 七月在线实验室
七月在线实验室





问题1:lstm原理三个门作用和sigmoid函数tanh使用,梯度消失问题如何解决,rnn为什么不能,缺点如何造成的。lstm如何解决长期记忆问题 。
LSTM是循环神经网络RNN的变种,包含三个门,分别是输入门,遗忘门和输出门。
sigmoid函数主要是决定什么值需要更新;
tanh函数:创建一个新的候选值向量,生成候选记忆。
rnn梯度消失的原因:很难捕捉到长期的依赖关系,因为乘法梯度可以随着层的数量呈指数递减/递增。
LSTM中ct到ct-1的路径上梯度不会消失,并不能保证其他路径上梯度不会消失。LSTM可以缓解梯度消失,并不能消除,所以其可以解决RNN长期依赖的问题。

问题2:bert原理和注意力机制介绍一下。
bert原理:bert是基于Transformer encoder的双向编码器,模型输入包含token embedding、position embedding、segment embedding;
输出包含CLS及每个字对应的向量表示,预训练任务为MLM与NSP。
注意力机制就是对输入权重分配的关注,最开始使用到注意力机制是在编码器-解码器(encoder-decoder)中, 注意力机制通过对编码器所有时间步的隐藏状态做加权平均来得到下一层的输入变量。
问题3:召回和排序中有哪些模型,原理都了解吗?
召回模型:Youtube DNN、DSSM双塔模型、MIND用户多兴趣网络
排序模型:FM、Wide&Deep Model,DeepFM, Deep&Cross、DIN、DIEN、DSIN、BST等等。
问题4:lr特征为什么要离散化
数据角度:离散化的特征对异常数据有很强的鲁棒性;离散化特征利于进行特征交叉。
模型角度:当数据增加/减少时,利于模型快速迭代;
离散化相当于为模型引入非线性表达;
离散化特征简化了模型输入,降低过拟合风险;
LR中离散化特征很容易根据权重找出bad case。
计算角度:稀疏向量内积计算速度快。(在计算稀疏矩阵内积时,可以根据当前值是否为0来直接输出0值,这相对于乘法计算是快很多的。)
问题5:auc公式是什么,如何一句话解释auc的含义,数据不平衡对auc有影响吗,还有什么指标可以针对不平衡数据。
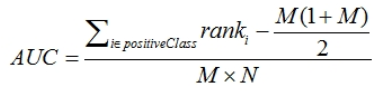
auc的直观含义是任意取一个正样本和负样本,正样本得分大于负样本的概率。
数据不平衡对auc影响不大。
对于不平衡数据还可以使用PR(Precision-Recall曲线)。
问题6:代码题:最长不重复子串
该题为leetcode第3题。
方法:双指针 + sliding window
定义两个指针 start 和 end 得到 sliding window
start 初始为0,用end线性遍历每个字符,用 recod 记录下每个字母最新出现的下标两种情况:
一种是新字符没有在 record 中出现过,表示没有重复,一种是新字符 char 在 record 中出现过,说明 start 需要更新,取 start 和 record[char]+1 中的最大值作为新的 start。
需要注意的是:两种情况都要对record进行更新,因为是新字符没在record出现过的时候需要添加到record中,而对于出现过的情况,也需要把record中对应的value值更新为新的下标。
代码如下:

时间复杂度:O(n)
空间复杂度:O(1)
问题7:针对不平衡样本问题,在通过上采样后,正例:负例的比值由1:10变为2:10,则dnn模型预测的概率会增大多少,若想要当前输出概率和原始期望想同,则需要如何操作 。
会从1/11增大到1/6。
需要除以对应的增长倍数,来保证期望值不变。类似于dropout的使用方法,在使用dropout后需要在输出下一层之前除以这个dropout。
问题8:dnn如何评估特征有效性和重要性,其他机器学习模型呢?
训练后使用OOB(Out of Bag)数据计算第二种方式是训练好模型之后,用Out of Bag(或称Test)数据进行特征重要性的量化计算。
具体来说,先用训练好的模型对OOB数据进行打分,计算出AUC或其他业务定义的评估指标;
接着对OOB数据中的每个特征:
(1)随机shuffle当前特征的取值;
(2)重新对当前数据进行打分,计算评估指标;
(3)计算指标变化率按照上面方式,对每个特征都会得到一个变化率,最后按照变化率排序来量化特征重要性。
参考代码如下:

机器学习模型:如Xgboost模型
训练过程中计算训练过程中通过记录特征的分裂总次数、总/平均信息增益来对特征重要性进行量化。
例如实际工程中我们会用特征在整个GBDT、XgBoost里面被使用的次数或者带来的总/平均信息增益来给特征重要度打分,最后进行排序。
由于本身Ensemble模型在选择特征分裂时带有一定随机性,一般会跑多个模型然后把特征重要性求平均后排序。

— 免费资源 —
今天小七妹给大家分享一下可能用到的数据集,包含NLP(自然语言处理)、CV、kaggle、ML等各个方向,感兴趣的小伙伴可以收藏,以备不时之需。
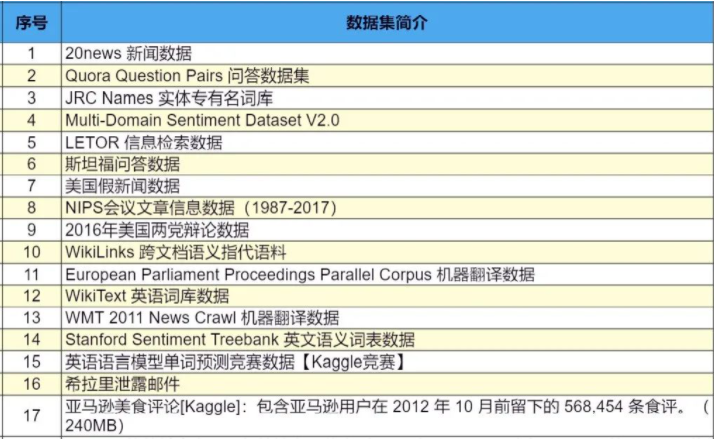
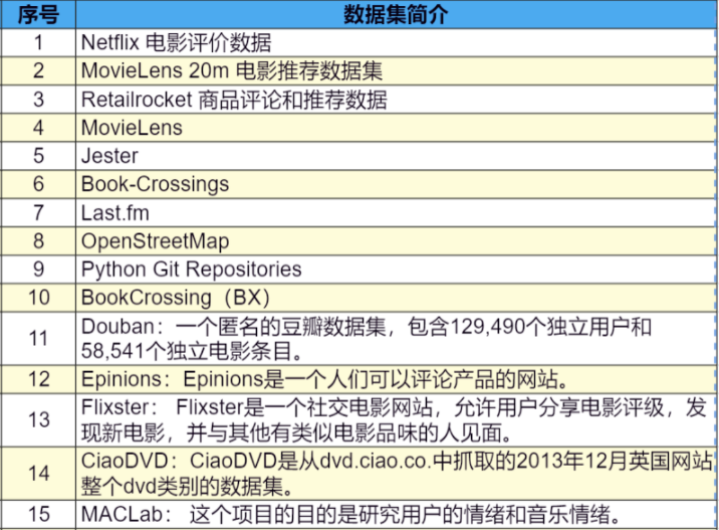
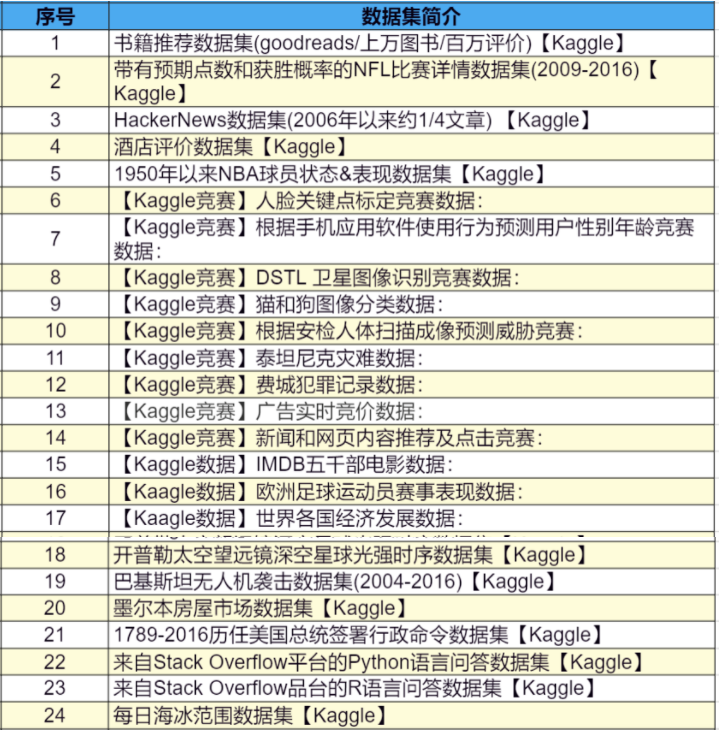
(以上是部分数据集,限于篇幅,完整版及链接扫码免费领)
扫码回复“数据集” 👇领取完整版数据集👇


戳↓↓“阅读原文”领取面试资料!

