 大邓和他的Python
大邓和他的Python





使用文本相似度可以识别变化的时间点,先配置环境
配置环境
!pip3 install scikit-learn==1.0
!pip3 install cntext==1.2
# 安装pyecharts可视化
!pip3 install pyecharts==1.6.2
!pip3 install pyecharts-javascripthon==0.0.6
!pip3 install pyecharts-jupyter-installer==0.0.3
!pip3 install pyecharts-snapshot==0.2.0
1. 查看数据
本次使用sotu数据集,收集了从1790年至2018年国情咨文文本,这是漂亮国大统领每年发表的演讲,用于描述国家过去的成就和未来面临的挑战。
import pandas as pd
df = pd.read_csv('sotu.csv')
#text2是text向下顺移1位的结果
df['text2']=df['text'].shift(1)
#剔除空字符
df.dropna(inplace=True)
df.tail(10)
两段文本的相似度可以通过cos计算
from cntext.similarity import similarity_score
text1 = 'Mr. Speaker, Mr. Vice President, members of'
text2 = 'Thank you very much. Mr. Speaker, Mr. Vice'
similarity_score(text1, text2)
{'Sim_Cosine': 0.4629100498862757,
'Sim_Jaccard': 0.3,
'Sim_MinEdit': 16,
'Sim_Simple': 0.9619883040935673}
2. 相似度可视化
如果把很多个相邻文本(有时间先后顺序)依次计算相似度,可以绘制出曲线,我们根据自己的领域知识,就可以看出变化的时间点。
from cntext.similarity import similarity_score
cosines = []
for idx, row in df.iterrows():
text1 = df.loc[idx, 'text']
text2 = df.loc[idx, 'text2']
simi = similarity_score(text1, text2)['Sim_Cosine']
cosines.append(simi)
cosines
[0.42767330405703097,
0.39821498388325544,
0.410744931596176,
0.3844380358041578,
0.4116242706522565,
0.4169268094228332,
0.4249719376001671,
....
0.39065212923423315,
0.3763764307701755,
0.35307484669994105,
0.4119319787659037,
0.43053043053064594,
0.45219743197249296,
0.421723837550935,
0.427904362863808]
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.globals import CurrentConfig, NotebookType
CurrentConfig.NOTEBOOK_TYPE = NotebookType.JUPYTER_NOTEBOOK
line = Line()
line.add_xaxis(xaxis_data=[str(y) for y in df['year'].values])
line.add_yaxis("本期与上期的相似度",
cosines,
label_opts=opts.LabelOpts(is_show=False))
line.set_global_opts(title_opts=opts.TitleOpts(title="1790年至2018年国情咨文文本相似度"))
line.load_javascript()
line.render('1790年至2018年国情咨文文本相似度可视化.html')
line.render_notebook()
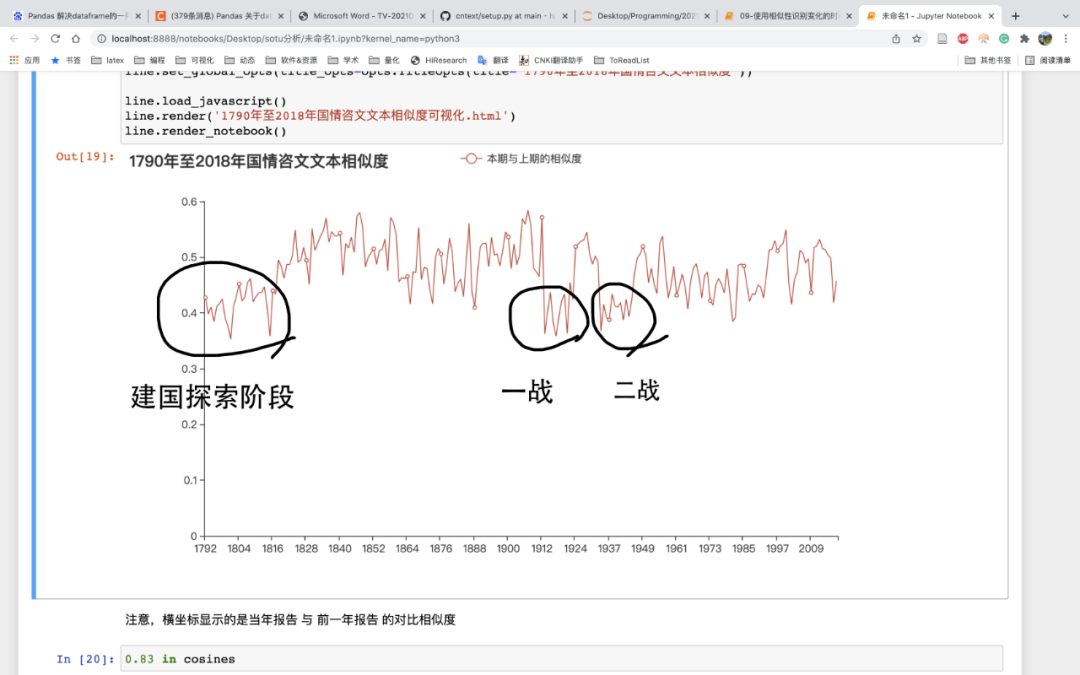
注意,横坐标显示的是当年报告 与 前一年报告 的对比相似度
3. 图形解读
相似度越低,说明本期与前期相比,文本变化较大,在本场景中可能是漂亮国在大幅度调整政策。
在图中,我们最熟悉的时期是一战和二战,这个阶段在图中较长时间处于低位,漂亮国zf的政策处于战时状态。
漂亮国立国初期,相似度连线也长时间处于低位,新国家正在探索(或创新)为政之道,那么政策前后期的相似性也会比较低。
漂亮国每4年选ju一次,那么换届年份,相似度也会比较低。
近期文章

