 Python绿色通道
Python绿色通道




二条:精华!12大Pandas常用配置技巧!
三条: 一行 Python 代码实现文件共享..
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
大家好,我是龙哥!

本文用 python 爬虫抓取“发表情”网站(https://fabiaoqing.com/)的表情包。
分析思路
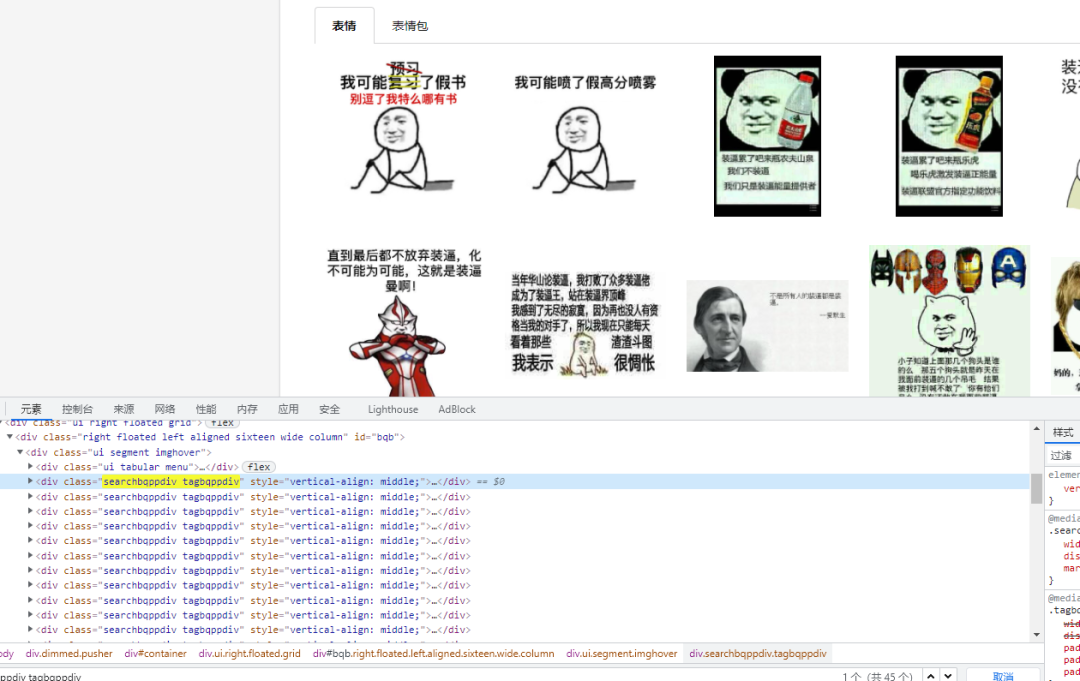
打开网站,搜索【装逼】关键字的表情包,并且打开 F12 控制面板,可以看到每个表情包都被包含在 div 元素里面,并且在翻页的时候可以从 url 地址上可以看出第一页的最后数字是 1,第二页是 2,第三页是 3。这就好办了,只要改变数字就可以了。
下面开始码代码,首先定义一个 header 请求头,然后就用 request.get() 抓取页面,并且在输出页面 html 的时候使用 utf-8 的编码格式。
import os
import requests,re
def get_html(search_key, page):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
'Host': 'www.fabiaoqing.com'
}
key_url = 'https://fabiaoqing.com/search/bqb/keyword/{}/type/bq/page/{}.html'.format(search_key, page)
resp = requests.get(key_url, headers=header)
resp.encoding='utf-8'
return resp.text
继续查看网页源码,表情图片就藏在 div 层下的 img 表情中,用正则表达式解析提取 img 的 src 属性。当没有提取到表情包的 src 时,表示这页已经是最后一页了。

def get_src(html):
srcs = re.findall('<img class="ui image bqppsearch lazy" data-original="(.*?)" title="(.*?)"',html,re.S)
return srcs
最后用 urlretrieve 下载表情包。
def downlaod(srcs, path):
from urllib.request import urlretrieve
for item in srcs:
print(item[2])
urlretrieve(item[0], path + '\\' + item[2].replace('\n', '') + '.png')

总结
用简单的 python 爬虫,抓取了源源不断的表情包来斗图,小伙伴们也可以把 python 用在其他的日常中。
推荐阅读

