
Catboost算法原理解析及代码实现
前言
今天博主来介绍一个超级简单并且又极其实用的boosting算法包Catboost,据开发者所说这一boosting算法是超越Lightgbm和XGBoost的又一个神器。
catboost 简介
在博主看来catboost有一下三个的优点:
它自动采用特殊的方式处理类别型特征(categorical features)。首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征(numerical features)。这也是我在这里介绍这个算法最大的motivtion,有了catboost,再也不用手动处理类别型特征了。
catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
catboost的基模型采用的是对称树,同时计算leaf-value方式和传统的boosting算法也不一样,传统的boosting算法计算的是平均数,而catboost在这方面做了优化采用了其他的算法,这些改进都能防止模型过拟合。
catboost 实战
这里博主采用的是之前参加一个CTR点击率预估的数据集,首先通过pandas读入数据。
from catboost import CatBoostClassifier
import pandas as pd
from sklearn.model_selection import train_test_split
import numpy as np
data = pd.read_csv("ctr_train.txt", delimiter="\t")
del data["user_tags"]
data = data.fillna(0)
X_train, X_validation, y_train, y_validation = train_test_split(data.iloc[:,:-1],data.iloc[:,-1],test_size=0.3 , random_state=1234)
这里我们可以观察一下数据的特征列,这里有很多列特征比如广告的宽高,是否可以下载,是否会跳转等一些特征,而且特征的数据类型各不一样,有数值型(creative_height),布尔型(creative_is_js)等不同类型的特征。
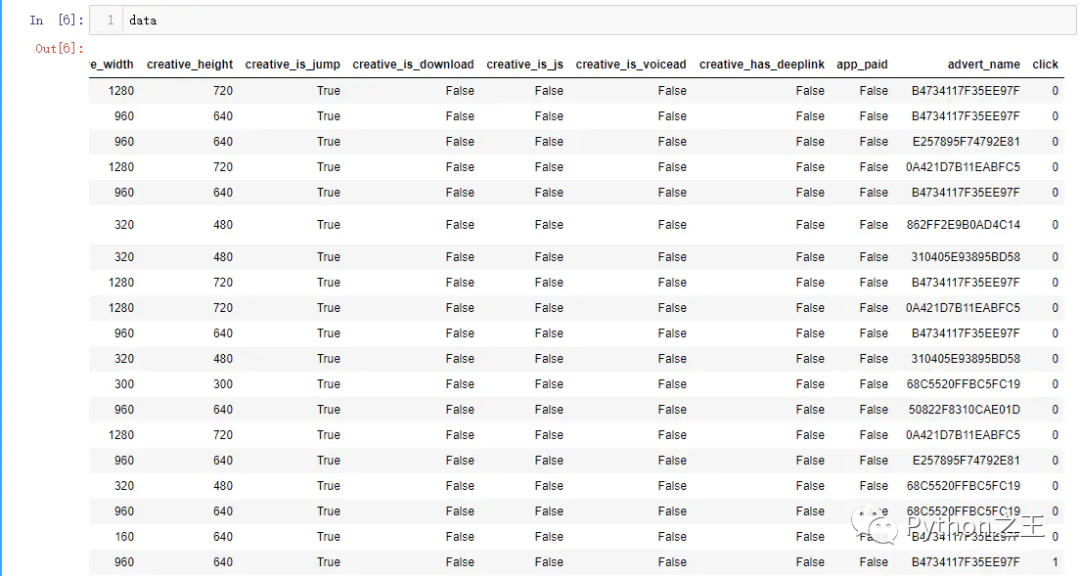
data
下图我们对所有特征做了一个统计,发现整个训练数据集一共有34列,除去标签列,整个数据集一共有33个特征,其中6个为布尔型特征,2个为浮点型特征,18个整型特征,还有8个对象型特征。
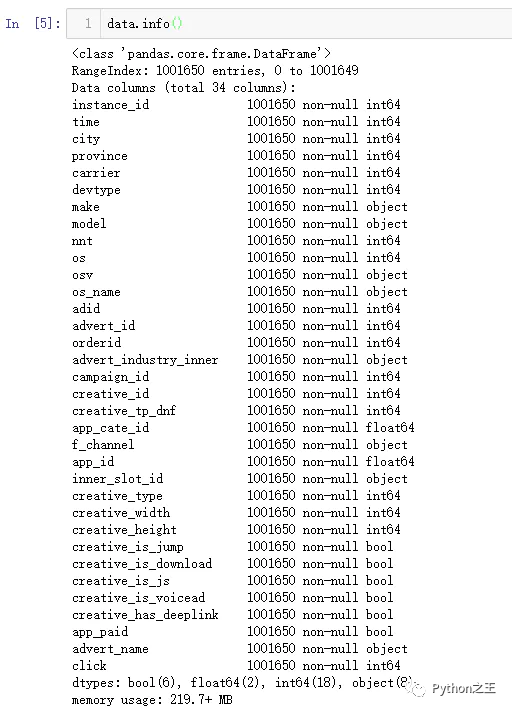
data_information
如果按照正常的算法,此时应该将非数值型特征通过各种数据预处理手段,各种编码方式转化为数值型特征。而在catboost中你根本不用费心干这些,你只需要告诉算法,哪些特征属于类别特征,它会自动帮你处理。代码如下所示:
categorical_features_indices = np.where(X_train.dtypes != np.float)[0]
model = CatBoostClassifier(iterations=100, depth=5,cat_features=categorical_features_indices,learning_rate=0.5, loss_function='Logloss',
logging_level='Verbose')
最后就是将数据喂给算法,训练走起来。
model.fit(X_train,y_train,eval_set=(X_validation, y_validation),plot=True)
将plot = ture 打开后,catboot包还提供了非常炫酷的训练可视化功能,从下图可以看到我的Logloss正在不停的下降。
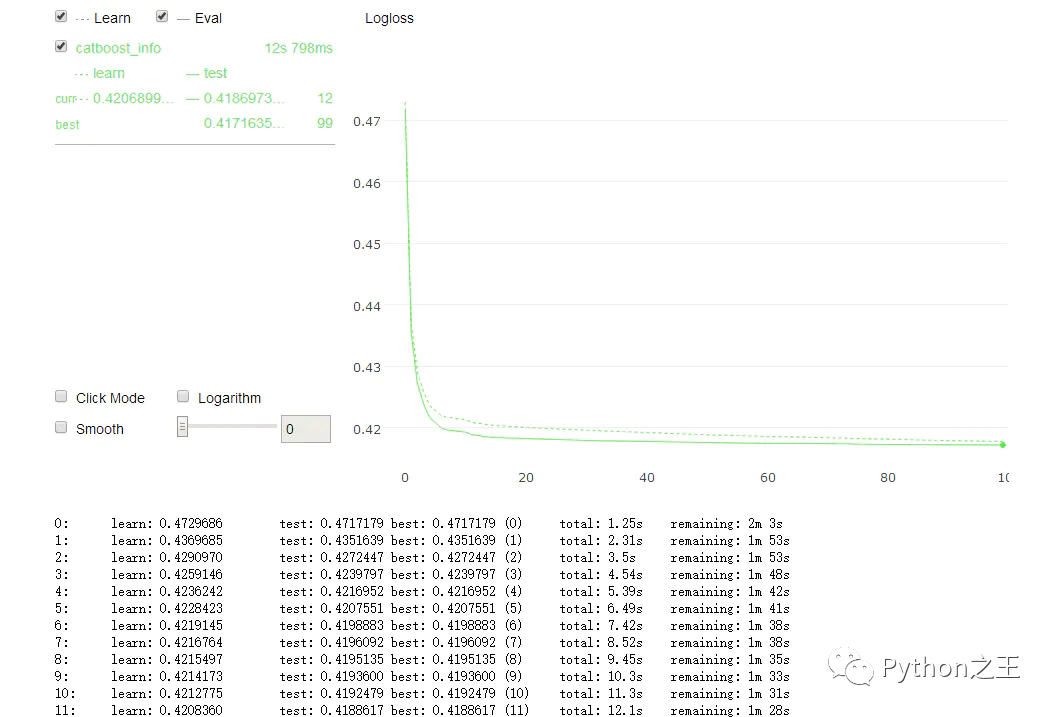
training
训练结束后,通过model.feature_importances_属性,我们可以拿到这些特征的重要程度数据,特征的重要性程度可以帮助我们分析出一些有用的信息。
import matplotlib.pyplot as plt
fea_ = model.feature_importances_
fea_name = model.feature_names_
plt.figure(figsize=(10, 10))
plt.barh(fea_name,fea_,height =0.5)
执行上方代码,我们可以拿到特征重要程度的可视化结构,从下图我们发现campaign_id是用户是否点击这个广告的最关键的影响因子。
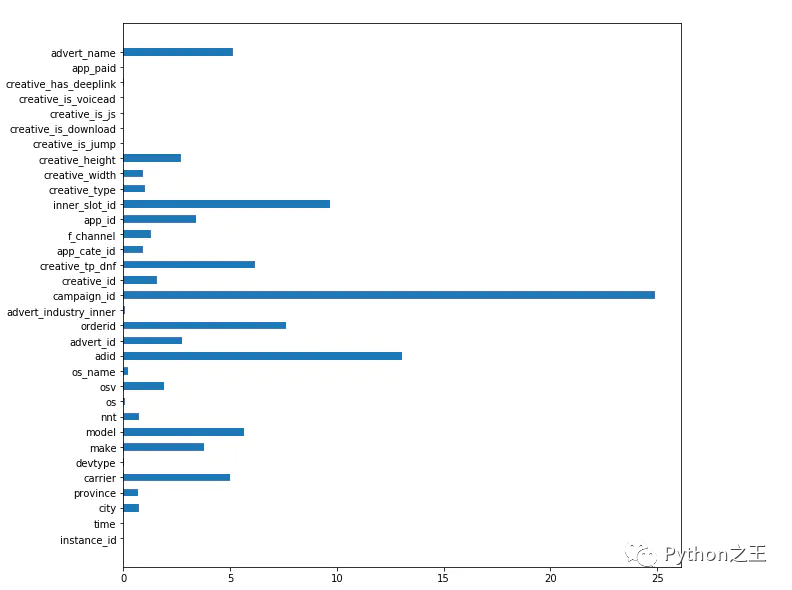
feature_importance
结语
至此整个catboot的优点和使用方法都介绍完了,是不是觉得十分简单易用,而且功能强大。深度学习,神经网络减弱了我们对特征工程的依赖,catboost也在朝着这方面努力。所以有时候碰到需要特别多的前期数据处理和特征数值化的任务时,可以尝试用一下catboost,python pip install catboost 即可安装哦。


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!