
最近,我和隐私计算干上了。


1、“数据孤岛“现象普遍存在;数据流通安全性风险高;
2、数据合规监管日趋严格;隐私泄露导致信任鸿沟;
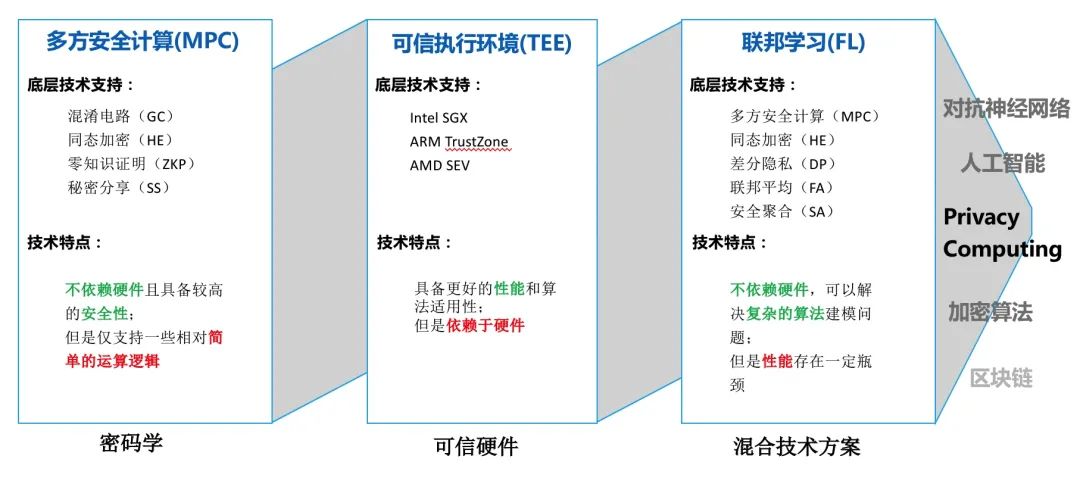
1、基于密码学的多方安全计算(MPC)
2、基于可信硬件的可信执行环境(TEE)
3、基于混合技术方案的联邦学习(FL)
想要实现去标识化和匿名化,主要的方式就是让原始的用户数据无法被识别。
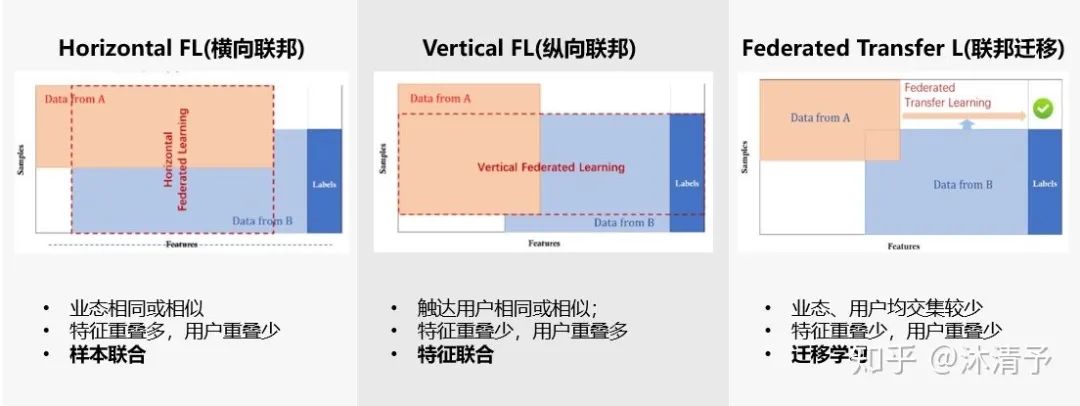
横向联邦学习的本质是样本的联合,适用于参与者间业态相同但触达客户不同,即特征重叠多,用户重叠少时的场景,比如不同地区的银行间,他们的业务相似(特征相似),但用户不同(样本不同)。主要解决样本不足的问题。
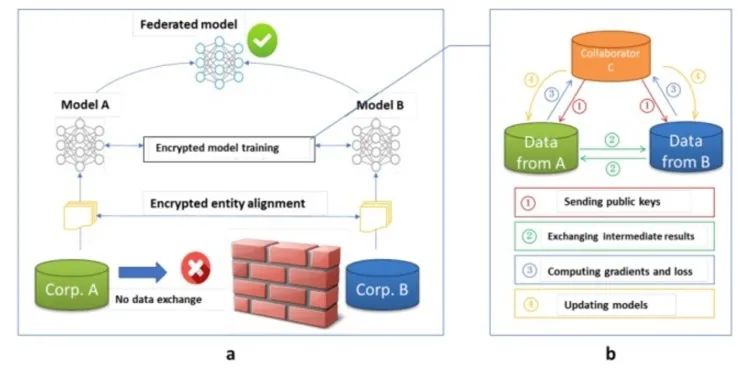
第一步:加密样本对齐。是在系统级做这件事,因此在企业感知层面不会暴露非交叉用户。第二步:对齐样本进行模型加密训练:step1:由第三方C向A和B发送公钥,用来加密需要传输的数据;step2:A和B分别计算和自己相关的特征中间结果,并加密交互,用来求得各自梯度和损失;step3:A和B分别计算各自加密后的梯度并添加掩码发送给C,同时B计算加密后的损失发送给C;step4:C解密梯度和损失后回传给A和B,A、B去除掩码并更新模型。
基于Docker-Compose:快速体验一下FATE,跑的模型和数据在单台机器就够了,部署起来比较简单。 Standalone单机部署:只是想开发算法,而开发机器性能又不高。 基于KubeFATE:对FATE的使用需求因数据集和模型变大,需要扩容,并且里面有数据需要维护一个FATE集群,则考虑使用基于KubeFATE在Kubernetes集群的部署方案。 Native的集群部署:一般是在特殊原因下才会用,如内部无法部署Kubernetes,或者需要对FATE的部署进行自己的二次开发等。为了快速验证,我们此次部署主要是采用了基于Docker-Compose和基于KubeFATE两种部署方式。部署过程中还是遇到了很多的问题的。
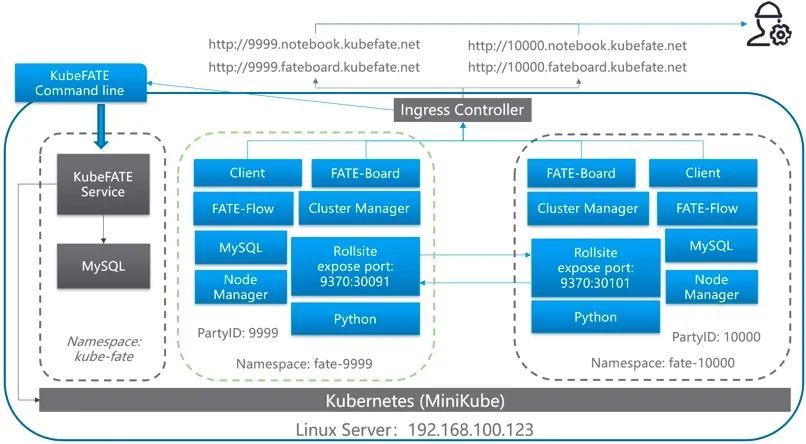
太多的细节就不在这里深入介绍了。
 技术交流群
技术交流群最近有很多人问,有没有读者交流群,想知道怎么加入。
最近我创建了一些群,大家可以加入。交流群都是免费的,只需要大家加入之后不要随便发广告,多多交流技术就好了。
目前创建了多个交流群,全国交流群、北上广杭深等各地区交流群、面试交流群、资源共享群等。
有兴趣入群的同学,可长按扫描下方二维码,一定要备注:全国 Or 城市 Or 面试 Or 资源,根据格式备注,可更快被通过且邀请进群。
往期推荐

乖乖! 学历、履历双造假,拿了抖音Offer

去大厂也就图一乐,真人上人还得是外包

火狐,恶心到我了
评论