
最近,深入研究了一下数据挖掘竞赛神器——XGBoost的算法原理和模型数据结构
导读
从事数据挖掘相关工作的人肯定都知道XGBoost算法,这个曾经闪耀于数据挖掘竞赛的一代神器,是2016年由陈天齐大神所提出来的经典算法。本质上来讲,XGBoost算作是对GBDT算法的一种优化实现,但除了在集成算法理念层面的传承,具体设计细节其实还是有很大差别的。最近深入学习了一下,并简单探索了底层设计的数据结构,不禁感慨算法之精妙!聊作总结,以资后鉴!
2016年,陈天齐受邀参加关于XGBoost的分享会
XGBoost是机器学习中的一种集成算法,按照三大集成流派来划分,属于Boosting流派。Boosting流派也是集成算法中最为活跃和强大的流派,除了XGBoost之外,前有Adaboost和GBDT,后有LightGBM和CatBoost。当然,LightGBM和CatBoost与XGBoost一般都被视作是GBDT的改良和优化实现。
XGBoost算法原理其实已经非常成熟且完备,网络上关于这方面的分享也不计其数,所以本文也不想重复前人的工作对其长篇大论,而将写作目的聚焦如下:一是从解释公式的角度分享个人关于XGBoost算法原理的理解;二是简单探究下XGBoost底层的数据结构设计。其中后者类似于前期推文《数据科学:Sklearn中的决策树,底层是如何设计和存储的?》的定位。
为了理解XGBoost的算法原理,下面主要分享与该算法相关的5个主要公式的推导过程。所有公式主要源自XGBoost官方文档(https://xgboost.readthedocs.io/en/latest),查阅相关论文也可以找得到。
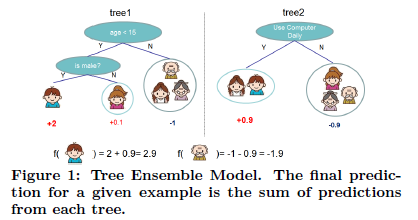
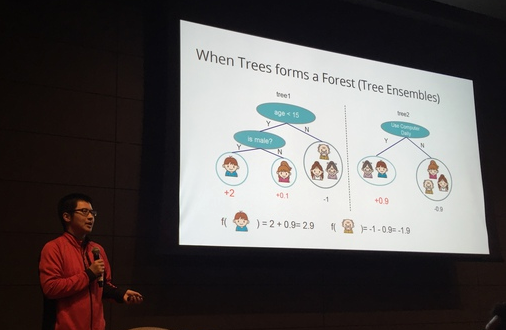
机器学习有三要素:模型、策略和算法。其中策略则包含了如何界定或评估模型的好坏,换句话说就涉及到定义损失函数。与GBDT中不断拟合残差不同,XGBoost在其基础上增加了模型的结构损失,可理解为模型学习的代价;而残差则对应经验损失,可理解为模型学习能力的差距和缺失。
在上述目标函数(目标函数是比损失函数更为high-level的术语,一般包括两部分:目标函数=损失+正则项,越小越好。除了目标函数和损失函数之外,还有一个相关的术语叫代价函数,某种意义上代价函数可近似理解为损失函数。)中,求和的第一部分定义了当前模型训练结果与真实值的差距大小,称作经验风险,具体度量方法取决于相应的损失函数定义,典型的损失函数为:回归问题对应MSE损失,分类问题对应logloss损失;求和的第二部分体现了模型的结构风险,影响模型的泛华能力。如果基学习器选择决策树,那么这里的结构风险定义为:
其中,γ和λ均为正则项系数,T为决策树中叶子节点的个数。注意,这里是叶子节点的个数,而非决策树中节点的数量(CART决策树进行CCP后剪枝时,用到的正则项是计算所有节点个数)。另外,这是一般介绍XGBoost原理时的公式,也是陈天齐最早论文中的写法,在Python的xgboost工具包中,模型初始化参数中除了与这两个参数对应的gamma和reg_lambda之外,还有reg_alpha参数,表示的一阶正则项,此时可写作:
其中gi和hi分别为一阶导和二阶导,分别写作如下:
进一步地,记y为真实值,y_hat为拟合值,则对于回归问题,适用最为常用的MSE损失,则其loss函数及相应的一阶导和二阶导分别为:
而对于分类问题,以二分类问题为例,XGBoost中默认的损失函数为logloss,相应的loss函数及对应一阶导和二阶导分别为:
上述目标公式可看做是T个一元二次表达式的求和,其中每个一元二次表达式中的变量为ωj。显然,求解形如f(x)=ax^2+bx+c的最小值问题是一个初中阶段的数学问题,进而容易得出最优的ωj及此时对应的损失函数最小取值结果为:
这里的一元二次函数一定存在最小值,因为其二次项的系数1/2(Hj+λ)一定是个正数!
如果该节点不进行分裂,即将其视作一个叶子节点,可以得到当前的最小损失取值;
对于选定的特征及阈值,将当前节点的所有样本切分为左右子树,进而可以得到左右子树对应的最小损失取值;
那么,从该节点直接作为叶子节点到将其分裂为左右两个子叶子节点是否会带来损失的降低呢?所以只需将分裂前后的损失相减即可!那么相减之后γT部分为什么变为-γ了呢?其实就是因为在分裂之前该部分的正则项对应1个叶子节点,而分裂之后则对应2个叶子节点,所以两部分的γT相减即为-γ。
以上,就是关于XGBoost中的几个核心公式推导环节的理解,相信理解了这5个公式就基本能够理解XGBoost是如何设计和实现的了。当然,XGBoost的强大和设计巧妙之处绝不止于上述算法原理,其实还有很多实用的技巧和优化,这也构成了XGBoost的scalable能力,具体可参考论文《XGBoost: A Scalable Tree Boosting System》。
第一部分主要介绍了XGBoost中的核心公式部分,下面简要分享一下XGBoost中的底层数据结构设计。之所以增加这部分工作,仍然是因为近期在做部分预研工作的需要,所以重点探究了一下XGBoost中底层是如何存储所有基学习器的,也就是各个决策树的训练结果。
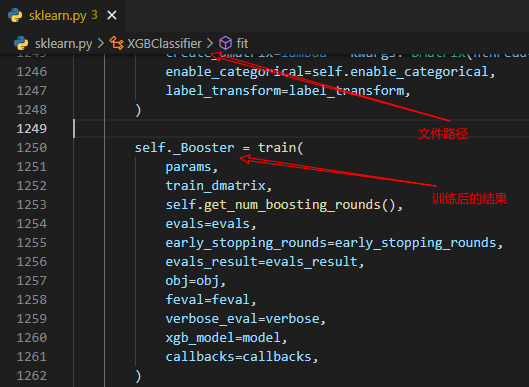
也就是说,XGBClassifer模型训练后的结果应该是保存在_Booster属性中。
当然,上述查看的xgboost提供的sklearn类型接口,在其原生训练方法中,实际上是调用xgboost.train函数来实现的模型训练,此时无论是回归任务还是分类任务,都是调用的这个函数,只是通过目标函数的不同来区分不同的任务类型而已。
from sklearn.datasets import load_irisfrom xgboost import XGBClassifierX, y = load_iris(return_X_y=True)# 原生鸢尾花数据集是三分类,对其进行采用为二分类X = X[y<2]y = y[y<2]xgb = XGBClassifier(use_label_encoder=False)xgb.fit(X, y, eval_metric='logloss')

实际上,这个_Booster属性是xgboost中定义的一个类,上述结果也可直接查看xgboost中关于Booster类的定义。在上述dir结果中,有几个函数值得重点关注:
save_model:用于将xgboost模型训练结果存储为文件,而且xgboost非常友好的是在1.0.0版本以后,直接支持存储为json格式,这可比pickle格式什么的方便多了,大大增强可读性

load_model:有save_model就一定有load_model,二者是互逆操作,即load_model可将save_model的json文件结果读取为一个xgboost模型
dump_model:实际上,dump也有存储的含义,例如json中定义的读写函数就是load和dump。而在xgboost中,dump_model与save_model的区别在于:dump_model的存储结果是便于人类阅读,但该过程是单向的,即dump的结果不能再load回去;
get_dump:与dump_model类似,只不过不是存储为文件,而只是返回一个字符串;
trees_to_dataframe:含义非常明了,就是将训练后的所有树信息转化为一个dataframe。
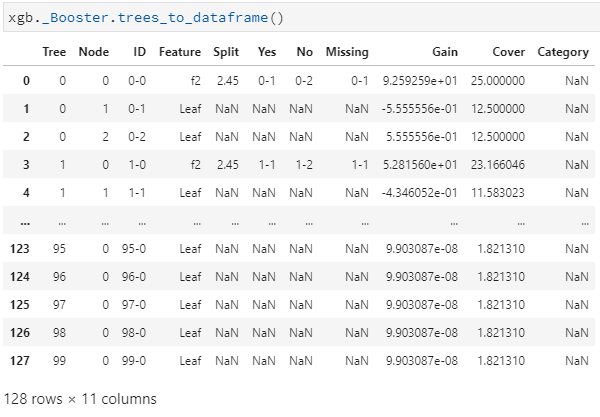
似乎从列名来推断,除了最后的Cover和Category两个字段含义不甚明了之外,其他字段的含义都非常清楚,所以也不再做过多解释。
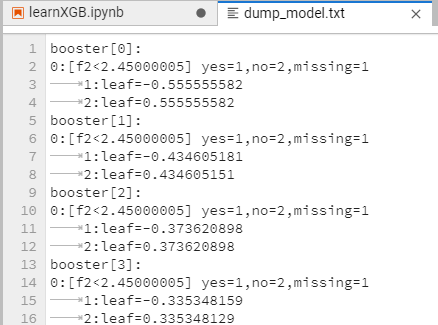
这里截取了dump_model后的txt文件的三个决策树信息,可见dump_model的结果仅保留了各决策树的分裂相关信息,以booster[0]第一个决策树为例,该决策树有三个节点,节点的缩进关系表达了子节点对应关系,内部节点标号标识了所选分裂特征及对应阈值,但叶子节点后面的数值实际上并非是其权重。
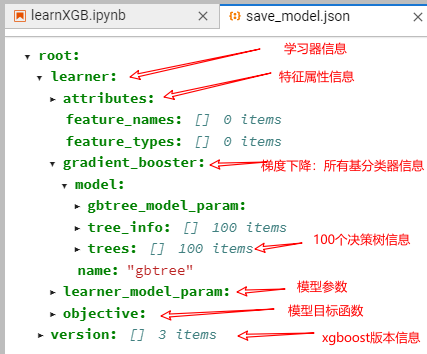

值得指出的是,经过对比left_children和right_children以及parents三个属性的取值,容易推断出xgboost中的决策树节点编号是采用的层级遍历,这与sklearn中采用的前序遍历是不同的。
以上,只是给出了xgboost中关于基学习器信息的一些简单简单探索,感兴趣的可以进一步多做尝试以及查看相应源码设计,希望能对理解xgboost的原理有所帮助。
相关阅读: