
MySQL面试:left join我要怎优化?
共 1843字,需浏览 4分钟
· 2022-01-01
在实际开发中,相信大多数人都会用到join进行连表查询,但是有些人发现,用join好像效率很低,而且驱动表不同,执行时间也不同。那么join到底是如何执行的呢?
这里有两个表t1,t2
explain select * from t1 left join t2 on t1.a=t2.a;
复制代码上面语句使用left join,说明t1是驱动表(left join谁在左谁是驱动表),t2是被驱动表,执行一下

可以看到,驱动表是的type是ALL,所以是全表扫描,被驱动表有a索引,left join的时候,用到了a这个索引,因此这个语句执行流程是:
从表t1中读入一行数据
从数据行中,取出a字段到表t2里去查找
取出表t2中满足条件的行,跟t1的数据组成一行,作为结果集的一部分
重复上面操作,直到t1的数据取完为止
这个过程是先遍历表t1,然后根据表t1中取出的每行数据中的a值,去表t2中查询满足条件的记录。这里我们成为"Index Nested-Loop Join",简称NLJ。

通过上面所述,如果我们选择驱动表的话,就要选择小表来做驱动表。否则大表做驱动表是要查询所有的,效率会低很多。当然,前提是"可以使用被驱动表的索引"
这里我们把sql语句改一下:
explain select * from t1 left join t2 on t1.a=t2.b;
复制代码t2表的b字段是无索引的
 结果就是两个表都要全表扫描,这里我们看到,Extra显示的是(Using where; Using join buffer (Block Nested Loop))
结果就是两个表都要全表扫描,这里我们看到,Extra显示的是(Using where; Using join buffer (Block Nested Loop))
这个其实是MySQL对join不走索引全表扫描做了一个优化,简称BNL。
BNL流程:
把表t1的数据读入线程内存join_buffer中,这里我们是把整个表t1放入内存中。
扫描表t2,把表t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
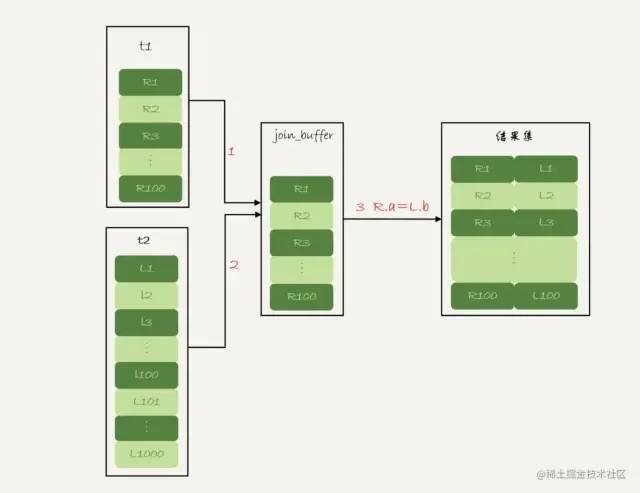
这里,我们两个表都是做的全表扫描,所以不管是哪个表做驱动表都是执行消耗都是一样的。
如果一个表的数据太大了,根本装不下所有数据的话,就采用分段放。也可以修改join_buffer_size。
针对于有索引的被驱动表,MySQL5.6版本开始增加了Batched Key Access(BKA)的新特性
对于多表join语句,当MySQL使用索引访问第一个join表的时候,使用join_buffer来收集第一个操作对象生成的相关列的值。BKA构建好key之后,通过MRR接口提交给引擎做查询。
BKA步骤:
将驱动表相关的列放入join_buffer中。
批量的将Key(索引键值)发送到MRR接口。
MRR通过收到的key,根据其对应的ROWID进行排序,然后再进行数据的读取操作。
这里来看,BKA和BNL其实是差不多的,主要区别就是BKA是针对被驱动表是走索引的情况下,索引是非主键索引的时候,按照索引字段进行排序,因此减少了随机IO,提高性能。
MRR
MySQL5.6版本开始支持的Multi-Range Read(MRR)优化。MRR目的是为了减少磁盘的随机访问,并且将随机访问转换为较为顺序的数据访问,MRR可适用于range,ref,eq_ref类型的查询
MRR优化有以下几个好处:
MRR使数据访问变的较为顺序。在查询辅助索引时,首先根据得到的查询结果,按照主键进行排序,并按照主键排序的顺序进行书签查找
减少缓冲池中页被替换的次数
批量处理对键值的查询操作
MRR的设计思路是因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。
MRR 能够提升性能的核心在于,这条查询语句在索引 a 上做的是一个范围查询(也就是说,这是一个多值查询),可以得到足够多的主键 id。这样通过排序以后,再去主键索引查数据,才能体现出“顺序性”的优势。
作者:Five在努力
链接:https://juejin.cn/post/6997788615732363301
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。