 ACM比赛整理
ACM比赛整理




一、什么是比特币
比特币是一种电子货币,是一种基于密码学的货币,在2008年11月1日由中本聪发表比特币白皮书,文中提出了一种去中心化的电子记账系统,我们平时的电子现金是银行来记账,因为银行的背后是国家信用。去中心化电子记账系统是参与者共同记账。比特币可以防止主权危机、信用风险。其好处不多做赘述,这一层面介绍的文章很多,本文主要从更深层的技术原理角度进行介绍。
二、问题引入
假设现有4个人分别称之为ABCD,他们之间发起了3个交易,A转给B10个比特币,B转给C5个比特币,C转给D2个比特币。如果是传统的记账方式,这些交易会记录在银行的系统中,这些信息由银行来记录,我们相信银行不会随意添加、删除或修改一条交易记录,我们也不会关注到底有哪些交易,我们只关注自己的账户余额。而比特币的记账方式为ABCD每个人保存了这样一份账本,账本上记录了上述交易内容,如果每个人账本实时的一致,ABCD就不再需要银行。
比特币是这样做的,每当有人发起一笔交易,他就要将一笔交易广播至全网,由全网中的某一个人,把一段时间内的交易打包好记录到一个区块上,再按照顺序把这些区块,一个一个的链接在一起,进而形成了一个链条,这就是所谓的区块链。

那么问题来了
1、我凭什么要参与这个系统,我为什么要动用自己的计算机资源来存储这些信息呢?
2、以谁的记录为准呢?比如上面的账单顺序,A用户可能是这个顺序,但是B可能顺序不一样,甚至可能B根本就没有接收到C给D转账的这个消息。
3、比特币如果做到支付功能,保证该是谁的钱就是谁的钱,而且只有其所有者才能花。
4、如何防伪、防篡改以及双重支付,防伪是验证每条交易的真的是某人发出的,比如B可能杜撰一条消息,说某某给我转了一笔钱,这就是一个假消息,或者B说我给某人转了多少钱,但是实际上他并没有这么多钱,又怎么办。防篡改指的是B可能想从区块链上把自己曾经转给某人钱的记录删掉,这样他的余额就会增加。双重支付是指,B只有10比特币,他同时向C和D转10个比特币,造成双重花费。
三、为什么要记账?
因为记账有奖励,记账有手续费的收益,而且打包区块的人有系统奖励,奖励方案是,每十分钟生成一个区块,每生成一个区块会奖励一定数量的比特币,最开始是50个BTC,过4年会奖励25个BTC,再过4年再减少一半,以此类推。这样比特币的产生会越来越少,越来越趋近于一个最大值,计算公式是:50×6×24×365×4×(1+1/2+1/4+1/8+…)≈2100万,其中最初奖励50个比特币,每小时有6个区块,每天24小时,每年365天,前四年是如此,之后每四年减半。
此外,记账奖励还有每笔交易的小额手续费,每个交易发起都会附带一定的手续费,这些手续费是给记账的矿工的。
四、以谁为准?
各个节点通过工作量证明机制来争夺记账权,他们计算一个很复杂的数学题,第一个计算出来的节点就是下一个区块的产生者。这个数学题很难,难到没有一个人能同过脑子算出来,它是基于概率的方法,矿工必须通过遍历、猜测和尝试的办法才能解开这个未知数。那么这个数学难题到底是什么呢?下面详细介绍。
4.1哈希函数
哈希函数又称为数字摘要或散列函数,它的特点是输入一个字符串,可以生成另外一个字符串,但是如果输入不同,输出的字符串就一定不同,而且通过输出的字符串,不能反推出输入。举个简单的例子,对1-100内的数模10,可以认为是一种哈希方法,比如98%10=8,66%10=6,98和66是输出,模10是哈希函数,8和6是输出,在这个模型中,通过6和8无法推断输入是66和98,因为还可能是56和88等,当然因为这个例子比较简单,所以会出现哈希碰撞,即66和56的结果都是6,输出的结果相同。一个优秀的哈希函数,可以做到输出一定不同,哈希碰撞的概率几乎为0。常见的哈希函数有很多,比如MD系列和SHA系列等,比特币采用的SHA256算法,即输入一个字符串,输出一个256位的二进制数。下面是程序运行的结果。


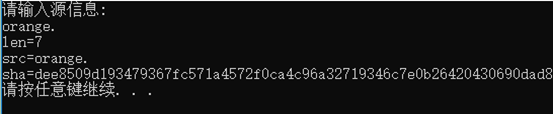
通过程序结果可以看出,输入的源信息不同,得到的结果也不同(为了方便,结果用64位16进制表示),即使是orange多了一个句号,也会产生截然不同的结果。同时,通过输出的十六进制字符串,也无法倒推出输入。对于比特币,只要了解SHA256的功能即可,如果感兴趣可以深入了解SHA256的具体算法。需要SHA256的C++源码留言邮箱或私信。
4.2挖矿原理
首先介绍一下比特币每个区块的数据结构,每个区块由区块头和区块体两部分组成。
区块体中包含了矿工搜集的若干交易信息,图中假设有8个交易被收录在区块中,所有的交易生成一颗默克尔树,默克尔树是一种数据结构,它将叶子节点两两哈希,生成上一层节点,上层节点再哈希,生成上一层,直到最后生成一个树根,称之为默克尔树根,只有树根保留在区块头中,这样可以节省区块头的空间,也便于交易的验证。
区块头中包含父区块的哈希,版本号,当前时间戳,难度值,随机数和上面提到的默克尔树根。
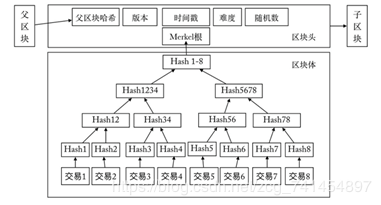
假设区块链已经链接到了某个块,有ABCD四个节点已经搜集了前十分钟内全网中的一些交易信息,他们选出其中约4k条交易,打包好,生成默克尔树根,将区块头中的信息,即发区块哈希+版本号+时间戳+难度值+随机数+默克尔树根组成一个字符串str,通过两次哈希函数得出一个256的二进制数,即SHA256(SHA256(str)) = 10010011……共256位,比特币要求,生成的结果,前n位必须是0,n就是难度值,如果现在生成的二进制数不符合要求,就必须改变随机数的值,重新计算,只到算出满足条件的结果为止。假设现在n是5,则生成的二进制数必须是00000……(共256位)。一旦挖矿成功,矿工就可以广播这个消息到全网,其他的矿工就会基于该区块继续挖矿。下一个区块头中的父区块哈希值就是上一个区块生成的00000……这个数。
解决这个数学难题要靠运气,理论上,运气最好的矿工可能1次哈希就能算出结果,运气差的可能永远都算不出来。但是总体来看,如果一个矿工的算力越大,单位时间内进行的哈希次数就越多,就越可能在短时间内挖矿成功。
那么n是如何确定的呢?比特币设计者希望,总体上平均每十分钟产生一个区块,总体上来看,挖矿成功的概率为1/2^n。现假设世界上有1W台矿机,每台矿机的算力是14T次/s = 1.4×10^13次/s,单位次/s称之为哈希率,10分钟是600s,所以10分钟可以做8×10^19次哈希运算,从概率角度看,想要挖矿成功需要做2^n次运算,可以列出等式2^n = 8×10^19,可以解出n约为66。所以对于这种方法,我们没有办法使得自己的运气变的更好,只能提高自己的算力,尽快的算出结果。
另外,需要模拟挖矿过程的C++代码可以回复邮箱,代码可以通过调整难度值,模拟比特币的挖矿算法,控制区块产生的速度。
五、如何防伪、防篡改、防双重支付等问题
这部分是理解比特币很重要的部分。
5.1电子签名技术
身份认证技术在生活中很常见,可以是人脸识别、签字、指纹等,但是这些方法在数字货币领域并不安全,因为它们一旦数字化,都可以通过复制的方法伪造。所以比特币采用了电子签名的方法。
注册成为比特币用户时,系统会根据随机数生成一个私钥,私钥会生成一个公钥,公钥又会生成一个地址,其中私钥必须保密,可以保存到硬盘里或者记到脑子里,因为这个私钥是使用相应地址上的比特币的唯一标识,一旦丢失,所有的比特币将无法使用。下面介绍具体的转换过程,不感兴趣可以不看,只要知道随机数->私钥->公钥->钱包地址这个过程,其中私钥可以对一串字符进行加密,而公钥可以对其进行解密,这就是非对称加密,这类算法总体上的功能都是一样的,只是具体算法有区别,由于这些算法比较复杂,与SHA265算法一样不多做介绍,感兴趣可以深入了解具体算法,但是对于比特币系统,只要了解其功能即可。典型的算法是RSA,比特币采用椭圆曲线加密算法。
转换过程(选读,不影响理解)
1、首先使用随机数发生器生成一个私钥,它是一个256位的二进制数。私钥是不能公开的,相当于银行卡的密码。
2、私钥经过SECP256K1算法生成公钥,SECP256K1是一种椭圆曲线加密算法,功能和RSA算法类似,通过一个已知的私钥,生成一个公钥,但是通过公钥不能反推出私钥。
3、同SHA256算法一样,RIPEMD160也是一种HASH算法,由公钥可以得到公钥的哈希值,而通过哈希值无法推出公钥。
4、将一个字节的版本号连接到公钥哈希头部,然后对其进行两次SHA256运算,将结果的前4字节作为公钥哈希的校验值,连接在其尾部。
5、将上一步的结果使用BASE58进行编码,就得到了钱包地址(相当于银行账户)。比如A1zP1eP5QGefi2DMPTfTL5SLmv7DivfNa
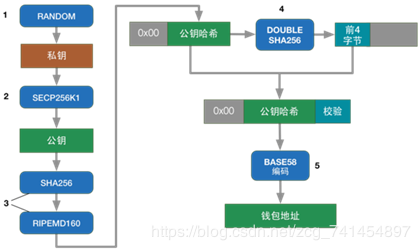
所以,通过以上的过程我们可以总结出私钥、公钥、钱包之间的关系如下图。可以看到通过私钥可以推出所有的值,公钥哈希和钱包地址之间可以通过BASE58和BASE58解码算法相互转化。
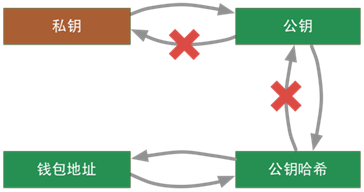
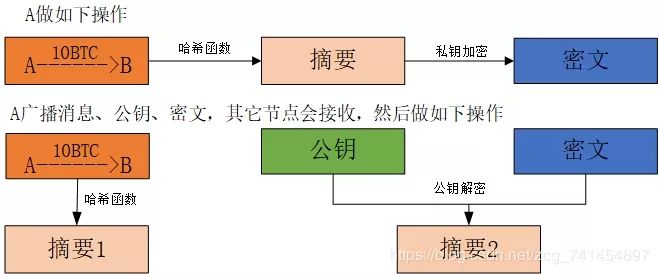
了解了公钥、私钥、地址的概念后,防伪验证的过程就很容易理解,当A发起一笔交易后,对消息进行哈希,生成数字摘要,对数字摘要,通过私钥加密,生成一个密码。之后A会广播这个条交易消息、公钥以及密码。收到消息的人首先对交易信息进行哈希生成摘要1,再通过公钥对密码进行解密,生成摘要2,这样,如果两个摘要相同,说明这个消息确实是A发出的。所谓的签名,就是密文。
5.2余额检查
余额的概念应该说根深蒂固,余额是伴随着称之为借贷记账法而产生的,也是目前银行普遍采用的方法,将一个人的交易记录统计好后算出一个余额,但是在比特币中没有余额这个概念,因为其采用的是UXTO模型的记账方法。比如A->B10个比特币,B->C5个比特币,对于第二笔交易来说,B在发起这笔交易时要注明第一笔交易的信息,这样就可以知道B曾经从A那里收到过10个比特币,说明满足第二笔交易发起的条件。所以比特币中余额的检查是通过追溯的方法。
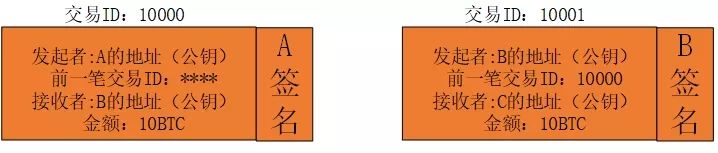 上图描述了两笔交易,交易10001中,B向C转了10个比特币,验证这笔交易的过程是:首先将B的签名通过B的公钥解密,然后再和交易的具体内容(B签名左侧)对比,如果相同,说明消息是B发出的,然后再检查10000这个交易是否真的存在以及它的内容的真实性。这两点都满足了,就说明交易10001是可以被接受的,否则拒绝接受。
上图描述了两笔交易,交易10001中,B向C转了10个比特币,验证这笔交易的过程是:首先将B的签名通过B的公钥解密,然后再和交易的具体内容(B签名左侧)对比,如果相同,说明消息是B发出的,然后再检查10000这个交易是否真的存在以及它的内容的真实性。这两点都满足了,就说明交易10001是可以被接受的,否则拒绝接受。
实际上,真实的交易比这个复杂的多,因为有可能是多笔交易构成了输入,比如B->C20个比特币,是由多笔交易A->B10,D->B10构成的,则前一笔交易ID就是两个ID,甚至可能更多。这里为了简单描述,只列举一笔交易。
5.3双重支付
A同时发了两条消息,同时给B和C转了10个比特币,实际上他只有10个会怎么样?假设D节点先收到了转给B10个BTC,然后收到了转给C10个比特币,通过上面的验证方法,自然会拒绝后面的一个,与此同时,E节点可能先收到了转给C10个BTC,然后收到了转给B10个比特币,他自然会拒绝后者。至于哪一笔交易最终会上链,就要看D和E哪个先解决难题,成功挖矿。
5.4防止篡改
假设A转给B10个比特币,但是他想把这个信息从区块链上删除,这样大家就都不知道这个事情存在,就可以赖账。
首先说一下最长链原则,假设某一个区块后面有两个矿工同时挖到了矿,或者由于网络延迟等原因产生了分歧,这时,各个节点先随意根据自己认为对的区块挖矿,只到下一个区块产生,这时会有两条链,但是有一条是长的,比特币规定,以最长的链为准。如果某个节点仍然的固执的以较短的链为准,他就是在和大多数算力作对,这样做的结果是,他挖的块不被大家认可,会浪费时间和算力。
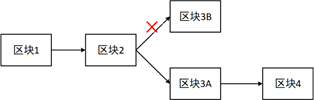
回到上面的场景,A想赖账,就只能从记录了A->B10个比特币这个消息的区块的前一个区块开始重新挖矿,造出一个支链来,但是实际上的区块已经前进了很多,他只能不停的追赶,而且在追赶的同时,主链也在前进,他必须以比主链快的速度前进,如果他的算力足够大,理论上通过较长的时间确实可以追赶成功,就实现了对交易信息的篡改。然而其实这几乎是不可能的,因为就算算力再大,平均出块速度也是10分钟,从非技术的角度讲,一个人如果掌握了全网一半以上的算力,他为什么不在主链上继续挖矿呢?一个富可敌国的人应该不会甘愿去做一个小偷吧。
六、总结
区块链并不等同于比特币,比特币也不是区块链,区块链只是比特币应用的一种技术,这个技术能给我们带来启发,比特币的伟大之处在于应用了前所未有的区块链技术。区块链技术还能在哪些方面应用还需继续探索。
比特币是区块链技术最成功的应用,但是比特币本身也有很多问题,它想通过发行货币来挑战主权货币,这个动机有待商榷。此外,由于比特币的匿名性,只需要一个公钥或地址就能进行交易,为黑色产业提供了很好的平台。另外,比特币并不是一个成熟的支付系统,它具有吞吐率低,可拓展性差等缺点。
可能文字还是比较苍白,可以看看李永乐老师讲解的视频,虽然没有这个详细,但是通俗易懂。


