
【Python实战案例】读取Excel批量替换Word局部信息
蚂蚁学Python
共 2605字,需浏览 6分钟
· 2021-11-28
一个word办公自动化的私活
最近接到一个单子,需要我将word文档中的关键信息(红色字体内容)替换为一个excel文档中的一行数据,并能够批量化的将excel文档中的每个数据依据这个word模板生成对应数量的word文件。
做了一下午,总算拿到佣金,还是挺开心的
接下来看看,先看下数据源和要替换的word模板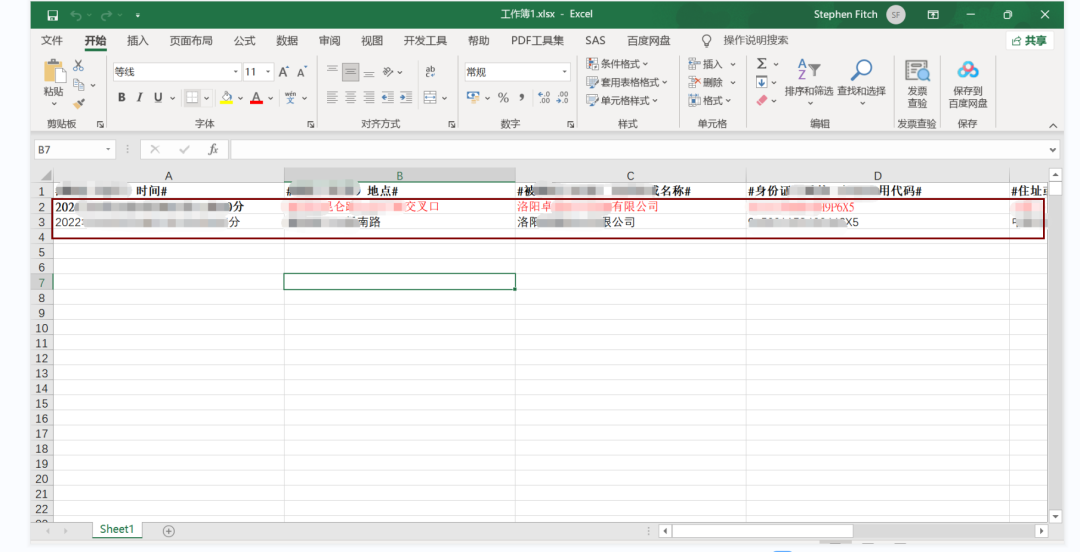 (数据源)
(数据源)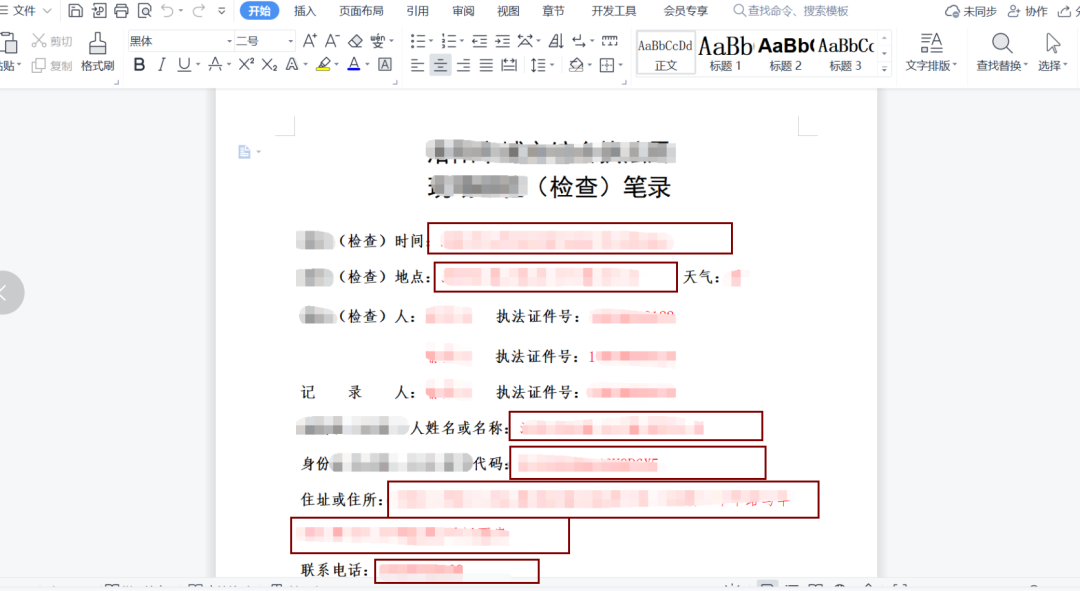 (word模板)
(word模板)
主要原理
这里主要的原理是我使用了专门处理word的python扩展包python-docx,然后提取段落,对段落中执行文档的编号进行遍历,由于格式是固定的,那么只要对每个段落对象进行计数,然后按照对应计数来进行数组定位,并把从excel中读取到的字段值进行替换就可以达到批量生成模板数据的要求了。
看下代码:
from docx import Document
import docx
import pandas as pd
df = pd.read_excel(r'工作簿1.xlsx')
#读取excel数据
for i in df.index:
# 实例化一个文件对象
doc = Document(r'1XXXXXXXXXXX模版.docx')
tm = df.loc[i,"#XXXXXX 时间#"]
plc = df.loc[i,"#XXXXX 地点#"]
chp = df.loc[i,'#被XXXXX 姓名或名称#']
ids = df.loc[i,'#XXXX 社会XXXX码#']
adr = df.loc[i,'#住XXXXX所#']
ph = df.loc[i,'#联XXXX话#']
cp = df.loc[i,'#现XXXXX人#']
idp = df.loc[i,'#身XXXX号#']
# 定位信息节点:
doc_paras = doc.paragraphs
count = 0
for para in doc_paras[3:14]:
print("段落"+str(count))
if count == 9:
col1 = para.text.split(":")
col1[2] = idp
col1[1] = col1[1].split(" ")
col1[1][0] = cp
col2 = col1[0]+":"+col1[1][0]+" "+col1[1][1]+":"+str(col1[2])
para.text = col2
elif count==0:
col = para.text.split(":")
col[1] = tm
res = ":".join(col)
para.text = res
print(para.text)
elif count==1:
col1 = para.text.split(" ")
col2 = col1[0].split(":")
col2[1] = plc
col3 = col2[0]+":"+col2[1]+" "+col1[1]
para.text = col3
print(para.text)
elif count==5:
col1 = para.text.split(":")
col1[1] = chp
col2 = col1[0]+":"+col1[1]
para.text = col2
print(para.text)
elif count==6:
col1 = para.text.split(":")
col1[1] = ids
col2 = col1[0]+":"+col1[1]
para.text = col2
print(para.text)
elif count==7:
col1 = para.text.split(":")
col1[1] = adr
col2 = col1[0]+":"+col1[1]
para.text = col2
print(para.text)
elif count==8:
col1 = para.text.split(":")
col1[1] = ph
col2 = col1[0]+":"+str(col1[1])
para.text = col2
print(para.text)
count+=1
doc.save(rf'new{i}.doc')
最终实现了所有对应数据的替换,python在处理word方面的办公自动化比起excel来,一点也不差,而且可以和excel进行结合,产生更多不可思议的高效功能。

图中红色框就是被替换的程序,这段代码将来会用在他们的很多部门,预计能够批量产生几百上千个类似表格,悬赏人对我感谢之情溢于言表。
最后,推荐蚂蚁老师的《零基础入门Python到办公自动化》课程
评论
盘点一个使用超级鹰识别验证码并自动登录的案例
点击上方“Python共享之家”,进行关注回复“资源”即可获赠Python学习资料今日鸡汤江上几人在,天涯孤棹还。大家好,我是皮皮。一、前言前几天在Python钻石交流群【静惜】问了一个Python实现识别验证码并自动登录的问题,提问截图如下:验证码的截图如下所示:二、实现过程这里大家激烈的探讨,【
IT共享之家
0
Python列表知识应知应会
点击上方“Go语言进阶学习”,进行关注回复“Go语言”即可获赠从入门到进阶共10本电子书今日鸡汤只在此山中,云深不知处。一、前言 在Python程序开发中,列表(List)经常会使用。假设一个班里有50个学生现需要统计每一个学生的总成绩情况,如果不使用列
Go语言进阶学习
0
Python 字符串应该用双引号还是单引号?
转载来源:洪尔摩斯PyCharm升级至 2023.2版本后,经常弹出来一个提示问我要不要试一下Black formatter。试了一下,这个Black formatter 很有个性,特别喜欢换行。我的一个文件用PyCharm自带的代码整理器整理完之后是500行左右,然后再用Black整理就变成600
菜鸟学Python
0
delorean,一个超级实用的 Python 库!
作者通常周更,为了不错过更新,请点击上方“Python碎片”,“星标”公众号大家好,今天为大家分享一个超级实用的 Python 库 - delorean。Github地址:https://github.com/myusuf3/delorean/时间在计算机科学和软件开发中是一个至关重要的概念。Pyt
Python 碎片
0
【每周一课#06】MidJourney应用实战
#AI绘画# #MJ# #文生图#时间:4月24日周三 21:00课程大纲:1、关于AIGC:概念、发展历程、就业前景2、MJ基础认识:如何使用、底层逻辑、MJ与SD优缺点比较3、MJ基础功能介绍:任务指令、后缀参数、图生图、图生文、垫图、局部修改等4、MJ应用场景与变现方向
Python涨薪研究所
0
五一Python抢票神器来了
还在为五一回家抢不到火车票发愁吗?今天介绍一个Python抢票神器,希望对你有帮助。Py12306是一个流行的开源项目,旨在帮助用户更便捷地查询和预订中国铁路12306网站上的火车票。以下是使用Py12306的基本步骤和一些注意事项:安装与环境准备安装Python: 确保你的系统中安装了Python
Python小二
1
PyPy为什么能让Python比C还快?一文了解内在机制
我的小册:(小白零基础用Python量化股票分析小册) ,原价299,限时特价2杯咖啡,满100人涨10元。来源:机器之心「如果想让代码运行得更快,您应该使用 PyPy。」—— Python 之父 Guido van Rossum对于研究人员来说,迅速把想法代码化并查看其是否行得通至关重要。Pyth
菜鸟学Python
0
高并发实战案例 100 讲,已更新24节,即将涨价,抓紧了
大家好,我是路人。本人亲自录制的《Java 高并发 & 微服务 & 性能调优实战案例 100 讲》已发布了 24 个课时,干货满满。59元,一杯咖啡的价格,100个实战案例,即将涨价到 99,需要的小伙伴速度啦,文末附下单方式。已发布 24 个课时1、SpringBoot实
路人甲Java
0