练和测试策略与表2相同,但有一个区别:对于前 10,000 个样本,模型选择的假设被迫与记录的响应相同。表 3 提供了前 10000 个样本后测试数据的相关指标(与第 2.2 节相同)。对于具有最佳性能的策略梯度 MDP-policy 排序器,在同时使用正样本和负样本数据学习时 IRER 降低了 4.44%,但仅正样本数据学习时 IRER 只降低了 3.87%。表 3. 排序器在具有未注释的正样本和负样本数据上的相对性能。显示的结果是模型从 10,000 个样本中学习后的在线表现。负值意味着错误率降低
本文为 NLU 排名引入了深度强化学习技术,其中独立的 NLU 领域专家模型根据其特征生成假设,领域排名器计算领域中假设的分数。本文将应用深度强化学习技术来构建不依赖于注释数据的完全在线模型。实验结果表明,与基线模型相比,新技术使精确匹配假设(IRER)和意图分类错误率(ICER)分别降低了 4% 和 18%。
在未来的工作中,该团队计划通过考虑奖励过程中摩擦估计的不确定性,以更高级的方式利用用户摩擦;同时还寻求改进在线学习过程中的探索过程,例如通过使用前瞻策略和相关工作。


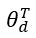 是域 d 中排名器的参数。
是域 d 中排名器的参数。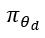 表示选择假设的策略。策略
表示选择假设的策略。策略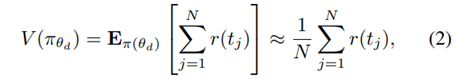
 是第 j 个样本轨迹(轨迹是用户请求的选择假设)。值函数的梯度可以使用策略梯度定理,如下式所示:
是第 j 个样本轨迹(轨迹是用户请求的选择假设)。值函数的梯度可以使用策略梯度定理,如下式所示: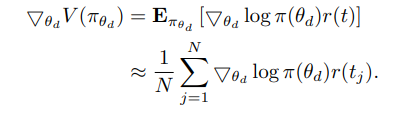

 是当前上下文 Xd 中 i 个假设的特征。对于策略梯度 sigmoid 策略排名,对假设的探索是通过探索深度和“贪婪”策略(greedy strategy)进行的,如算法(Algorithm)1 中所述。
是当前上下文 Xd 中 i 个假设的特征。对于策略梯度 sigmoid 策略排名,对假设的探索是通过探索深度和“贪婪”策略(greedy strategy)进行的,如算法(Algorithm)1 中所述。