 机器学习初学者
机器学习初学者




本文是斯坦福大学 CS229 机器学习课程的基础材料,原始文件下载[1]
原文作者:Arian Maleki , Tom Do
翻译:石振宇[2]
审核和修改制作:黄海广[3]
备注:pdf版本下载。获取方式:
关注公众号,回复“CS229”可以获取下载地址。

CS229 机器学习课程复习材料-概率论
概率论复习和参考
概率论是对不确定性的研究。通过这门课,我们将依靠概率论中的概念来推导机器学习算法。这篇笔记试图涵盖适用于CS229的概率论基础。概率论的数学理论非常复杂,并且涉及到“分析”的一个分支:测度论。在这篇笔记中,我们提供了概率的一些基本处理方法,但是不会涉及到这些更复杂的细节。
1. 概率的基本要素
为了定义集合上的概率,我们需要一些基本元素,
样本空间:随机实验的所有结果的集合。在这里,每个结果 可以被认为是实验结束时现实世界状态的完整描述。
事件集(事件空间):元素 的集合(称为事件)是 的子集(即每个 是一个实验可能结果的集合)。
备注:需要满足以下三个条件:
(1)
(2)
(3)
概率度量:函数是一个的映射,满足以下性质:
对于每个 ,,
如果 是互不相交的事件 (即 当时, ), 那么:
以上三条性质被称为概率公理。
举例:
考虑投掷六面骰子的事件。样本空间为。最简单的事件空间是平凡事件空间.另一个事件空间是的所有子集的集合。对于第一个事件空间,满足上述要求的唯一概率度量由,给出。对于第二个事件空间,一个有效的概率度量是将事件空间中每个事件的概率分配为,这里 是这个事件集合中元素的数量;例如,。
性质:
如果,则: (布尔不等式): (全概率定律):如果是一些互不相交的事件并且它们的并集是,那么它们的概率之和是 1
1.1 条件概率和独立性
假设是一个概率非 0 的事件,我们定义在给定的条件下 的条件概率为:
换句话说,)是度量已经观测到事件发生的情况下事件发生的概率,两个事件被称为独立事件当且仅当(或等价地,)。因此,独立性相当于是说观察到事件对于事件的概率没有任何影响。
2. 随机变量
考虑一个实验,我们翻转 10 枚硬币,我们想知道正面硬币的数量。这里,样本空间的元素是长度为 10 的序列。例如,我们可能有
更正式地说,随机变量是一个的函数。通常,我们将使用大写字母或更简单的(其中隐含对随机结果的依赖)来表示随机变量。我们将使用小写字母来表示随机变量的值。
举例:在我们上面的实验中,假设是在投掷序列中出现的正面的数量。假设投掷的硬币只有 10 枚,那么只能取有限数量的值,因此它被称为离散随机变量。这里,与随机变量相关联的集合取某个特定值的概率为:
举例:假设是一个随机变量,表示放射性粒子衰变所需的时间。在这种情况下,具有无限多的可能值,因此它被称为连续随机变量。我们将在两个实常数和之间取值的概率(其中)表示为:
2.1 累积分布函数
为了指定处理随机变量时使用的概率度量,通常可以方便地指定替代函数(CDF、PDF和PMF),在本节和接下来的两节中,我们将依次描述这些类型的函数。
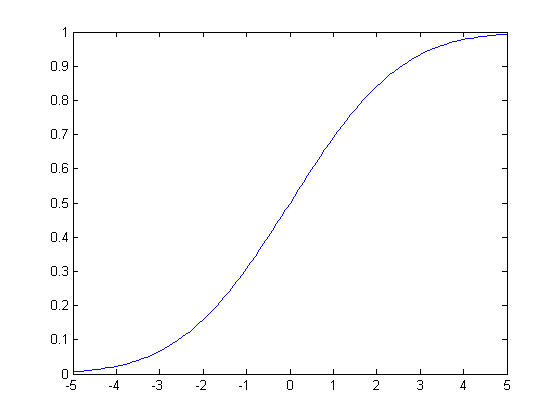
累积分布函数(CDF)是函数,它将概率度量指定为:
通过使用这个函数,我们可以计算任意事件发生的概率。图 1 显示了一个样本CDF函数。
2.2 概率质量函数
当随机变量取有限种可能值(即,是离散随机变量)时,表示与随机变量相关联的概率度量的更简单的方法是直接指定随机变量可以假设的每个值的概率。特别地,概率质量函数(PMF)是函数 ,这样:
在离散随机变量的情况下,我们使用符号表示随机变量可能假设的一组可能值。例如,如果是一个随机变量,表示十次投掷硬币中的正面数,那么。
性质:
2.3 概率密度函数
对于一些连续随机变量,累积分布函数处可微。在这些情况下,我们将概率密度函数(PDF)定义为累积分布函数的导数,即:
请注意,连续随机变量的概率密度函数可能并不总是存在的(即,如果它不是处处可微)。
根据微分的性质,对于很小的,
CDF和PDF(当它们存在时!)都可用于计算不同事件的概率。但是应该强调的是,任意给定点的概率密度函数(PDF)的值不是该事件的概率,即。例如,可以取大于 1 的值(但是在的任何子集上的积分最多为 1)。
性质:
2.4 期望
假设是一个离散随机变量,其PMF为 ,是一个任意函数。在这种情况下,可以被视为随机变量,我们将的期望值定义为:
如果是一个连续的随机变量,其PDF 为,那么的期望值被定义为:
直觉上,的期望值可以被认为是对于不同的值可以取的值的“加权平均值”,其中权重由或给出。作为上述情况的特例,请注意,随机变量本身的期望值,是通过令得到的,这也被称为随机变量的平均值。
性质:
对于任意常数 , 对于任意常数 , (线性期望): 对于一个离散随机变量,
2.5 方差
随机变量的方差是随机变量的分布围绕其平均值集中程度的度量。形式上,随机变量的方差定义为:
使用上一节中的性质,我们可以导出方差的替代表达式:
其中第二个等式来自期望的线性,以及相对于外层期望实际上是常数的事实。
性质:
对于任意常数 , 对于任意常数 ,
举例:
计算均匀随机变量的平均值和方差,任意,其PDF为 ,其他地方为 0。
举例:
假设对于一些子集,有,计算?
离散情况:
连续情况:
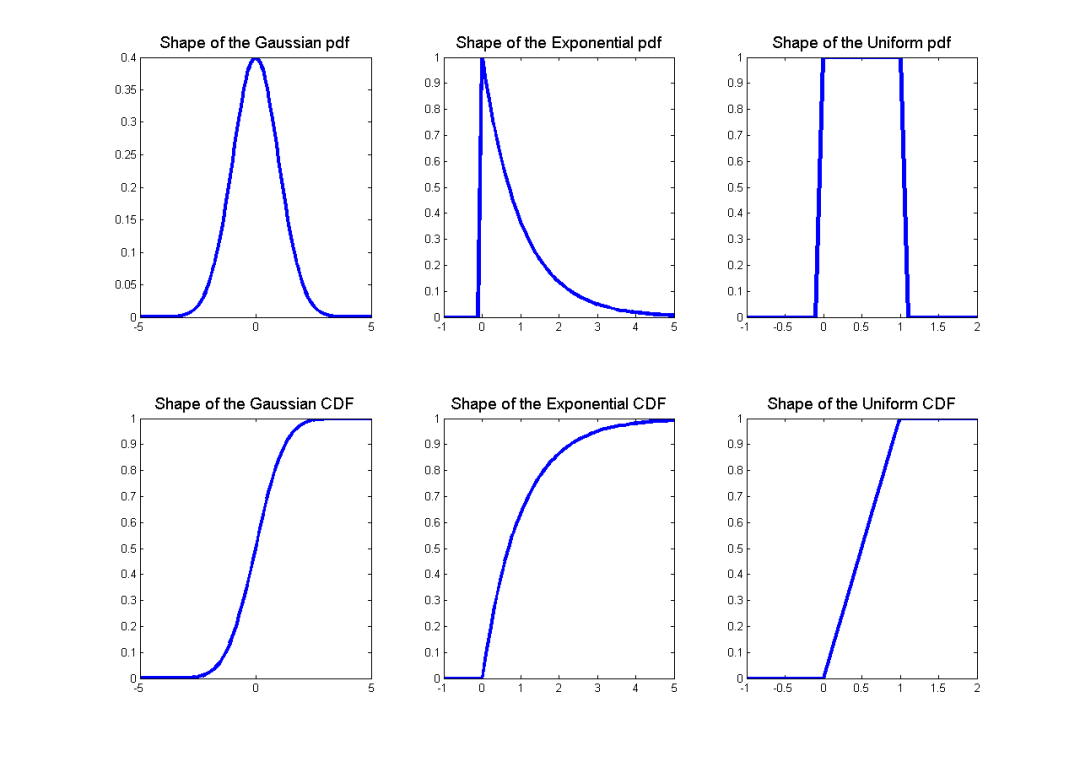
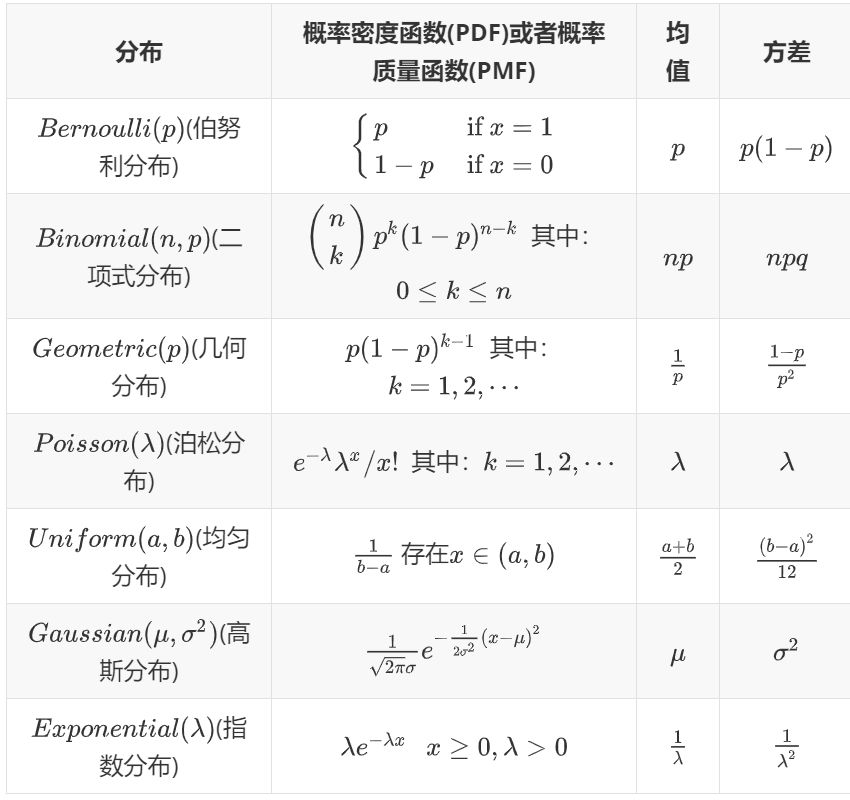
2.6 一些常见的随机变量
离散随机变量
伯努利分布:硬币掷出正面的概率为(其中:),如果正面发生,则为 1,否则为 0。
二项式分布:掷出正面概率为(其中:)的硬币次独立投掷中正面的数量。
几何分布:掷出正面概率为(其中:)的硬币第一次掷出正面所需要的次数。
泊松分布:用于模拟罕见事件频率的非负整数的概率分布(其中:)。
连续随机变量
均匀分布:在和之间每个点概率密度相等的分布(其中:$a
指数分布:在非负实数上有衰减的概率密度(其中:)。
正态分布:又被称为高斯分布。
一些随机变量的概率密度函数和累积分布函数的形状如图 2 所示。
3. 两个随机变量
到目前为止,我们已经考虑了单个随机变量。然而,在许多情况下,在随机实验中,我们可能有不止一个感兴趣的量。例如,在一个我们掷硬币十次的实验中,我们可能既关心出现的正面数量,也关心连续最长出现正面的长度。在本节中,我们考虑两个随机变量的设置。
3.1 联合分布和边缘分布
假设我们有两个随机变量,一个方法是分别考虑它们。如果我们这样做,我们只需要和。但是如果我们想知道在随机实验的结果中,和同时假设的值,我们需要一个更复杂的结构,称为和的联合累积分布函数,定义如下:
可以证明,通过了解联合累积分布函数,可以计算出任何涉及到和的事件的概率。
联合CDF: 和每个变量的联合分布函数和分别由下式关联:
这里我们称和为 的边缘累积概率分布函数。
性质:
3.2 联合概率和边缘概率质量函数
如果和是离散随机变量,那么联合概率质量函数 由下式定义:
这里, 对于任意,,, 并且
两个变量上的联合 PMF分别与每个变量的概率质量函数有什么关系?事实上:
对于类似。在这种情况下,我们称为的边际概率质量函数。在统计学中,将一个变量相加形成另一个变量的边缘分布的过程通常称为“边缘化”。
3.3 联合概率和边缘概率密度函数
假设和是两个连续的随机变量,具有联合分布函数。在在和中处处可微的情况下,我们可以定义联合概率密度函数:
如同在一维情况下,
请注意,概率密度函数的值总是非负的,但它们可能大于 1。尽管如此,可以肯定的是
与离散情况相似,我们定义:
作为的边际概率密度函数(或边际密度),对于也类似。
3.4 条件概率分布
条件分布试图回答这样一个问题,当我们知道必须取某个值时,上的概率分布是什么?在离散情况下,给定的条件概率质量函数是简单的:
假设分母不等于 0。
在连续的情况下,在技术上要复杂一点,因为连续随机变量的概率等于零。忽略这一技术点,我们通过类比离散情况,简单地定义给定的条件概率密度为:
假设分母不等于 0。
3.5 贝叶斯定理
当试图推导一个变量给定另一个变量的条件概率表达式时,经常出现的一个有用公式是贝叶斯定理。
对于离散随机变量和:
对于连续随机变量和:
3.6 独立性
如果对于和的所有值,
对于离散随机变量, 对于任意, , 对于离散随机变量, 当对于任意且。 对于连续随机变量, 对于连续随机变量, ,当对于任意。
非正式地说,如果“知道”一个变量的值永远不会对另一个变量的条件概率分布有任何影响,那么两个随机变量和是独立的,也就是说,你只要知道和就知道关于这对变量的所有信息。以下引理将这一观察形式化:
引理 3.1
如果和是独立的,那么对于任何,我们有:
利用上述引理,我们可以证明如果与无关,那么的任何函数都与的任何函数无关。
3.7 期望和协方差
假设我们有两个离散的随机变量,并且是这两个随机变量的函数。那么的期望值以如下方式定义:
对于连续随机变量,,类似的表达式是:
我们可以用期望的概念来研究两个随机变量之间的关系。特别地,两个随机变量的协方差定义为:
使用类似于方差的推导,我们可以将它重写为:
在这里,说明两种协方差形式相等的关键步骤是第三个等号,在这里我们使用了这样一个事实,即和实际上是常数,可以被提出来。当时,我们说和不相关。
性质:
(期望线性) 如果和相互独立, 那么 如果和相互独立, 那么
4. 多个随机变量
上一节介绍的概念和想法可以推广到两个以上的随机变量。特别是,假设我们有个连续随机变量,。在本节中,为了表示简单,我们只关注连续的情况,对离散随机变量的推广工作类似。
4.1 基本性质
我们可以定义的联合累积分布函数、联合概率密度函数,以及给定时的边缘概率密度函数为:
为了计算事件的概率,我们有:
链式法则:
从多个随机变量的条件概率的定义中,可以看出:
独立性:对于多个事件,,我们说 是相互独立的,当对于任何子集,我们有:
同样,我们说随机变量是独立的,如果:
这里,相互独立性的定义只是两个随机变量独立性到多个随机变量的自然推广。
独立随机变量经常出现在机器学习算法中,其中我们假设属于训练集的训练样本代表来自某个未知概率分布的独立样本。为了明确独立性的重要性,考虑一个“坏的”训练集,我们首先从某个未知分布中抽取一个训练样本,然后将完全相同的训练样本的个副本添加到训练集中。在这种情况下,我们有:
尽管训练集的大小为,但这些例子并不独立!虽然这里描述的过程显然不是为机器学习算法建立训练集的明智方法,但是事实证明,在实践中,样本的不独立性确实经常出现,并且它具有减小训练集的“有效大小”的效果。
4.2 随机向量
假设我们有n个随机变量。当把所有这些随机变量放在一起工作时,我们经常会发现把它们放在一个向量中是很方便的...我们称结果向量为随机向量(更正式地说,随机向量是从到的映射)。应该清楚的是,随机向量只是处理个随机变量的一种替代符号,因此联合概率密度函数和综合密度函数的概念也将适用于随机向量。
期望:
考虑中的任意函数。这个函数的期望值 被定义为
其中,是从到的个连续积分。如果是从到的函数,那么的期望值是输出向量的元素期望值,即,如果是:
那么,
协方差矩阵:对于给定的随机向量,其协方差矩阵是平方矩阵,其输入由给出。从协方差的定义来看,我们有:
其中矩阵期望以明显的方式定义。协方差矩阵有许多有用的属性:
;也就是说,是正半定的。 ;也就是说,是对称的。
4.3 多元高斯分布
随机向量上概率分布的一个特别重要的例子叫做多元高斯或多元正态分布。随机向量被认为具有多元正态(或高斯)分布,当其具有均值和协方差矩阵(其中指对称正定矩阵的空间)
我们把它写成。请注意,在的情况下,它降维成普通正态分布,其中均值参数为,方差为。
一般来说,高斯随机变量在机器学习和统计中非常有用,主要有两个原因:
首先,在统计算法中对“噪声”建模时,它们非常常见。通常,噪声可以被认为是影响测量过程的大量小的独立随机扰动的累积;根据中心极限定理,独立随机变量的总和将趋向于“看起来像高斯”。
其次,高斯随机变量便于许多分析操作,因为实际中出现的许多涉及高斯分布的积分都有简单的封闭形式解。我们将在本课程稍后遇到这种情况。
5. 其他资源
一本关于CS229所需概率水平的好教科书是谢尔顿·罗斯的《概率第一课》(A First Course on Probability by Sheldon Ross)。
参考资料
原始文件下载: http://cs229.stanford.edu/summer2019/cs229-prob.pdf
[2]石振宇: https://github.com/szy2120109
[3]黄海广: https://github.com/fengdu78
往期精彩回顾 本站qq群955171419,加入微信群请扫码:



