
使用OpenCV实现道路车辆计数
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
今天,我们将一起探讨如何基于计算机视觉实现道路交通计数。
在本教程中,我们将仅使用Python和OpenCV,并借助背景减除算法非常简单地进行运动检测。
我们将从以下四个方面进行介绍:
1. 用于物体检测的背景减法算法主要思想。
2. OpenCV图像过滤器。
3. 利用轮廓检测物体。
4. 建立进一步数据处理的结构。
背景扣除算法
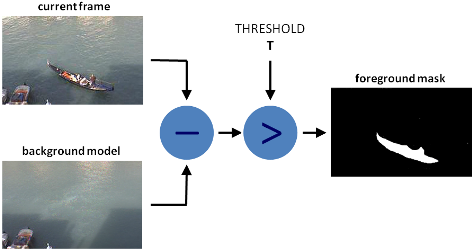
有许多不同的背景扣除算法,但是它们的主要思想都很简单。
假设有一个房间的视频,在某些帧上没有人和宠物,那么此时的视频基本为静态的,我们将其称为背景(background_layer)。因此要获取在视频上移动的对象,我们只需要:用当前帧减去背景即可。
由于光照变化,人为移动物体,或者始终存在移动的人和宠物,我们将无法获得静态帧。在这种情况下,我们从视频中选出一些图像帧,如果绝大多数图像帧中都具有某个相同的像素点,则此将像素作为background_layer中的一部分。
我们将使用MOG算法进行背景扣除

原始帧
代码如下所示:
import osimport loggingimport logging.handlersimport randomimport numpy as npimport skvideo.ioimport cv2import matplotlib.pyplot as pltimport utils# without this some strange errors happencv2.ocl.setUseOpenCL(False)random.seed(123)# ============================================================================IMAGE_DIR = "./out"VIDEO_SOURCE = "input.mp4"SHAPE = (720, 1280) # HxW# ============================================================================def train_bg_subtractor(inst, cap, num=500):'''BG substractor need process some amount of frames to start giving result'''print ('Training BG Subtractor...')i = 0for frame in cap:inst.apply(frame, None, 0.001)i += 1if i >= num:return capdef main():log = logging.getLogger("main")# creting MOG bg subtractor with 500 frames in cache# and shadow detctionbg_subtractor = cv2.createBackgroundSubtractorMOG2(history=500, detectShadows=True)# Set up image source# You can use also CV2, for some reason it not working for mecap = skvideo.io.vreader(VIDEO_SOURCE)# skipping 500 frames to train bg subtractortrain_bg_subtractor(bg_subtractor, cap, num=500)frame_number = -1for frame in cap:if not frame.any():log.error("Frame capture failed, stopping...")breakframe_number += 1utils.save_frame(frame, "./out/frame_%04d.png" % frame_number)fg_mask = bg_subtractor.apply(frame, None, 0.001)utils.save_frame(frame, "./out/fg_mask_%04d.png" % frame_number)# ============================================================================if __name__ == "__main__":log = utils.init_logging()if not os.path.exists(IMAGE_DIR):log.debug("Creating image directory `%s`...", IMAGE_DIR)os.makedirs(IMAGE_DIR)main()
处理后得到下面的前景图像
去除背景后的前景图像
我们可以看出前景图像上有一些噪音,可以通过标准滤波技术可以将其消除。
滤波
针对我们现在的情况,我们将需要以下滤波函数:Threshold、Erode、Dilate、Opening、Closing。
首先,我们使用“Closing”来移除区域中的间隙,然后使用“Opening”来移除个别独立的像素点,然后使用“Dilate”进行扩张以使对象变粗。代码如下:
def filter_mask(img):kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (2, 2))# Fill any small holesclosing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)# Remove noiseopening = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel)# Dilate to merge adjacent blobsdilation = cv2.dilate(opening, kernel, iterations=2)# thresholdth = dilation[dilation < 240] = 0return th
处理后的前景如下:

利用轮廓进行物体检测
我们将使用cv2.findContours函数对轮廓进行检测。我们在使用的时候可以选择的参数为:
cv2.CV_RETR_EXTERNAL------仅获取外部轮廓。
cv2.CV_CHAIN_APPROX_TC89_L1------使用Teh-Chin链逼近算法(更快)
代码如下:
def get_centroid(x, y, w, h):x1 = int(w / 2)y1 = int(h / 2)cx = x + x1cy = y + y1return (cx, cy)def detect_vehicles(fg_mask, min_contour_width=35, min_contour_height=35):matches = []# finding external contourscontours, hierarchy = cv2.findContours(cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_L1)# filtering by with, heightfor (i, contour) in enumerate(contours):y, w, h) = cv2.boundingRect(contour)contour_valid = (w >= min_contour_width) and (h >= min_contour_height)if not contour_valid:continue# getting center of the bounding boxcentroid = get_centroid(x, y, w, h)y, w, h), centroid))return matches
建立数据处理框架
我们都知道在ML和CV中,没有一个算法可以处理所有问题。即使存在这种算法,我们也不会使用它,因为它很难大规模有效。例如几年前Netflix公司用300万美元的奖金悬赏最佳电影推荐算法。有一个团队完成这个任务,但是他们的推荐算法无法大规模运行,因此其实对公司毫无用处。但是,Netflix公司仍奖励了他们100万美元。
接下来我们来建立解决当前问题的框架,这样可以使数据的处理更加方便
class PipelineRunner(object):'''Very simple pipline.Just run passed processors in order with passing context from one toanother.You can also set log level for processors.'''def __init__(self, pipeline=None, log_level=logging.DEBUG):self.pipeline = pipeline or []self.context = {}self.log = logging.getLogger(self.__class__.__name__)self.log.setLevel(log_level)self.log_level = log_levelself.set_log_level()def set_context(self, data):self.context = datadef add(self, processor):if not isinstance(processor, PipelineProcessor):raise Exception('Processor should be an isinstance of PipelineProcessor.')processor.log.setLevel(self.log_level)self.pipeline.append(processor)def remove(self, name):for i, p in enumerate(self.pipeline):if p.__class__.__name__ == name:del self.pipeline[i]return Truereturn Falsedef set_log_level(self):for p in self.pipeline:p.log.setLevel(self.log_level)def run(self):for p in self.pipeline:self.context = p(self.context)self.log.debug("Frame #%d processed.", self.context['frame_number'])return self.contextclass PipelineProcessor(object):'''Base class for processors.'''def __init__(self):self.log = logging.getLogger(self.__class__.__name__)
首先我们获取一张处理器运行顺序的列表,让每个处理器完成一部分工作,在案顺序完成执行以获得最终结果。
我们首先创建轮廓检测处理器。轮廓检测处理器只需将前面的背景扣除,滤波和轮廓检测部分合并在一起即可,代码如下所示:
class ContourDetection(PipelineProcessor):'''Detecting moving objects.Purpose of this processor is to subtrac background, get moving objectsand detect them with a cv2.findContours method, and then filter off-bywidth and height.bg_subtractor - background subtractor isinstance.min_contour_width - min bounding rectangle width.min_contour_height - min bounding rectangle height.save_image - if True will save detected objects mask to file.image_dir - where to save images(must exist).'''def __init__(self, bg_subtractor, min_contour_width=35, min_contour_height=35, save_image=False, image_dir='images'):super(ContourDetection, self).__init__()self.bg_subtractor = bg_subtractorself.min_contour_width = min_contour_widthself.min_contour_height = min_contour_heightself.save_image = save_imageself.image_dir = image_dirdef filter_mask(self, img, a=None):'''This filters are hand-picked just based on visual tests'''kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (2, 2))# Fill any small holesclosing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)# Remove noiseopening = cv2.morphologyEx(closing, cv2.MORPH_OPEN, kernel)# Dilate to merge adjacent blobsdilation = cv2.dilate(opening, kernel, iterations=2)return dilationdef detect_vehicles(self, fg_mask, context):matches = []# finding external contoursim2, contours, hierarchy = cv2.findContours(fg_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_TC89_L1)for (i, contour) in enumerate(contours):(x, y, w, h) = cv2.boundingRect(contour)contour_valid = (w >= self.min_contour_width) and (h >= self.min_contour_height)if not contour_valid:continuecentroid = utils.get_centroid(x, y, w, h)matches.append(((x, y, w, h), centroid))return matchesdef __call__(self, context):frame = context['frame'].copy()frame_number = context['frame_number']fg_mask = self.bg_subtractor.apply(frame, None, 0.001)# just thresholding valuesfg_mask[fg_mask < 240] = 0fg_mask = self.filter_mask(fg_mask, frame_number)if self.save_image:utils.save_frame(fg_mask, self.image_dir +"/mask_%04d.png" % frame_number, flip=False)context['objects'] = self.detect_vehicles(fg_mask, context)context['fg_mask'] = fg_maskreturn contex
现在,让我们创建一个处理器,该处理器将找出不同的帧上检测到的相同对象,创建路径,并对到达出口区域的车辆进行计数。代码如下所示:
'''Counting vehicles that entered in exit zone.Purpose of this class based on detected object and local cache createobjects pathes and count that entered in exit zone defined by exit masks.exit_masks - list of the exit masks.path_size - max number of points in a path.max_dst - max distance between two points.'''def __init__(self, exit_masks=[], path_size=10, max_dst=30, x_weight=1.0, y_weight=1.0):super(VehicleCounter, self).__init__()self.exit_masks = exit_masksself.vehicle_count = 0self.path_size = path_sizeself.pathes = []self.max_dst = max_dstself.x_weight = x_weightself.y_weight = y_weightdef check_exit(self, point):for exit_mask in self.exit_masks:try:if exit_mask[point[1]][point[0]] == 255:return Trueexcept:return Truereturn Falsedef __call__(self, context):objects = context['objects']context['exit_masks'] = self.exit_maskscontext['pathes'] = self.pathescontext['vehicle_count'] = self.vehicle_countif not objects:return contextpoints = np.array(objects)[:, 0:2]points = points.tolist()# add new points if pathes is emptyif not self.pathes:for match in points:self.pathes.append([match])else:# link new points with old pathes based on minimum distance between# pointsnew_pathes = []for path in self.pathes:_min = 999999_match = Nonefor p in points:if len(path) == 1:# distance from last point to currentd = utils.distance(p[0], path[-1][0])else:# based on 2 prev points predict next point and calculate# distance from predicted next point to currentxn = 2 * path[-1][0][0] - path[-2][0][0]yn = 2 * path[-1][0][1] - path[-2][0][1]d = utils.distance(p[0], (xn, yn),x_weight=self.x_weight,y_weight=self.y_weight)if d < _min:_min = d_match = pif _match and _min <= self.max_dst:points.remove(_match)path.append(_match)new_pathes.append(path)# do not drop path if current frame has no matchesif _match is None:new_pathes.append(path)self.pathes = new_pathes# add new pathesif len(points):for p in points:# do not add points that already should be countedif self.check_exit(p[1]):continueself.pathes.append([p])# save only last N points in pathfor i, _ in enumerate(self.pathes):self.pathes[i] = self.pathes[i][self.path_size * -1:]# count vehicles and drop counted pathes:new_pathes = []for i, path in enumerate(self.pathes):d = path[-2:]if (# need at list two points to countlen(d) >= 2 and# prev point not in exit zonenot self.check_exit(d[0][1]) and# current point in exit zoneself.check_exit(d[1][1]) and# path len is bigger then minself.path_size <= len(path)):self.vehicle_count += 1else:# prevent linking with path that already in exit zoneadd = Truefor p in path:if self.check_exit(p[1]):add = Falsebreakif add:new_pathes.append(path)self.pathes = new_pathescontext['pathes'] = self.pathescontext['objects'] = objectscontext['vehicle_count'] = self.vehicle_countself.log.debug('#VEHICLES FOUND: %s' % self.vehicle_count)return context
上面的代码有点复杂,因此让我们一个部分一个部分的介绍一下。
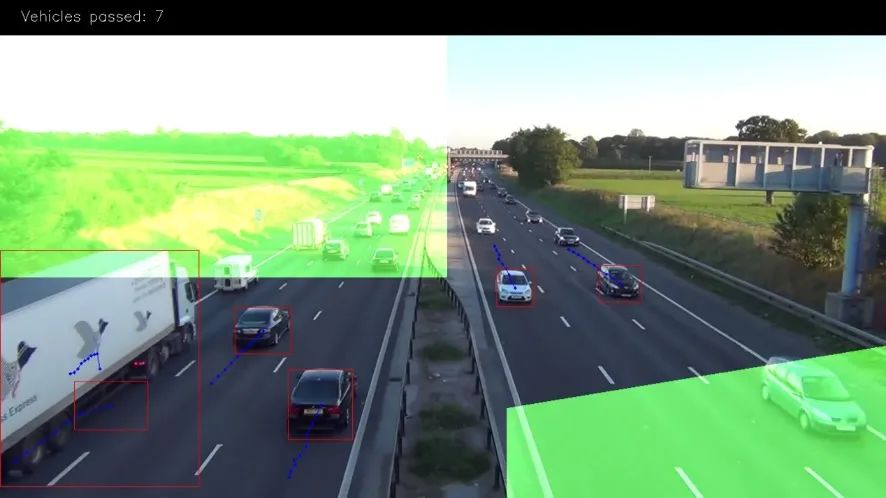
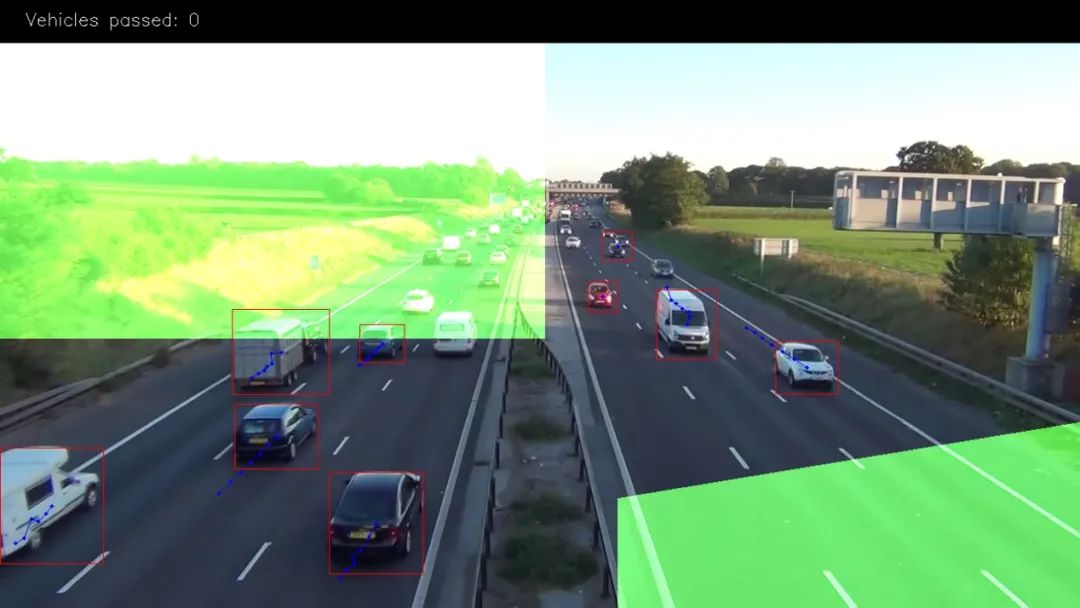
上面的图像中绿色的部分是出口区域。我们在这里对车辆进行计数,只有当车辆移动的长度超过3个点我们才进行计算
我们使用掩码来解决这个问题,因为它比使用矢量算法有效且简单得多。只需使用“二进制和”即可选出车辆区域中点。设置方式如下:
EXIT_PTS = np.array([[], [732, 590], [1280, 500], [1280, 720]],[], [645, 400], [645, 0], [0, 0]]])base = np.zeros(SHAPE + (3,), dtype='uint8')exit_mask = cv2.fillPoly(base, EXIT_PTS, (255, 255, 255))[:, :, 0]
现在我们将检测到的点链接起来。
对于第一帧图像,我们将所有点均添加为新路径。
接下来,如果len(path)== 1,我们在新检测到的对象中找到与每条路径最后一点距离最近的对象。
如果len(path)> 1,则使用路径中的最后两个点,即在同一条线上预测新点,并找到该点与当前点之间的最小距离。
具有最小距离的点将添加到当前路径的末端并从列表中删除。如果在此之后还剩下一些点,我们会将其添加为新路径。这个过程中我们还会限制路径中的点数。
new_pathes = []for path in self.pathes:_min = 999999_match = Nonefor p in points:if len(path) == 1:# distance from last point to currentd = utils.distance(p[0], path[-1][0])else:# based on 2 prev points predict next point and calculate# distance from predicted next point to currentxn = 2 * path[-1][0][0] - path[-2][0][0]yn = 2 * path[-1][0][1] - path[-2][0][1]d = utils.distance(p[0], (xn, yn),x_weight=self.x_weight,y_weight=self.y_weight)if d < _min:_min = d_match = pif _match and _min <= self.max_dst:points.remove(_match)path.append(_match)new_pathes.append(path)# do not drop path if current frame has no matchesif _match is None:new_pathes.append(path)self.pathes = new_pathes# add new pathesif len(points):for p in points:# do not add points that already should be countedif self.check_exit(p[1]):continueself.pathes.append([p])# save only last N points in pathfor i, _ in enumerate(self.pathes):self.pathes[i] = self.pathes[i][self.path_size * -1:]
现在,我们将尝试计算进入出口区域的车辆。为此,我们需获取路径中的最后2个点,并检查len(path)是否应大于限制。
# count vehicles and drop counted pathes:new_pathes = []for i, path in enumerate(self.pathes):d = path[-2:]if (# need at list two points to countlen(d) >= 2 and# prev point not in exit zonenot self.check_exit(d[0][1]) and# current point in exit zoneself.check_exit(d[1][1]) and# path len is bigger then minself.path_size <= len(path)):self.vehicle_count += 1else:# prevent linking with path that already in exit zoneadd = Truefor p in path:if self.check_exit(p[1]):add = Falsebreakif add:new_pathes.append(path)self.pathes = new_pathescontext['pathes'] = self.pathescontext['objects'] = objectscontext['vehicle_count'] = self.vehicle_countself.log.debug('#VEHICLES FOUND: %s' % self.vehicle_count)return context
最后两个处理器是CSV编写器,用于创建报告CSV文件,以及用于调试和精美图片的可视化。
class CsvWriter(PipelineProcessor):def __init__(self, path, name, start_time=0, fps=15):super(CsvWriter, self).__init__()self.fp = open(os.path.join(path, name), 'w')self.writer = csv.DictWriter(self.fp, fieldnames=['time', 'vehicles'])self.writer.writeheader()self.start_time = start_timeself.fps = fpsself.path = pathself.name = nameself.prev = Nonedef __call__(self, context):frame_number = context['frame_number']count = _count = context['vehicle_count']if self.prev:_count = count - self.prevtime = ((self.start_time + int(frame_number / self.fps)) * 100+ int(100.0 / self.fps) * (frame_number % self.fps))self.writer.writerow({'time': time, 'vehicles': _count})self.prev = countreturn contextclass Visualizer(PipelineProcessor):def __init__(self, save_image=True, image_dir='images'):super(Visualizer, self).__init__()self.save_image = save_imageself.image_dir = image_dirdef check_exit(self, point, exit_masks=[]):for exit_mask in exit_masks:if exit_mask[point[1]][point[0]] == 255:return Truereturn Falsedef draw_pathes(self, img, pathes):if not img.any():returnfor i, path in enumerate(pathes):path = np.array(path)[:, 1].tolist()for point in path:cv2.circle(img, point, 2, CAR_COLOURS[0], -1)cv2.polylines(img, [np.int32(path)], False, CAR_COLOURS[0], 1)return imgdef draw_boxes(self, img, pathes, exit_masks=[]):for (i, match) in enumerate(pathes):contour, centroid = match[-1][:2]if self.check_exit(centroid, exit_masks):continuex, y, w, h = contourcv2.rectangle(img, (x, y), (x + w - 1, y + h - 1),BOUNDING_BOX_COLOUR, 1)cv2.circle(img, centroid, 2, CENTROID_COLOUR, -1)return imgdef draw_ui(self, img, vehicle_count, exit_masks=[]):# this just add green mask with opacity to the imagefor exit_mask in exit_masks:_img = np.zeros(img.shape, img.dtype)_img[:, :] = EXIT_COLORmask = cv2.bitwise_and(_img, _img, mask=exit_mask)cv2.addWeighted(mask, 1, img, 1, 0, img)# drawing top block with countscv2.rectangle(img, (0, 0), (img.shape[1], 50), (0, 0, 0), cv2.FILLED)cv2.putText(img, ("Vehicles passed: {total} ".format(total=vehicle_count)), (30, 30),cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255, 255, 255), 1)return imgdef __call__(self, context):frame = context['frame'].copy()frame_number = context['frame_number']pathes = context['pathes']exit_masks = context['exit_masks']vehicle_count = context['vehicle_count']frame = self.draw_ui(frame, vehicle_count, exit_masks)frame = self.draw_pathes(frame, pathes)frame = self.draw_boxes(frame, pathes, exit_masks)utils.save_frame(frame, self.image_dir +"/processed_%04d.png" % frame_number)return context
结论
正如我们看到的那样,它并不像许多人想象的那么难。但是,如果小伙伴运行脚本,小伙伴会发现此解决方案并不理想,存在前景对象存在重叠的问题,并且它也没有按类型对车辆进行分类。但是,当相机有较好位置,例如位于道路正上方时,该算法具有很好的准确性。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~