
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(十九)
极市平台
共 20226字,需浏览 41分钟
· 2021-12-01

极市导读
本文说明了只要一个模型采用元变换器 (MetaFormer) 作为通用架构,即只要模型的基本架构采用Token information mixing模块+Channel MLP模块的Meta 形式,而不论Token information mixing模块取什么样子、什么形式,模型都可以得到有希望的结果。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
专栏目录:
本文目录
38 MetaTransformer:简单到尴尬的视觉模型
(来自 Sea AI Lab,新加坡国立大学)
38.1 MetaTransformer 原理分析
38.2 MetaTransformer 代码解读
38 MetaTransformer:简单到尴尬的视觉模型
论文名称:PoolFormer: MetaFormer is Actually What You Need for Vision
38.1 MetaTransformer 原理分析:
什么才是 Transformer 及其变种成功的真正原因?Token information mixing 模块到底能简单到啥地步?它是否是模型 work 的关键?
其实 Token information mixing 模块的具体形式并不重要,Transformer 的成功来自其整体架构--MetaFormer。
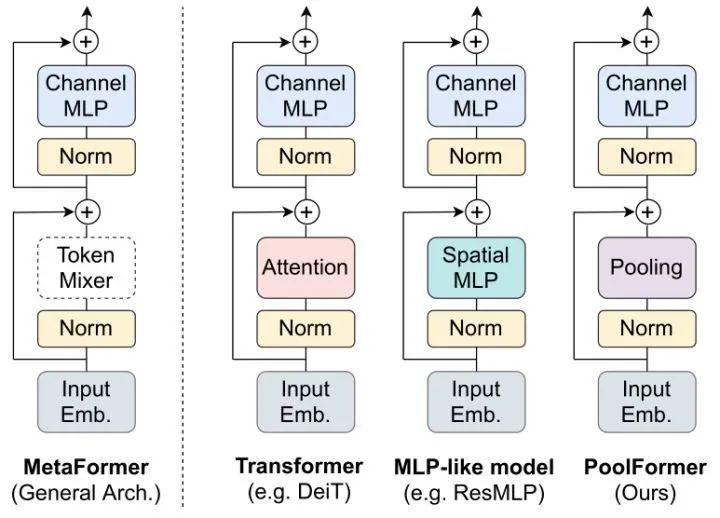

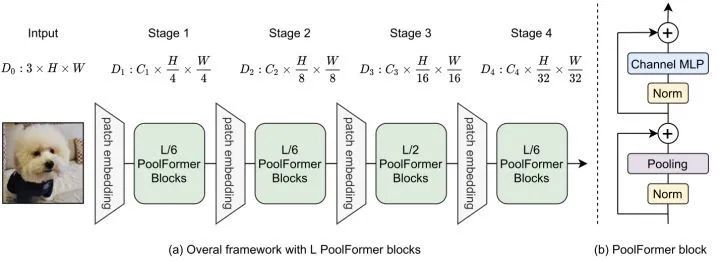
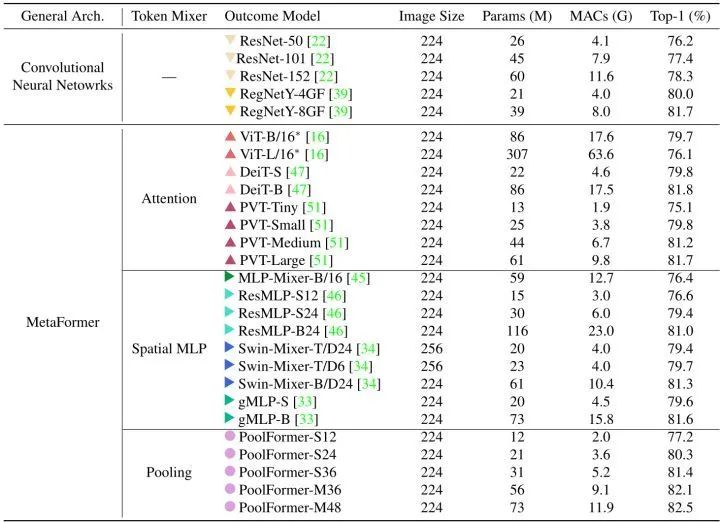
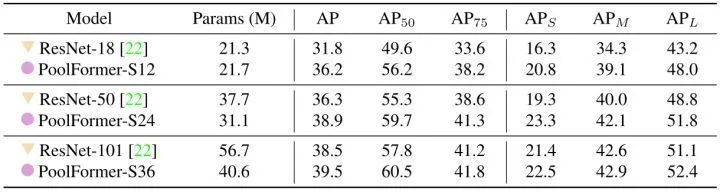
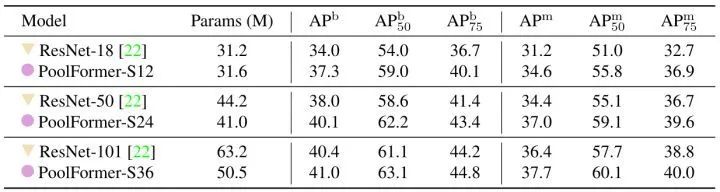
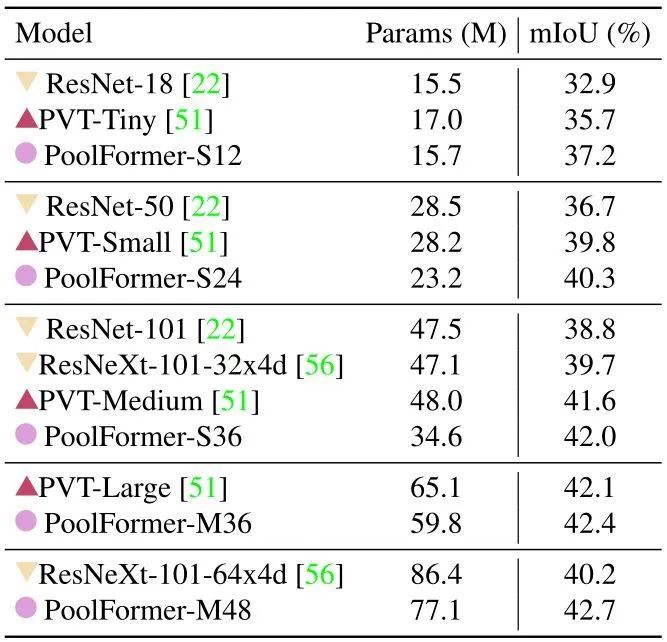
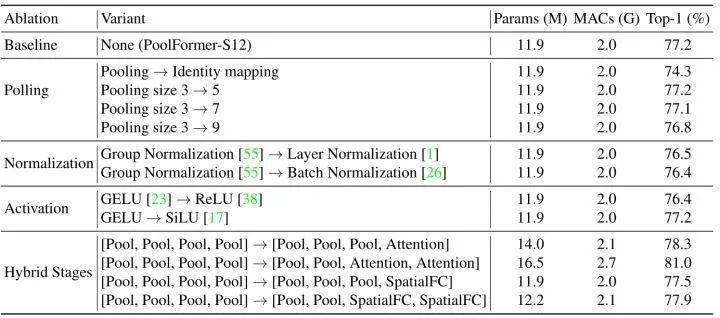
38.2 MetaTransformer 代码解读:
class PatchEmbed(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
class LayerNormChannel(nn.Module):
"""
LayerNorm only for Channel Dimension.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, eps=1e-05):
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x):
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight.unsqueeze(-1).unsqueeze(-1) * x \
+ self.bias.unsqueeze(-1).unsqueeze(-1)
return x
class GroupNorm(nn.GroupNorm):
"""
Group Normalization with 1 group.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size//2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class PoolFormerBlock(nn.Module):
"""
Implementation of one PoolFormer block.
--dim: embedding dim
--pool_size: pooling size
--mlp_ratio: mlp expansion ratio
--act_layer: activation
--norm_layer: normalization
--drop: dropout rate
--drop path: Stochastic Depth,
refer to https://arxiv.org/abs/1603.09382
--use_layer_scale, --layer_scale_init_value: LayerScale,
refer to https://arxiv.org/abs/2103.17239
"""
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Pooling(pool_size=pool_size)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
# The following two techniques are useful to train deep PoolFormers.
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def basic_blocks(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
"""
generate PoolFormer blocks for a stage
return: PoolFormer blocks
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PoolFormerBlock(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
blocks = nn.Sequential(*blocks)
return blocks
class PoolFormer(nn.Module):
"""
PoolFormer, the main class of our model
--layers: [x,x,x,x], number of blocks for the 4 stages
--embed_dims, --mlp_ratios, --pool_size: the embedding dims, mlp ratios and
pooling size for the 4 stages
--downsamples: flags to apply downsampling or not
--norm_layer, --act_layer: define the types of normalizaiotn and activation
--num_classes: number of classes for the image classification
--in_patch_size, --in_stride, --in_pad: specify the patch embedding
for the input image
--down_patch_size --down_stride --down_pad:
specify the downsample (patch embed.)
--fork_faat: whetehr output features of the 4 stages, for dense prediction
--init_cfg,--pretrained:
for mmdetection and mmsegmentation to load pretrianfed weights
"""
def __init__(self, layers, embed_dims=None,
mlp_ratios=None, downsamples=None,
pool_size=3,
norm_layer=GroupNorm, act_layer=nn.GELU,
num_classes=1000,
in_patch_size=7, in_stride=4, in_pad=2,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=False,
init_cfg=None,
pretrained=None,
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PatchEmbed(
patch_size=in_patch_size, stride=in_stride, padding=in_pad,
in_chans=3, embed_dim=embed_dims[0])
# set the main block in network
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios[i],
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i+1]:
# downsampling between two stages
network.append(
PatchEmbed(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i+1]
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
# TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used.
cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...`
"""
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.apply(self.cls_init_weights)
self.init_cfg = copy.deepcopy(init_cfg)
# load pre-trained model
if self.fork_feat and (
self.init_cfg is not None or pretrained is not None):
self.init_weights()
# init for classification
def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
# init for mmdetection or mmsegmentation by loading
# imagenet pre-trained weights
def init_weights(self, pretrained=None):
logger = get_root_logger()
if self.init_cfg is None and pretrained is None:
logger.warn(f'No pre-trained weights for '
f'{self.__class__.__name__}, '
f'training start from scratch')
pass
else:
assert 'checkpoint' in self.init_cfg, f'Only support ' \
f'specify `Pretrained` in ' \
f'`init_cfg` in ' \
f'{self.__class__.__name__} '
if self.init_cfg is not None:
ckpt_path = self.init_cfg['checkpoint']
elif pretrained is not None:
ckpt_path = pretrained
ckpt = _load_checkpoint(
ckpt_path, logger=logger, map_location='cpu')
if 'state_dict' in ckpt:
_state_dict = ckpt['state_dict']
elif 'model' in ckpt:
_state_dict = ckpt['model']
else:
_state_dict = ckpt
state_dict = _state_dict
missing_keys, unexpected_keys = \
self.load_state_dict(state_dict, False)
print('missing_keys: ', missing_keys)
print('unexpected_keys: ', unexpected_keys)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
return x
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
if self.fork_feat:
# output the features of four stages for dense prediction
return outs
# output only the features of last layer for image classification
return x
def forward(self, x):
# input embedding
x = self.forward_embeddings(x)
# through backbone
x = self.forward_tokens(x)
if self.fork_feat:
# otuput features of four stages for dense prediction
return x
x = self.norm(x)
cls_out = self.head(x.mean([-2, -1]))
# for image classification
return cls_out
总结
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选

评论