
超实用半监督目标检测 Soft Teacher 及 MMDetection 最强代码实践
1 前言
本文分析一篇微软发布的 ICCV2021 工作 Soft Teacher,正如标题所言, Soft Teacher 算是一个比较好偏实用的半监督目标检测算法。不光如此,其基于 MMDetection 开源的代码也硬核优异,值得深入解读。简而言之:
1. 如果想了解 Soft Teacher 细节及其实现过程,那么本文适合你
2. 如果你是 MMDetection 或者 OpenMMLab 的粘性用户,希望了解一些新的用法或者说半监督目标检测如何在 MMDetection 中实现,那么本文也适合你
注意本文不是标题党(从不做这个事情[手动狗头]),取 MMDetection 最强代码实践 这个标题是经过思考的。我维护 MMDetection 也有一段时间了,对整个框架算是有一点点了解的,从我个人角度来看,这篇文章吸引我写解读文章,一个原因是实用性和最终效果,还有一个很大部分是因为其开源代码,我觉得他这个代码整体设计的还可以,至少给出了一个可行的在 MMDetection 中实现半监督目标检测的思考,值得各位 MMDetection 党学习。如果你也有类似需求可以参考下本文,本文会深入讲解。
论文标题:
End-to-End Semi-Supervised Object Detection with Soft Teacher
论文地址:
https://arxiv.org/abs/2106.09018
代码地址:
https://github.com/microsoft/SoftTeacher
MMDetection 官方地址:
https://github.com/open-mmlab/mmdetection
如果你觉得本文解读对你有一点点帮助,麻烦给 MMDetection 个 star,也算是给我周末辛苦解读的一点点鼓励吧!
2 半监督算法简介
为了照顾初学者,需要简要说明下半监督目标检测任务。半监督相对于全监督含义是训练中使用了部分没有标注的数据。大家都知道 AI 时代数据很重要,标注很昂贵,如何基于少量已标注数据和大量无标签数据进行训练即为半监督目标检测算法要解决的问题。
早期半监督算法主要用于分类任务,后续半监督检测、分割等等任务其实都大量参考了半监督分类算法思考。简单来说,半监督分类常用做法可以归纳为:
1 简单自训练 simple self-training 或者或伪标签学习
用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label) 或软标签 (soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则),把选出来的无标签样本用来训练分类器
2 协同训练 co-training
假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度,就如同从不同角度可以更好地理解事物一样。
当然后面提出的算法都是混合两个做法的。
2.1 伪标签学习
伪标签学习最经典的论文是:Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
运用训练出的模型给予无标签的数据一个伪标签。用训练中的模型对无标签数据进行预测,以概率最高的类别作为无标签数据的伪标签;
运用 entropy regularization 思想,将无监督数据转为目标函数的正则项。实际中就是将拥有伪标签的无标签数据视为有标签的数据,然后用交叉熵来评估误差大小。
由于早期伪标签可能不准确,无标签 loss 会采用一个时变函数加权。为了防止无监督标签引入过多噪声,实际上都是基于 epoch 来更新无标签数据的伪标签的,效果会更好。
而协同训练早期方法包括 π-model 和 Temporal Ensembling,然后演变出 Mean teachers。Mean teachers 是一个非常有名且使用的半监督算法,大概如下:
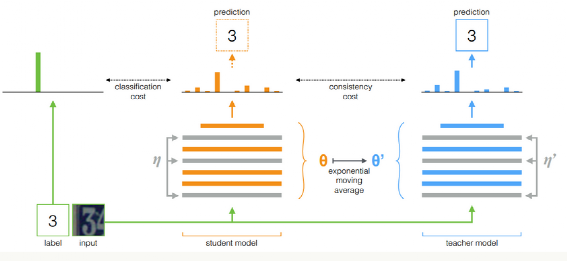
其训练流程为:
将有标签数据输入学生模型,计算 loss1
将无标签数据输入学生模型,得到预测概率分布
将无标签数据输入教师模型,得到伪标签分布
采用一致性 loss 对两个分布进行约束,使他们尽可能相同
两个 loss 加权
在每个 step 更新学生模型后,对学生模型参数对教师模型进行更新,更新规则是 Mean Teacher 方式
其核心思想是:模型既充当学生,又充当老师。作为老师,用来产生学生学习时的目标;作为学生,则利用教师模型产生的目标来进行学习。而教师模型的参数是由历史上(前几个 step )几个学生模型的参数经过加权平均得到。
2.2 一致性正则和混合策略
经过这几年发展,半监督分类算法取得了很大进步,陆续出现了爆款 MixMatch、Remixmatch、FixMatch、UDA 和 Noisy Student 等等做法,本文算法中就用到了 FixMatch 算法思想。
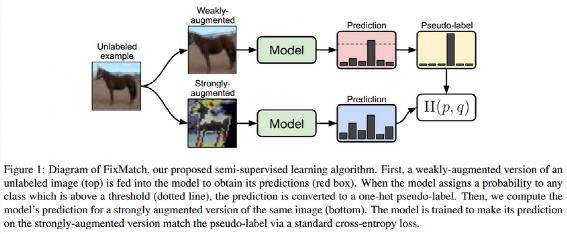
FixMatch 是一个非常简单但是效果好的算法,看起来和伪标签做法非常类似,其主要区别在于引入了强和弱数据增强。属于是一致性正则化和伪标签学习两种方法的联合。
利用弱增强生成 hard 伪标签,然后利用强增强的预测值和伪标签进行一致性正则化学习。但是是否采用伪标签,是依靠弱增强分支的预测置信度的,如果太低说明不靠谱不进行一致性正则,该策略非常关键。这里的弱增强是指翻转和平移增强。强增强就比较多了,作者比较了好几种增强包括RandAugment 和 CTAugment,同时也应用了cutout增强。
一般来说,有监督 loss 和无监督正则 loss 都有一个平衡权重参数,而且在训练时候权重是慢慢增加,但是在本文算法中作者说不需要,直接设置为 1 就行,原因可能是正则 loss 只有在大于置信度阈值情况下才起左右,作者觉得这个设置起到了同样的作用。
既然分类任务可以很好的解决半监督问题,那么目标检测也可以,例如本文中提到的谷歌论文 A Simple Semi-Supervised Learning Framework for Object Detection,简称 STAC
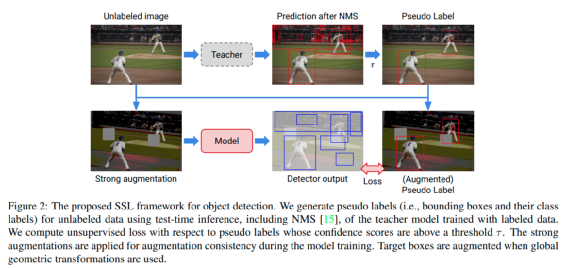
其训练步骤如下:
在有标签图像上训练教师模型
使用训练好的教师模型生成无标签图像的伪标签(即边界框及其类标签)。
对未标记的图像应用强数据增强,并在应用全局几何变换时变换相应的伪标记(即边界框)
计算无标签损失和有标签损失以训练检测器
整个流程非常简单,但是不是端到端训练的。基于此,微软学者提出了 Soft Teacher 算法
Soft Teacher 专注于半监督算法中常用的伪标签范式,因为这类算法简单实用。作者认为 STAC 这种做法是多阶段训练模式,第一阶段使用标记数据训练初始检测器,然后是未标记数据的伪标记过程和基于伪标记未标注数据的重新训练步骤。然而最终性能受限于使用少量标记数据训练的初始检测器生成的伪标签质量,并且可能不准确。
故提出基本观点:联合训练比分阶段训练更好,在每个训练 step 中同时执行生成伪标签和利用伪标签对无标签图片进行训练。大概流程是从带标签图片数据和无标签数据集中按照比例随机采样数据构成一个 batch;在这些图像上应用了两种模型,一种进行检测训练,另一种负责为未标记的图像注释伪标签。前者也称为学生,后者是教师,其是学生模型参数的指数移动平均值。当然性能也是非常优异:

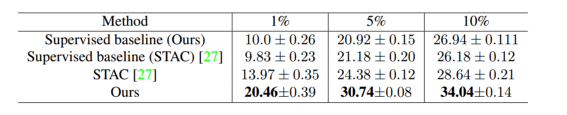
在 MS-COCO 对象检测基准上,本文方法在 val2017 上实现了 20.5 mAP、30.7 mAP 和 34.0 mAP,使用带有 ResNet-50 的 Faster R-CNN框架,分别使用 1%、5% 和 10% 的标记数据,性能远超 STAC,最高刷到了 61.3 mAP。
3 Soft Teacher 原理详解
3.1 流程说明
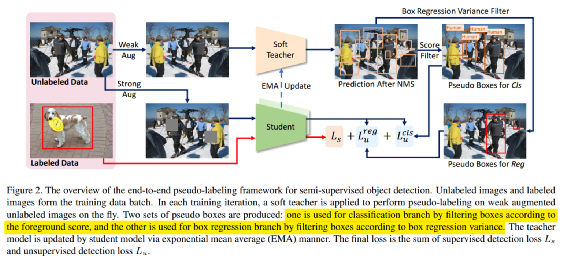
整个训练流程如上所示。其大概流程可以归纳为:
教师模型和学生模型是两个完全相同的结构,因为要进行 EMA 更新,两者都是带有预训练的随机初始化
有标签图片采用常规的 pipeline 流程,利用学生模型进行预测,计算得到有标签的 loss,包括分类和回归分支 loss
参考 FixMatch 做法,无标签数据会经过强和弱两种不同的 aug pipeline,其中弱增强线输入到教师模型,而强增强线用于学生模型
对于弱增强线的图片,经过教师模型推理预测,nms 后处理可以得到检测结果。前面说过伪框的质量对最终性能影响非常大,需要小心处理,作者采用了高阈值来过滤教师模型的检测结果将其作为强增强线学生模型预测值中分类分支的标签,然而这可能导致许多学习模型预测值中真正的候选框被错误地分配为背景样本。为了解决这个问题,作者建议使用可靠性度量来加权每个“背景”候选框的损失,而实测发现教师模型产生的背景检测分数可以很好地作为可靠性度量。这种监督方式实测效果远好于 hard 标签训练方式,所以本文才称为 soft teacher
由于分类分支和检测分支预测的不一致性以及任务的不一致性,我们也需要找到一个可靠性指标来反应伪框的可信度,但是观察发现定位精度和前景分值没有很大联系,所以作者采用了另一种方法即通过框抖动 box jittering 选择可靠的边界框来训练学生模型的定位分支,这种方法首先多次抖动伪前景框候选;然后在利用教师模型对这些抖动框进行回归(实际上是 rcnn 分支进一步 refine ),并将这些回归框的方差用作可靠性度量;最后将具有足够高可靠性的 box 候选用于学生定位分支的训练。
可以看出强增强线学生模型的无标签分类和回归分支的伪标签是不一样的。教师模型采用 Mean Teachers 方法进行更新
从上文可以看出,本文主要是提出一个端到端 teacher 和 student 联合学习算法,并提出了两个新的改进:
提出一种 soft teacher 机制,其中每个无标记分支预测值的分类损失由教师网络产生的分类分数加权
提出一种框抖动 box jittering 方法,用于选择可靠的伪框以进行无标记分支预测值的回归分支框学习
上述两个步骤非常重要。
3.1 loss 说明
学生模型通过有标记图像上的检测损失和使用伪框的未标记图像上的检测损失来联合学习。总的训练 loss 如下:
Ls 表示有标签图片监督 loss,Lu 表示无标签图片监督 loss
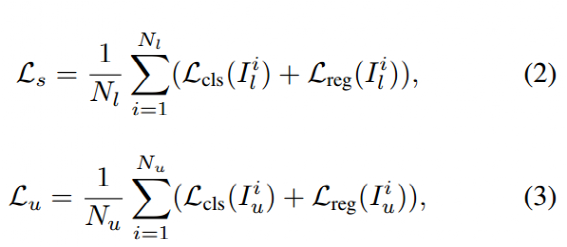
其中每个部分都包括分类分支和定位分支的 loss,全部通过图片数进行规范化操作。
对于有标签 loss 部分,是采用 Faster R-CNN 标准做法,作者没有做改动。
在实验发现采用高阈值来过滤学生模型产生的候选框效果比低阈值好,最好性能阈值是0.9。然而如果阈值过高,虽然精度上去了,但是召回率很低,此时如果我们采用教师生成的伪框和学生模型生成的预测框计算 iou 来区分正负样本,很多前景样本会被认为是背景,这就有问题了。解决上述问题的办法是 soft teacher,对背景预测框的分类 loss 进行自适应加权。
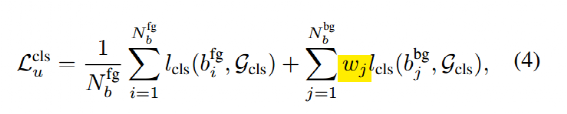
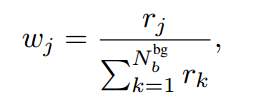
前面利用了教师模型预测背景分值作为可靠性度量,但是定位精度和前景分值没有很大联系,分类分支么有一个明显的指标来衡量,作者采用 jittering + refine 模式来得到具体是:对教师模型预测框进行抖动,然后从新喂给教师模型,多次 refine 后计算方差。小的方差代表更高的定位可靠度,然而在训练过程中对所有伪框进行 refine 会特别慢,所以实际上仅仅选择前景分值高于 0.5 的候选框进行 refine,得到方差后,在实际训练时候仅仅选择方差小的框进行训练,也就是说这部分框才是最终的定位分支伪标签。
简要说明下半监督目标检测的两种评估模式:
部分标签数据集:这部分是参考 STAC 做法,将 train2017 分成 1%、 5%、 10% 一共 3 种比例,其他数据当作无标签数据,对每个设置都采用 5 折交叉验证,然后取 5 次平均值作为最终性能
全部标签数据集:全部 coco train2017 + 无标签 2017数据集,然后在 val2017 上进行评估。
两种评估模式结果如下:
4 核心开源代码分析
文章开头说过本文一大亮点是开源代码,所以如果你只是看到前 3 章,那么你亏了,第 4 和 5 章也是必读部分。
第 4 部分重点分析算法流程,第 5 部分重点探讨开源代码亮点。通过本文你将了解到如何将 MMDetection 框架如何扩展到支持半监督检测任务上。
本章将按照半监督目标检测训练流程来分析。任何一个训练任务运行流程都是从 dataset 出发,最终到 loss 输出,主要包括 dataset、pipeline、sampler、model、loss 等部分。
4.1 Dataset
目标检测都是一个 dataset + 一个 数据处理 pipeline + 一个模型,但是半监督目标检测算法需要同时处理带标签数据和无标签数据,也就是说有两个 dataset、两个数据处理 pipeline,故这部分必须要进行改造。
class SemiDataset(ConcatDataset):"""Wrapper for semisupervised od."""def __init__(self, sup: dict, unsup: dict, **kwargs):# build 两个 datast,分别代表有标签数据集和无标签数据集super().__init__([build_dataset(sup), build_dataset(unsup)], **kwargs)# 设置属性,方便处理def sup(self):return self.datasets[0]def unsup(self):return self.datasets[1]
作者直接继承 ConcatDataset,并新写了一个 SemiDataset,本质上 SemiDataset 就是一个 ConcatDataset,其将有标签分支 dataset 和无标签分支的 dataset 拼接起来,不过由于后续要区分不同分支,故还额外新增了两个属性 sup、unsup,每个 build_dataset 都是 COCODataset。
对于有标签数据集,采用了 STAC 论文中提到的数据处理流程即:
dict(type="Sequential", # 序列 pipelinetransforms=[dict(type="RandResize",img_scale=[(1333, 400), (1333, 1200)],multiscale_mode="range",keep_ratio=True,),dict(type="RandFlip", flip_ratio=0.5),dict(type="OneOf", # 随机取一个transforms=[dict(type=k)for k in ["Identity","AutoContrast","RandEqualize","RandSolarize","RandColor","RandContrast","RandBrightness","RandSharpness","RandPosterize",]],),],),
熟悉 Albu 增强库的用户一眼就能看出,这个写法是参考其 api 而来,含义也比较好理解,没必要解释。
对于无标签数据集,参考 FixMatch 半监督分类算法,对于教师网络和学生网络分别采用了弱增强和强增强,也就是说无标签数据集的 pipeline 实际上两条,加起来本文一共有 3 条 pipeline,但是目前 MMDectection 中都是单线串行用法,暂时还没有这种一次运行两条 pipeline 的写法(当然后面会有),故作者重写了新的 pipeline,配置写法为:
# 因为这个分支没有标签,为了对齐和方便后续处理,这里存储假的标签dict(type='PseudoSamples', with_bbox=True),dict(type='MultiBranch',unsup_student=[...,dict(type='ExtraAttrs', tag='unsup_student'),....] # 强 augunsup_teacher=[...,dict(type='ExtraAttrs', tag='unsup_teacher'),....] # 弱 aug
运行 unsup_student pipeline,然后将这个 pipeline 输出的内部打上 unsup_student 标签,后续可以基于这个 tag 判断这个 pipeline 是 unsup_student也就是利用 MultiBranch pipeline 在内部分叉
运行 unsup_teacher,打上 unsup_teacher 标签,这样就可以保证运行完成后得到两个 pipeline 结果
通过 tag 就可以区分强弱增强和学生网络和教师网络所需要的数据。MultiBranch 输出是 list 而不是我们常用的 dict。
还有一个细节要注意:在本算法中教师模型预测的检测框来作为伪标签用于学生网络,但是由于同一张图片采用了不同的几何增强,导致这两个网络最终接收的图片其实不一样,为了能够将教师模型预测框用于学生网络,需要记录两条 pipeline 中涉及到的所有几何变换过程,将其转换为一个变换矩阵,后续基于该变换矩阵就可以随意变换到不同的网络上。故在每个涉及几何变换的 pipeline 中都有 record 参数用于记录变换矩阵。
class GeometricTransformationBase(object):def inverse(cls, results):# compute the inversereturn results["transform_matrix"].I # 3x3def apply(self, results, operator, **kwargs):trans_matrix = getattr(self, f"_get_{operator}_matrix")(**kwargs)if "transform_matrix" not in results:results["transform_matrix"] = trans_matrixelse:base_transformation = results["transform_matrix"]results["transform_matrix"] = np.dot(trans_matrix, base_transformation)def _get_rotate_matrix(cls, degree=None, cv2_rotation_matrix=None, inverse=False):def _get_shift_matrix(cls, dx=0, dy=0, inverse=False):
到此就已经将 dataset 和 pipeline 流程分析完成了,其全局流程大概为:
# 半监督dataset,内部维护了两个 dataset,分别是 sup 和 unsuptype='SemiDataset',sup=dict(type='CocoDataset',pipeline=[...,# 标签为有标签分支,用于学生网络dict(type='ExtraAttrs', tag='sup'),,...]unsup=dict(type='CocoDataset',pipeline=[...,# 因为这个分支没有标签,为了对齐和方便后续处理,这里存储假的标签dict(type='PseudoSamples', with_bbox=True),dict(type='MultiBranch', # 多分支结构unsup_student=[...,# 标签为无标签分支,用于学生网络dict(type='ExtraAttrs', tag='unsup_student'),...]unsup_teacher=[...,# 标签为无标签分支,用于教师网络dict(type='ExtraAttrs', tag='unsup_teacher'),...]
4.2 Sampler
论文中提到按照 1:4 的比例随机从有标签数据集和无标签数据集中采样数据组成一个 batch 进行训练,要实现这个功能需要通过 Sampler 实现,也就是代码中的 GroupSemiBalanceSampler 和 DistributedGroupSemiBalanceSampler。
首先要明白 Sampler 的基本功能是提供采样索引,例如最简单的 SequentialSampler 就是输出 0,1,2,...,len(dataset)-1 的迭代器。
class SequentialSampler(Sampler[int]):r"""Samples elements sequentially, always in the same order.Arguments:data_source (Dataset): dataset to sample from"""data_source: Sizeddef __init__(self, data_source):self.data_source = data_sourcedef __iter__(self):return iter(range(len(self.data_source)))def __len__(self) -> int:return len(self.data_source)
如果对这部分知识不够清楚可以参考之前文章:
GroupSemiBalanceSampler 目的也是输出特定的索引迭代器,假设 batch 为 5,我们需要一个 batch 中必须有 4 张图片来自无标签图片,1 张图片来自有标签数据,则我们可以生成类似
[# 前面5个组成一个 batch,内部顺序可以随意打乱,只要保证 1:4 即可sup_data_index_1,sup_data_index_2,sup_data_index_3,sup_data_index_4,upsup_data_index_1,# 下面5个组成一个 batch,内部顺序可以随意打乱,只要保证 1:4 即可sup_data_index_5,sup_data_index_6,sup_data_index_7,sup_data_index_8,upsup_data_index_2, # 这5个组成下一个 batch...]
而 Group 是因为目标检测领域本身就有个常用的分组功能,将宽高比一致的图片分组,同组内宽高比一致,组成一个 batch,防止 padding 过多。由于这个部分代码比较复杂,故本文不详细说明,读者只需要他想要实现的功能就行。如果你在开发中也有类似的对单个 batch 内数据组成要求,则可以仔细阅读这个 Sampler。
4.3 Collate
Collate 函数是 Dataloader 中的聚合函数,目的是将 batch 个数据聚合为 batch 的 4d 格式数据。因为MMDectection 中的 Dataset 输出的每个图片大小可能不一样,无法直接组成 batch,故需要重写 collate,内部通过 padding 来使其能够组成 batch。
但是前面说过,本论文的 dataset pipeline 输出比较特殊有两条分支,MMDectection 中重写的 collate 无法满足需求,故本文还需要进一步重写来处理上述情况
# 特殊处理 list 结构elif any([isinstance(b, Sequence) for b in batch]):if flatten:flattened = []for b in batch:if isinstance(b, Sequence):flattened.extend(b)else:flattened.extend([b])return collate(flattened, len(flattened))else:transposed = zip(*batch)return [collate(samples, samples_per_gpu) for samples in transposed]elif isinstance(batch[0], Mapping):return {key: collate([d[key] for d in batch], samples_per_gpu) for key in batch[0]}else:return default_collate(batch)
只需要理解上述代码在干啥就行。
4.4 Model
本算法中学生网络和教师网络采用同一个网络即 Faster R-CNN,网络模型完全相同,但是不同于常规单模型目标检测,其包括两个模型且是联合训练,如果不进行改写则难以满足要求
semi_wrapper = dict(type='SoftTeacher',model='${model}',train_cfg=dict(use_teacher_proposal=False,pseudo_label_initial_score_thr=0.5,rpn_pseudo_threshold=0.9,cls_pseudo_threshold=0.9,reg_pseudo_threshold=0.02,jitter_times=10,jitter_scale=0.06,min_pseduo_box_size=0,unsup_weight=4.0),test_cfg=dict(inference_on='student'))
为此作者新写了一个双流检测器基类 MultiSteamDetector 用于同时构建教师和学生模型,并固定教师模型权重,其权重更新规则是通过学生模型的 Mean Teacher Hook 实现。
由于其训练部分代码比较简单,故直接通过代码简要说明,其最外层训练逻辑为:
def forward_train(self, img, img_metas, **kwargs):super().forward_train(img, img_metas, **kwargs)# 假设按照 1:4 混合,img 的 shape 是 [5,3,h,w]kwargs.update({"img": img})kwargs.update({"img_metas": img_metas})kwargs.update({"tag": [meta["tag"] for meta in img_metas]})# 分成3组:有标签,无标签教师,无标签教师,每组都包括 img img_metas gt_bbox等data_groups = dict_split(kwargs, "tag")for _, v in data_groups.items():v.pop("tag")loss = {}if "sup" in data_groups:# 有标签分支正常训练gt_bboxes = data_groups["sup"]["gt_bboxes"]log_every_n({"sup_gt_num": sum([len(bbox) for bbox in gt_bboxes]) / len(gt_bboxes)})sup_loss = self.student.forward_train(**data_groups["sup"])sup_loss = {"sup_" + k: v for k, v in sup_loss.items()}loss.update(**sup_loss)if "unsup_student" in data_groups:# 无标签分支训练,也是本文的重点unsup_loss = weighted_loss(self.foward_unsup_train(data_groups["unsup_teacher"], data_groups["unsup_student"]),weight=self.unsup_weight, # 权重是 4)unsup_loss = {"unsup_" + k: v for k, v in unsup_loss.items()}loss.update(**unsup_loss)return loss
包括两个部分:有标签数据分支训练过程和无标签训练分支过程,其核心在于无标签分支训练过程。其详细过程可以归纳为以下几个步骤:
Dataloader 输出无标签教师网络所需图片和数据,教师网络对弱增强线输出的图片进行推理,经过 NMS 后得到预测框和类别
利用 pseudo_label_initial_score_thr = 0.5 过滤阈值去除分值比较低的检测框和类别
学生网络的分类 loss 自适应权重可以通过教师模型的背景预测概率得到,但是定位分支 loss 需要通过 box jittering 和 refine 得到,故需要对剩下的检测框进行 jittering 和 refine 计算得到每个检测框的回归分支不确定度
教师模型得到的伪框作为标签,分别用于 RPN 和 R-CNN 阶段,具体如下
(4-1) 利用变换矩阵将教师模型得到的伪框变换到学习模型尺度上
(4-2) 学生模型接收强增强线图片输入,进行 RPN 和 R-CNN 预测
(4-3) 利用 rpn_pseudo_threshold=0.9 阈值过滤第 2 步的伪框,将其对学生模型的 RPN 分支进行训练,并将 RPN 输出后处理得到 R-CNN 阶段所需的 proposal_list 。RPN 阶段只需要传入 4d 伪框即可,不需要考虑类别。
(4-4) 利用 cls_pseudo_threshold=0.9 阈值过滤第 2 步的伪框,然后和 proposal_list 计算正负样本,此时可以得到哪些位置预测框是正样本和负样本
(4-5) 将 proposal_list 输入到教师模型的 R-CNN 阶段,得到每个 proposal 的预测分值,提取其背景预测分值作为分类分支背景样本的 loss 的自适应权重,实际代码实现上面是直接作为 bg soft label 使用的,效果上等价
(4-6) 无标签回归分支 loss 算法类似,其只计算正样本的回归 loss,对第 4-1 参数的伪框中的每个框的回归分支不确定度应用 reg_pseudo_threshold=0.02 过滤阈值,然后计算 loss 即可
处理的核心思想是:学习模型的分类分支和回归分支所需要的伪框不一样,需要通过不同的计算方法得到各自所需的伪框可信度,进而得到伪框。
到这里整个算法就分析完成了。
5 代码亮点总结
下面对整个开源代码中的亮点代码进行解读。
5.1 开发新思路
请注意下面写法:
mmdet_base = "../../thirdparty/mmdetection/configs/_base_"_base_ = [f"{mmdet_base}/models/faster_rcnn_r50_fpn.py",f"{mmdet_base}/datasets/coco_detection.py",f"{mmdet_base}/schedules/schedule_1x.py",f"{mmdet_base}/default_runtime.py",]
一般来说,MMDectection 库的扩展开发有以下几种:
pip install mmdet 到 site-package 中当做一个第三方包用,然后进行扩展开发。这是我们推荐的开发模式
通过 mim 管理,这个也是官方推荐开发模式
直接源码开发
第三种开发模式不太推荐,其有个非常大的缺点:基于源码开发的代码别人无法知道你到底改了哪些地方。但是前两种开发模式也存在的一个小问题(其实如果你不介意,不算问题吧):安装的包中不会包括配置文件,而大家的开发通常会基于我们发布的配置文件进行继承修改。
这种情况下如果想基于已经发布的配置文件扩展开发,你需要先去 github 上下载下来,然后 copy 到当前工程的相对路径下,如果你要下载的配置还依赖了好几个 base 配置,那么也要一并下载,稍微有点麻烦。
此时你可能想不 copy,能不能在 _base_ 中通过指定网络 url 就可以? 例如我想基于faster_rcnn_r50_fpn_1x_coco.py这个配置开发,那么 base 字段写法支持:
_base_ ='https://github.com/open-mmlab/mmdetection/blob/master/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'但是不好意思还不支持(如果需求强烈,或许可以考虑),而本开源代码提供一种相对可以接受的办法:
python -m pip install -r requirements.txt -f https://download.pytorch.org/whl/torch_stable.htmlmkdir -p thirdpartygit clone https://github.com/open-mmlab/mmdetection.git thirdparty/mmdetectioncd thirdparty/mmdetection && python -m pip install -e .
新建一个 Makefile 文件,在使用本库前执行 make install ,会运行上面代码即自动 git clone mmdet 库到指定路径,然后在本 repo 内部 pip -e 模式安装,这样就兼顾了上面提到的需求,不失为一种折中办法。
5.2 配置写法增强
如果你对 OpenMMLab 开源库熟悉的话,你肯定没有见过如下写法:
f"{mmdet_base}/models/faster_rcnn_r50_fpn.py"log_config = dict(interval=50,hooks=[dict(type="TextLoggerHook", by_epoch=False),dict(type="WandbLoggerHook",init_kwargs=dict(project="pre_release",name="${cfg_name}",config=dict(work_dirs="${work_dir}",total_step="${runner.max_iters}",),),by_epoch=False,),],)work_dir = "work_dirs/${cfg_name}/${percent}/${fold}"
这是一个非常好的特性,因为上述写法有以下几个优点:
某个配置字段横跨几个文件,例如 num_class 字段,可能好几个文件都需要,正常开发方式是打开每个配置文件进行修改,缺点很明显不好维护而且经常容易网络。然而如果采用上述做法,则只需要在某一个文件或者代码位置定义,然后其他所有文件和代码位置引用就行,这样维护成本大大降低,出错的概率很低
有些参数无法在类初始化时候定义,只能在运行后才知道,例如上述的 name 字段,之前的做法是没有很好的解决办法的,只能在配置中固定住
含义清晰,容易理解
OpenMMLab 现在还不支持上述配置写法,为了解决碰到的问题,作者对配置文件功能进行了增强,可以看出作者对 MMDetection 很熟悉且很牛,我咋没有想到这种开发模式?
功能的实现比较简单,无非是规则解析:
pattern = re.compile("\$\{[a-zA-Z\d_.]*\}")def resolve(cfg: Union[dict, list], base=None):if base is None:base = cfgif isinstance(cfg, dict):return {k: resolve(v, base) for k, v in cfg.items()}elif isinstance(cfg, list):return [resolve(v, base) for v in cfg]elif isinstance(cfg, tuple):return tuple([resolve(v, base) for v in cfg])elif isinstance(cfg, str):# processvar_names = pattern.findall(cfg)if len(var_names) == 1 and len(cfg) == len(var_names[0]):return get_value(base, var_names[0][2:-1])else:vars = [get_value(base, name[2:-1]) for name in var_names]for name, var in zip(var_names, vars):cfg = cfg.replace(name, str(var))return cfgelse:return cfg
如果遍历时候发现 cfg 内容是字符串,例如 "work_dirs/${cfg_name}/${percent}/${fold}" 这种,则先采用正则匹配找出 ${cfg_name}、${percent} 和 ${fold} 中的 cfg_name、percent 和 fold,然后从 cfg 中找到对应值赋予给他即可。
不错吧!
5.3 Pipeline 写法增强
仔细留意下 Sequential 数据增强 pipeline 写法
dict(type="LoadAnnotations", with_bbox=True),dict(type="Sequential",transforms=[dict(type="RandResize",img_scale=[(1333, 400), (1333, 1200)],multiscale_mode="range",keep_ratio=True,),dict(type="RandFlip", flip_ratio=0.5),dict(type="OneOf",transforms=[dict(type=k)for k in ["Identity","AutoContrast","RandEqualize","RandSolarize","RandColor","RandContrast","RandBrightness","RandSharpness","RandPosterize",]],),],),
这个 Sequential pipeline 写的也是非常好非常规范,主要目的是可以将 pipeline 打包。看到这里,让我想到我在 YOLOX 开发中写的 pipeline:
dict(type='Mosaic', img_scale=img_scale, pad_val=114.0),dict(type='RandomAffine',scaling_ratio_range=(0.1, 2),border=(-img_scale[0] // 2, -img_scale[1] // 2)),dict(type='MixUp',img_scale=img_scale,ratio_range=(0.8, 1.6),pad_val=114.0),
如果你对上述 pipeline 不熟悉,你可能会以为 3 个 Pipeline 是独立的,可以随意组合使用,但是实际上不是因为 Mosaic 会将图片扩大 4 倍,然后必须要通过 RandomAffine 还原到原始尺寸,也就是说前两个 pipeline 是必须联合使用的,不能单独用。
果然随着模型的发布,issue 中出现了几个相似问题:为何我使用了 Mosaic pipeline 程序会报错?原因就是 Mosaic 和 RandomAffine 必须一起用,而大家不清楚。
当时没有思考过这可能会给用户带来困扰,现在看到本 repo 的 Sequential 的写法,想起来如果我们也将这两个 pipeline 采用 Sequential 包装到一起,就可以很好的解决上述问题。果然...
5.4 其他增强
(1) 自动 resume
if cfg.get("auto_resume", True):resume_from = find_latest_checkpoint(cfg.work_dir)
MMDetection 暂时还没有提供这个功能,resume 阶段需要用户手动指定权重名。如果用户想要这个功能,那么可以参考下
(2) wandb 可视化
log_config = dict(interval=50,hooks=[dict(type='TextLoggerHook'),dict(type='WandbLoggerHook',init_kwargs=dict(project='pre_release',name='${cfg_name}',config=dict(fold='${fold}',percent='${percent}',work_dirs='${work_dir}',total_step='${runner.max_iters}')),by_epoch=False)])
作者对 log 功能进行了增强,凡是能够使用 log 的地方都能使用 wandb。作者写的也是比较暴力,直接在每个 log 打印函数里面判断下是否使用 wandb。因为可视化的重要性,我们后续也会很好的支持各种可视化后端,让大家可以方便进行任何数据的可视化,包括但不限于图片、文本、视频等等
(3) n 折训练小工具
开源代码还提供了 n 折训练切分工具数据集和训练脚本,也是不错的,有需要的用户可以看看。
6 总结
本文从半监督算法出发,重点对半监督目标检测算法 Soft Teacher 进行了详细解读,不仅如此还重点对开源代码的亮点进行分析。但是本文细节非常多,如有我没有注意到的,请见谅!
最后老套路,请看下面:
MMDetection 官方地址:
https://github.com/open-mmlab/mmdetection
如果你觉得本文解读对你有一点点帮助,麻烦给 MMDetection 个 star,也算是给我周末辛苦解读的一点点鼓励吧!