
如何优雅地实现多头自注意力
本文使用 einsum 和 einops 来实现自注意力 self-attention 及其多头版本。
1为什么用它们?
首先,einsum 和 einops 代码干净优雅。
让我们看一个例子:比如你想合并一个 4D 张量的 2 个维度,第一个和最后一个。
x = x.permute(0, 3, 1, 2)
N, W, C, H = x.shape
x = x.contiguous().view(N * W, C, -1)
x = einops.rearrange(x, 'b c h w -> (b w) c h')
其次,如果你要实现具有多维张量的自定义层,那么 einsum 绝对应该在你的工具库中!
再者,将代码从 PyTorch 转化成 TensorFlow 或 NumPy 将变得非常便捷。
当然,你需要一定时间来适应它的使用套路。结合实例来学习将更加高效,本文将实用它来实现一些自注意力机制。
.Einsum .
所谓爱因斯坦求和约定,简而言之,就是使用如下结构 einsum 命令:
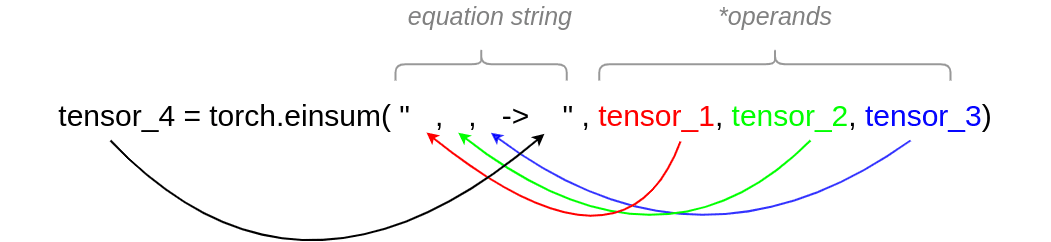
我们可以将 einsum 的参数分成两部分:
等式字符串(Equation string):这是所有索引所在的位置。每个索引将指示张量的维度。为此,我们使用小写字母。对于将在多个张量的等维轴上执行的操作,我们必须使用相同的符号。
->左侧的逗号个数要与使用的张量一样多,彩色箭头指明了对应关系。在->的右侧是操作的输出索引,需要与输出维度一样多的索引。我们在输出中使用的字母(索引)必须存在于等式字符串的右侧。操作数(Operands):我们可以提供任意数量的张量。显然,张量的数量必须与
->方程的左边部分完全相同。
.示例:批量矩阵乘法 .
假设我们有 2 个具有以下形状的张量,我们想在 Pytorch 中执行批量矩阵乘法:
A = torch.randn(10, 20, 30) # b -> 10, i -> 20, k -> 30
C = torch.randn(10, 50, 30) # b -> 10, j -> 50, k -> 30
使用 einsum,可以用一个优雅的命令清楚地说明它:
y1 = torch.einsum('b i k, b j k -> b i j', A, C) # shape [10, 20, 50]
这个命令对应如下公式,
如果没有 einsum,我们将不得不置换 C 的轴,还必须记住 Pytorch 的批量矩阵乘法命令。
y2 = torch.bmm(A, C.permute(0, 2, 1))
因为 torch.bmm 有它自己的章法,我们必须按照它的要求来。
torch.bmm(input, mat2, deterministic=False, out=None) → Tensor
执行输入和 mat2 中存储的矩阵的批量矩阵矩阵乘积。
input 和 mat2 必须是 3-D 张量,每个张量都包含相同数量的矩阵。
例如,input 是一个 (b×n×m) 张量,mat2 是一个 (b×m×p) 张量,输出将是一个 (b×n×p) 张量。
.Einops .
尽管 einops 是一个通用库,但在这里主要使用 einops.rearrange。
在 einops 中,方程字符串完全相同,但参数顺序与 einsum 颠倒了。你首先指定张量或张量列表。

从下划线的数量可以理解,这个操作会将维度中的一些合并到一起(组合)。在箭头字符串的左侧,我们有 4 个输入维度,而在右侧,仅剩下三个。
虽然运算表达式在形式上与 einsum 有些类似,但意义不同,在 einsum 那里能意味着沿若干个轴求和(sum)。
einops 还能灵活地分解轴!下面是一个例子:
# 随机生成一个张量,仅用于演示
qkv = torch.rand(2,128,3*512)
# 分解成 n=3 个张量 q, v, k
# rearrange 张量为 [3, batch, tokens, dim]
q, k, v = tuple(rearrange( qkv , 'b t (d n) -> n b t d ', n=3))
我们将轴分解成 3 个相等的部分!请注意,为了分解轴,你需要指定分解的具体形式,比如上面的 (d 3),但要注意它与 (3 d) 的区别。tuple 命令将使用第一个张量的维度,它将创建一个包含 n=3 个张量的元组。
约定:在本文中,我在对单个张量进行操作时使用
einops.rearrange,在对多个张量进行求和操作时使用torch.einsum。
.轴索引规则 .
与 einops 的区别在于,你可以使用多个小写字母来索引维度。例如,你可以这样子来展平一个 2D 张量:abc, defg -> (abc defg)。为方便起见,我们在 torch.einsum 操作中使用单个字母进行索引。
我们将根据算法中涉及的数学公式来将自注意力模块分解成若干个步骤。
2Scaled 点积自注意力
第 1 步:创建线性投影。
给定输入
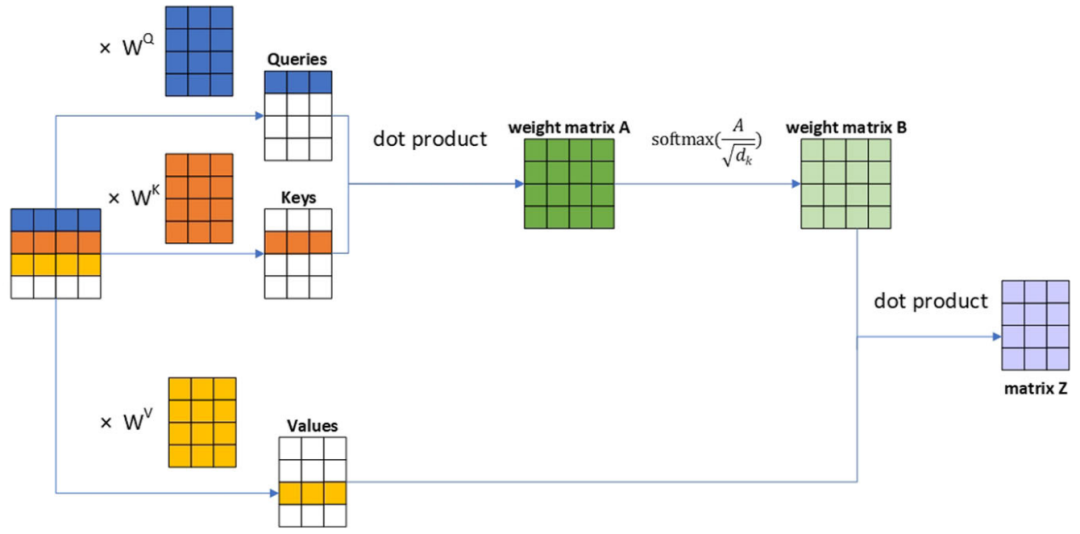
为了更轻松理解各个步骤,不妨对公式给些图示。如下图,我们假设
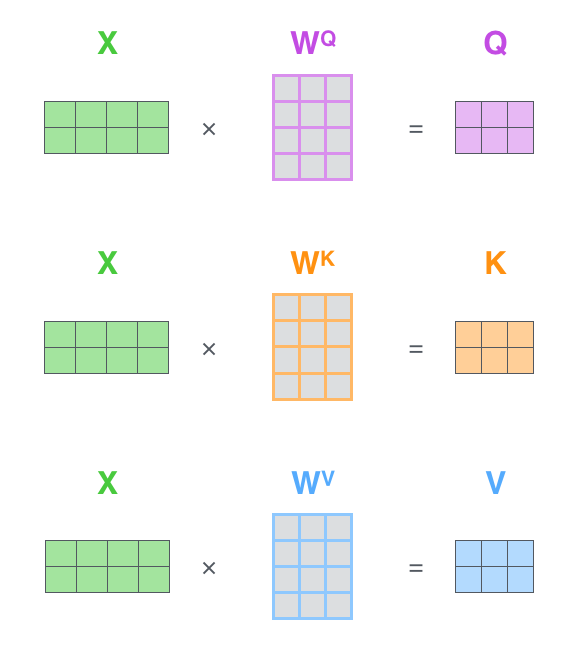
# 初始化
to_qvk = nn.Linear(dim, dim * 3, bias=False)
# 步骤 1
qkv = to_qvk(x) # [batch, tokens, dim*3 ]
# 分解为 q,v,k
q, k, v = tuple(rearrange(qkv, 'b t (d k) -> k b t d ', k=3))
第 2 步: 计算 scaled 点积,应用 mask(如果需要的话),最后计算
# 输出张量的 shape: [batch, tokens, tokens]
scaled_dot_prod = torch.einsum('b i d , b j d -> b i j', q, k) * self.scale_factor
if mask is not None:
assert mask.shape == scaled_dot_prod.shape[1:]
scaled_dot_prod = scaled_dot_prod.masked_fill(mask, -np.inf)
attention = torch.softmax(scaled_dot_prod, dim=-1)
第 3 步:将分数与
torch.einsum('b i j , b j d -> b i d', attention, v)
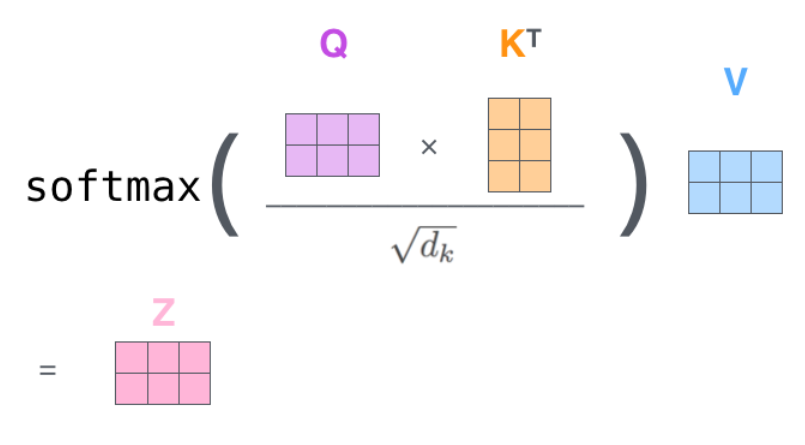
看另一个较完整的图,这里
.自注意力完整实现 .
import numpy as np
import torch
from einops import rearrange
from torch import nn
class SelfAttentionAISummer(nn.Module):
"""
Implementation of plain self attention mechanism with einsum operations
Paper: https://arxiv.org/abs/1706.03762
Blog: https://theaisummer.com/transformer/
"""
def __init__(self, dim):
"""
Args:
dim: for NLP it is the dimension of the embedding vector
the last dimension size that will be provided in forward(x),
where x is a 3D tensor
"""
super().__init__()
# for Step 1
self.to_qvk = nn.Linear(dim, dim * 3, bias=False)
# for Step 2
self.scale_factor = dim ** -0.5 # 1/np.sqrt(dim)
def forward(self, x, mask=None):
assert x.dim() == 3, '3D tensor must be provided'
# Step 1
qkv = self.to_qvk(x) # [batch, tokens, dim*3 ]
# decomposition to q,v,k
# rearrange tensor to [3, batch, tokens, dim] and cast to tuple
q, k, v = tuple(rearrange(qkv, 'b t (d k) -> k b t d ', k=3))
# Step 2
# Resulting shape: [batch, tokens, tokens]
scaled_dot_prod = torch.einsum('b i d , b j d -> b i j', q, k) * self.scale_factor
if mask is not None:
assert mask.shape == scaled_dot_prod.shape[1:]
scaled_dot_prod = scaled_dot_prod.masked_fill(mask, -np.inf)
attention = torch.softmax(scaled_dot_prod, dim=-1)
# Step 3
return torch.einsum('b i j , b j d -> b i d', attention, v)
注意 softmax 沿哪个轴操作很重要,这里我们使用了最后一个轴。
另外,我们为线性投影使用了单个线性层,这没问题,因为它应用了 3 次相同操作。最后我们将其分解为
3多头自注意力
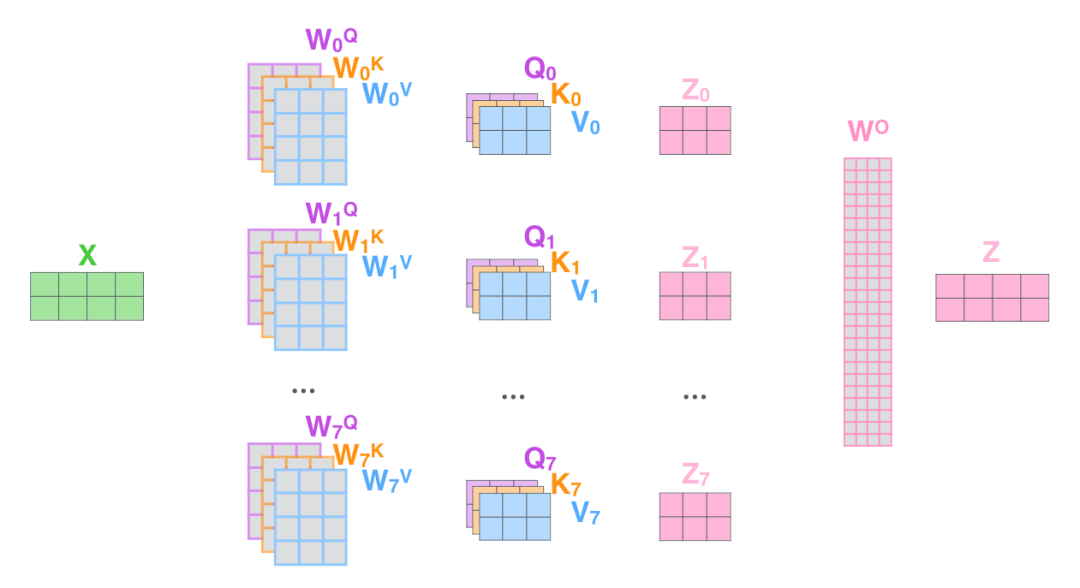
让我们看看如何在计算中引入多个头,而这种类型的注意力被称为多头自注意力(MHSA)。
直观地看,我们将在低维空间(代码中的 dim_head)中执行多次计算,多次计算是完全独立的。它在概念上类似于 batch size,你可以把它看成是一批低维的 self-attention。这也是 einsum 表现惊人的地方。

单个头,
多个头拼接,
上式右端对应下图,

完整的多头图示,
.MHSA 的实现 .
import numpy as np
import torch
from einops import rearrange
from torch import nn
class MultiHeadSelfAttentionAISummer(nn.Module):
def __init__(self, dim, heads=8, dim_head=None):
"""
Implementation of multi-head attention layer of the original transformer model.
einsum and einops.rearrange is used whenever possible
Args:
dim: token's dimension, i.e. word embedding vector size
heads: the number of distinct representations to learn
dim_head: the dim of the head. In general dim_head However, it may not necessary be (dim/heads)
"""
super().__init__()
self.dim_head = (int(dim / heads)) if dim_head is None else dim_head
_dim = self.dim_head * heads
self.heads = heads
self.to_qvk = nn.Linear(dim, _dim * 3, bias=False)
self.W_0 = nn.Linear( _dim, dim, bias=False)
self.scale_factor = self.dim_head ** -0.5
def forward(self, x, mask=None):
assert x.dim() == 3
# Step 1
qkv = self.to_qvk(x) # [batch, tokens, dim3heads ]
# Step 2
# decomposition to q,v,k and cast to tuple
# the resulted shape before casting to tuple will be:
# [3, batch, heads, tokens, dim_head]
q, k, v = tuple(rearrange(qkv, 'b t (d k h) -> k b h t d ', k=3, h=self.heads))
# Step 3
# resulted shape will be: [batch, heads, tokens, tokens]
scaled_dot_prod = torch.einsum('b h i d , b h j d -> b h i j', q, k) * self.scale_factor
if mask is not None:
assert mask.shape == scaled_dot_prod.shape[2:]
scaled_dot_prod = scaled_dot_prod.masked_fill(mask, -np.inf)
attention = torch.softmax(scaled_dot_prod, dim=-1)
# Step 4. Calc result per batch and per head h
out = torch.einsum('b h i j , b h j d -> b h i d', attention, v)
# Step 5. Re-compose: merge heads with dim_head d
out = rearrange(out, "b h t d -> b t (h d)")
# Step 6. Apply final linear transformation layer
return self.W_0(out)
参考资料
https://theaisummer.com/einsum-attention/
[2]https://jalammar.github.io/illustrated-transformer/