
ResNet王者归来:ImageNet上刷新到80.7!
共 8169字,需浏览 17分钟
· 2021-11-27
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近期,timm库作者在ResNet strikes back: An improved training procedure in timm中提出了ResNet模型的训练优化策略,基于优化的训练策略,ResNet50在ImageNet数据集上top-1 accuracy达到80.4,大幅度超过之前的baseline:76.1(+4.3)。无独有偶,torchvision团队也在近日发布了他们在优化ResNet模型训练的探索成果(How to Train State-Of-The-Art Models Using TorchVision’s Latest Primitives):ResNet使用改进的训练策略可以在ImageNet数据集上top-1 accuracy达到80.7(+4.5),而且这些策略在应用在其它模型上也可以得到更优的结果,如ResNet101可以从77.4提升到81.7。
| Model | Accuracy@1 | Accuracy@5 |
|---|---|---|
| ResNet50 | 80.674 | 95.166 |
| ResNet101 | 81.728 | 95.670 |
| ResNet152 | 82.042 | 95.926 |
| ResNeXt50-32x4d | 81.116 | 95.478 |
这些优化的训练策略已经在torchvision中实现,具体训练代码见vision/references/classification。为了更加容易理解优化的训练策略,我们有必要先看一下baseline的训练策略。对于ResNet50,其训练的baseline设置如下:训练的batch size是32*8,epochs为90;优化器采用momentum=0.9的SGD,初始学习速率为0.1,然后每30个epoch学习速率衰减为原来的0.1;正则化只有L2,weight decay=1e-4;数据增强采用:随机缩放裁剪(RandomResizedCrop)+水平翻转(RandomHorizontalFlip),训练和测试时图像大小均为224。基于baseline策略,ResNet50在ImageNet数据集上top-1 accuracy大约是76.1。
# Optimizer & LR scheme
ngpus=8,
batch_size=32, # per GPU
epochs=90,
opt='sgd',
momentum=0.9,
lr=0.1,
lr_scheduler='steplr',
lr_step_size=30,
lr_gamma=0.1,
# Regularization
weight_decay=1e-4,
# Resizing
interpolation='bilinear',
val_resize_size=256,
val_crop_size=224,
train_crop_size=224,
对于改进的训练策略,其设置如下所示,相比baseline,其变动或增加了很多的内容:
# Optimizer & LR scheme
ngpus=8,
batch_size=128, # per GPU
epochs=600,
opt='sgd',
momentum=0.9,
lr=0.5,
lr_scheduler='cosineannealinglr',
lr_warmup_epochs=5,
lr_warmup_method='linear',
lr_warmup_decay=0.01,
# Regularization and Augmentation
weight_decay=2e-05,
norm_weight_decay=0.0,
label_smoothing=0.1,
mixup_alpha=0.2,
cutmix_alpha=1.0,
auto_augment='ta_wide',
random_erase=0.1,
# EMA configuration
model_ema=True,
model_ema_steps=32,
model_ema_decay=0.99998,
# Resizing
interpolation='bilinear',
val_resize_size=232,
val_crop_size=224,
train_crop_size=176,
上述设置对应的torchvision训练脚本的执行命令为:
torchrun --nproc_per_node=8 train.py --model resnet50 --batch-size 128 --lr 0.5 \
--lr-scheduler cosineannealinglr --lr-warmup-epochs 5 --lr-warmup-method linear \
--auto-augment ta_wide --epochs 600 --random-erase 0.1 --weight-decay 0.00002 \
--norm-weight-decay 0.0 --label-smoothing 0.1 --mixup-alpha 0.2 --cutmix-alpha 1.0 \
--train-crop-size 176 --model-ema --val-resize-size 232
对于改进的训练策略,torchvision官方也给出了每个具体的子策略加入后模型的性能增量,如下图所示,这里面共包含11个改进子策略,从柱状图上我们很清晰地可以看到它们对模型提升的贡献。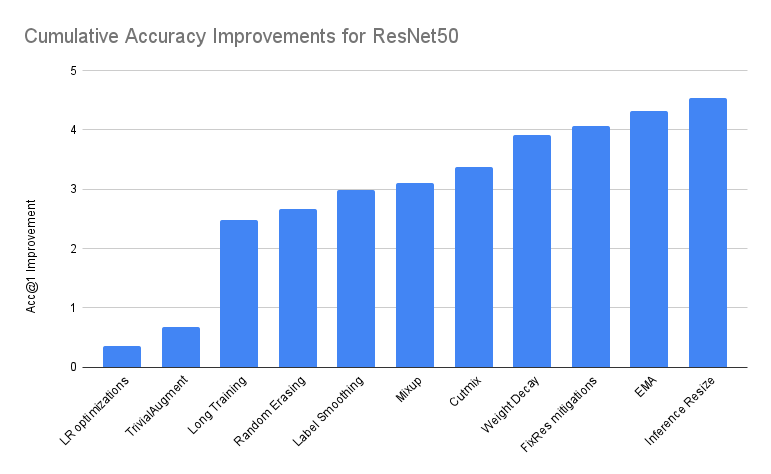 虽然可以看到每个子策略加入后模型性能均有提升,但要注意的是这个对比图是用最终得到优化策略从baseline开始来回溯每个子策略得到的一种理想结果。实际上,各个训练策略是往往互相影响的,我们也很难直接得到这么完美的递增结果,这里面包含了很多的调参过程。
虽然可以看到每个子策略加入后模型性能均有提升,但要注意的是这个对比图是用最终得到优化策略从baseline开始来回溯每个子策略得到的一种理想结果。实际上,各个训练策略是往往互相影响的,我们也很难直接得到这么完美的递增结果,这里面包含了很多的调参过程。
| **Accuracy@1 | Accuracy@5 | Incremental Diff | Absolute Diff | |
|---|---|---|---|---|
| ResNet50 Baseline | 76.130 | 92.862 | 0.000 | 0.000 |
| + LR optimizations | 76.494 | 93.198 | 0.364 | 0.364 |
| + TrivialAugment | 76.806 | 93.272 | 0.312 | 0.676 |
| + Long Training | 78.606 | 94.052 | 1.800 | 2.476 |
| + Random Erasing | 78.796 | 94.094 | 0.190 | 2.666 |
| + Label Smoothing | 79.114 | 94.374 | 0.318 | 2.984 |
| + Mixup | 79.232 | 94.536 | 0.118 | 3.102 |
| + Cutmix | 79.510 | 94.642 | 0.278 | 3.380 |
| + Weight Decay tuning | 80.036 | 94.746 | 0.526 | 3.906 |
| + FixRes mitigations | 80.196 | 94.672 | 0.160 | 4.066 |
| + EMA | 80.450 | 94.908 | 0.254 | 4.320 |
| + Inference Resize tuning * | 80.674 | 95.166 | 0.224 | 4.544 |
下面我们来逐一分析每个具体的子策略:
LR optimizations
首先是学习速率的优化,这里的优化包含3个方面:batch size,lr,lr scheduler。首先采用较大的batch size:128*8,根据线性规则学习速率也要增加,这里更改为0.5(理论上应该是0.4)。学习速率采用cosine scheduler(没有超参数),另外也采用了warmup,具体设置如下:
batch_size=128, # per GPU
lr=0.5,
lr_scheduler='cosineannealinglr',
lr_warmup_epochs=5,
lr_warmup_method='linear',
lr_warmup_decay=0.01,
这里也无需调参,直接应用这些优化,性能提升0.364。对于LR,优化器的选取也很重要,torchvision团队也尝试了一些更好的优化器如Adam和RMSProp,但是相比SGD并没有性能提升,不过timm采用的是LAMB优化器。
TrivialAugment
第二个是调整数据增强策略,baseline采用的数据增强过于简单,这里增加一种自动增强策略:TrivialAugment,相比谷歌的AutoAugment和RandAugment,TrivialAugment极其简单也无任何超参数,而且实验也证明TrivialAugment效果更好。使用TrivialAugment只需要简单设置:auto_augment='ta_wide',性能可以提升0.312。
Long Training
第三点简单粗暴,那就是训练更多的epochs:从90 epochs增加到600 epcohs。不过要注意的是,早期迭代时采用的是200 epochs,而后面做精细优化采用的是400 epochs,最后的训练策略才采用600 epochs。当采用更多的数据增强或者正则化策略后,采用更长的训练往往是非常必要的,因为它们引入了噪音,模型需要更多的迭代来学习。采用600 epochs,模型性能提升1.8,涨点明显。不过,如果直接对baseline策略增加训练时长并不会带来这么大的性能提升,正如前面所述,增加训练时长加上strong的数据增强等配合才能发挥更大作用。另外后面的介绍策略也需要更长的训练时长才能得到好的效果。
Random Erasing
Random Erasing是一种比较简单有效的数据增强:随机擦除图像的一部分矩形区域,它往往和自动数据增强方法配合使用。可以采用网格搜索来确定它应用的概率,发现采用较小的概率效果最好,这里设定为0.1,加上这一策略性能提升0.190。
Label Smoothing
Label smoothing是一种防止模型过拟合的有效方法,它通过软化ground truth来防止模型过度自信预测。Label smoothing的超参数是一个0~1的值,即smoothing幅度(0是不采用Label smoothing),这里实验发现采用0.05~0.15得到类似的结果,所以最终选择默认值0.1,目前nn.CrossEntropyLoss已经支持Label smoothing,加上这个策略性能提升0.318。
MixUp和CutMix
MixUp和CutMix是两种非常strong的数据增强:对两种图像进行混合,同时也对ground truth进行同样的操作(相当于对ground truth做了一定的软化)。两种方法很类似,区别在于混合图像的方式,MixUp是线性组合,而CutMix是区域组合。两者共同的超参数是alpha值,它决定了beta分布的形状,这个beta分布用来随机确定混合的ratio。这里通过简单的网格搜索来确定:mixup_alpha=0.2, cutmix_alpha=1.0。另外一点是,两者配合使用时可以等概率随机选择一种方式。单独采用MixUp可以提升0.118,配合CutMix可以额外提升0.278。
Weight Decay Tuning
另外常常采用的一种正则化方法是L2正则化,它可以有效地防止模型过拟合,默认情况下对所有模型参数应用,它的超参数weight decay决定了正则化强弱,这里采用了网格搜索确定:
weight_decay=2e-05,
norm_weight_decay=0.0,
一个另外的改进点是不对normalization layer的参数采用L2,所以这里norm_weight_decay=0.0。基于这些改进,模型性能提升0.526,看来weight decay对性能有着不小的影响。
FixRes
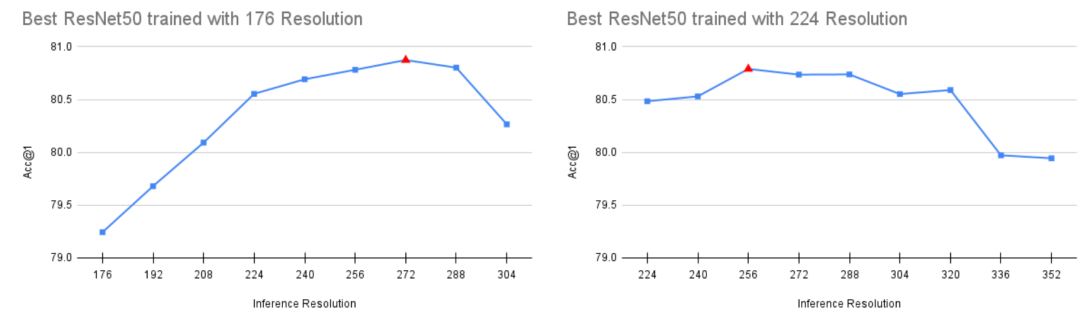
FixRes这篇论文指出由于训练采用较大范围的随机缩放导致训练和测试的不一定,训练时可以采用较小的图像大小,然后再采用较大的图像大小进行finetune可以提升模型性能。这是一种两阶段训练方法,但大家往往是直接降低训练图像大小,而不进行finetune。这里通过网格搜索发现在train_crop_size=176时,测试采用val_crop_size=224效果最好。这个优化可以带来0.160的性能提升,而且可以对训练提速10%。
下图给出了训练采用176和224时不同测试大小时模型性能,可以看到对于训练采用176,测试采用272效果最好,不过这里还是采用224和baseline保持一致。对于训练采用224,测试采用256效果最好。
EMA
EMA(exponential moving average)是一种非常有效的性能提升方法,它通过对训练过程中的模型参数做指数移动平均来得到更稳定的模型参数,EMA几乎不增加训练时间,也不会影响推理过程。这里设定的参数是:
model_ema=True,
model_ema_steps=32,
model_ema_decay=0.99998,
每32个step执行一次参数更新,decay设定为0.99998,注意这里的EMA对所有参数执行,报过buffers(比如BN的moving mean和moving std)。EMA能带来大约0.254的性能提升。
Inference Resize Tuning
另外一个优化的点是推理时resize参数,baseline方案在推理首先对图像进行256的resize,然后center crop 224大小的区域。这里采用网格搜索在[224, 256]区间内(步数为8)确定最优值,为了防止过拟合,验证集采用一半,最终确定的最优值为val_resize_size=232,和224比较接近,性能可以提升0.224。如下图所示,这个优化对其它模型也是有效的。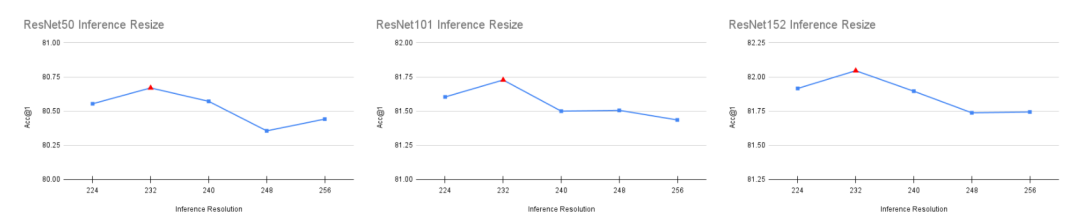
过拟合问题
这里所有的调参数都是在验证集上进行的,而且最终的性能也是报告验证集效果,那么这很可能造成过拟合问题。对于这个问题,torchvision在优化时只采用性能提升较大的优化策略,而且采用K-fold交叉验证来验证策略的有效性。另外,这个最终优化的策略也在其它模型上进行实验并得到好的结果,这也是一种泛化性的体现。对于过拟合,timm作者选择用另外的数据集ImageNet-V2来验证,同时验证模型的迁移能力。正如timm论文中所述,每个模型对应的最优训练策略可能和网络本身息息相关,所以这里得到的策略可能并不适合其它架构的模型。
使用预训练模型
torchvision团队设计了一种prototype机制来更容易地加载多个weights,除了weights本身url外,这里还包含labels,模型性能以及训练策略等等,另外也包含测试时采用的预处理方法:
from PIL import Image
from torchvision import prototype as P
img = Image.open("test/assets/encode_jpeg/grace_hopper_517x606.jpg")
# Initialize model
weights = P.models.ResNet50Weights.ImageNet1K_RefV2
model = P.models.resnet50(weights=weights)
model.eval()
# Initialize inference transforms
preprocess = weights.transforms()
# Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
prediction = model(batch).squeeze(0).softmax(0)
# Make predictions
label = prediction.argmax().item()
score = prediction[label].item()
# Use meta to get the labels
category_name = weights.meta['categories'][label]
print(f"{category_name}: {100 * score}%")
如果你不想使用prototype方式,可以直接用weighs对应的url简单加载模型:
from torchvision.models import resnet
# Overwrite the URL of the previous weights
resnet.model_urls["resnet50"] = "https://download.pytorch.org/models/resnet50-f46c3f97.pth"
# Initialize the model using the legacy API
model = resnet.resnet50(pretrained=True)
# TODO: Apply preprocessing + call the model
# ...
与timm的对比
这里我们难免要和timm所采用的训练策略做对比,timm共采用了三种不同的训练策略,其中A1和torchvision的训练策略最类似。可以看到两者的训练策略是非常接近的,比如训练epochs均为600,都采用了label smoothing,MixUp和CutMix。不过区别也是有的,比如A1采用的是LAMB优化器,因而学习速率采用了不一样的值,batch size也更大;还采用了Stochastic Depth和Repeated Augment等策略。可以看到timm的策略更多和deit的训练策略很像。另外timm独特的设计是采用BCE loss,这个可以带来一定的性能提升。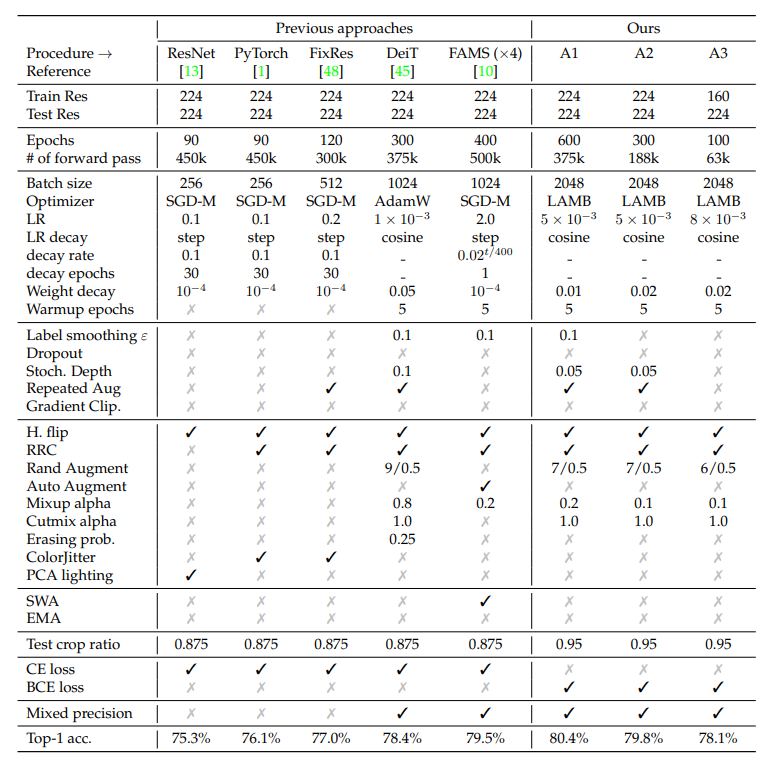
推荐阅读
PyTorch1.10发布:ZeroRedundancyOptimizer和Join
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
