
Python数据分析实战之技巧总结
Python之王
共 6260字,需浏览 13分钟
· 2021-11-20
数据分析实战中遇到的几个问题?
—— Pandas的DataFrame如何固定字段排序
—— 保证字段唯一性应如何处理
—— 透视表pivot_table函数转化长表注意问题
——Pandas的DataFrame数据框存在缺失值NaN运算如何应对
——如何对数据框进行任意行列增、删、改、查操作
—— 如何实现字段自定义打标签
Q1:Pandas的DataFrame如何固定字段排序
df_1 = pd.DataFrame({"itemtype": list(df.ITEMTYPE.unique())})
#固定字段顺序
list_custom = ["电耗量", "照明插座用电", "空调用电", "动力用电", "特殊用电"]
switch = {"电耗量": lambda x: list(x[x.ITEMTYPE == "电耗量"]["BRANCHID"]),
"照明插座用电": lambda x: list(x[x.ITEMTYPE == "照明插座用电"]["BRANCHID"]),
"空调用电": lambda x: list(x[x.ITEMTYPE == "空调用电"]["BRANCHID"]),
"动力用电": lambda x: list(x[x.ITEMTYPE == "动力用电"]["BRANCHID"]),
"特殊用电": lambda x: list(x[x.ITEMTYPE == "特殊用电"]["BRANCHID"])}
fxzl_list = []
fxmc_list = []
#列表生成式截留,其它方法参见推文Python实现switch/case用法案例
for i in [n for n in list_custom if n in list(df_1.itemtype)]:
try:
fxzl_list.append(switch[i](df))
fxmc_list.append(i)
except KeyError as e:
pass
display(fxmc_list)
display(fxzl_list)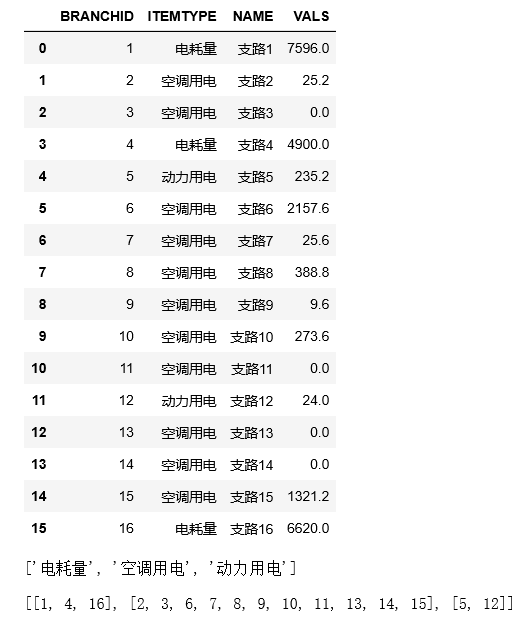
Q2:注意保证字段唯一性,如何处理
#以名称作为筛选字段时,可能出现重复的情况,实际中尽量以字段id唯一码与名称建立映射键值对,作图的时候尤其注意,避免不必要的错误,可以做以下处理:
1、处理数据以id为字段,最后统计用建立的key-value映射
X.index = X.index.map(_dict)
X1=X1.rename(columns=_dict)
2、加上区分字段
p1=list(X1.columns)
X2.columns=[p1[i]+"-"+str(i) for i in range(len(p1))]当然也可以对图例标签进行自定义设置区分,具体参见推文Python图表自定义设置
Q3:透视表pivot_table函数转化长表注意问题
import pandas as pd
import numpy as np
#构建重塑时间序列
index=pd.DataFrame({"时间":pd.date_range(start="2019/1/1",end="2019/12/31",freq="d")})
#重塑对象清单
df_list=list(df.分项名称.unique())
# 构建空表,存储处理的对象
df_empty=pd.DataFrame(columns=["时间","分项名称","用电量"])
for j in range(len(df_list2)):
df_1=df[df.分项名称==df_list2[j]]
# df_1=df_1.drop_duplicates(subset=["时间"])
DATA=pd.merge(index,df_1,how="left",on="时间")
DATA["分项名称"]=DATA["分项名称"].fillna(df_list[j])
df_empty=df_empty.append(DATA,ignore_index=True)#输出处理后的结果
#长表转为宽表,存在缺失值,不能保证时间序列的完整性
df2=df_empty.pivot_table(index=["时间"],columns="分项名称",values="用电量").round(decimals=2).reset_index()
#可以如下处理,保证时间序列完整,此处固定显示顺序,参见问题一
L_TYPE_day=list(df_empty.分项名称.unique())
df2=pd.DataFrame(index)
for i in range(len(L_TYPE_day)):
df_empty_day=df_empty[df_empty.分项名称==L_TYPE_day[i]]
df2[L_TYPE_day[i]]=list(df_empty_day["用电量"])
存在NaN值如何保证完整序列,数据结构如下


Q4、数据运算存在NaN如何应对
需求:pandas处理多列相减,实际某些元素本身为空值,如何碰到一个单元格元素为空就忽略了不计算,一般怎么解决!
#构造问题数据源
import pandas as pd
import numpy as np
from collections import Counter
a = Counter(A=1, B=2,C=1,D=2,E=1)
b=["1月","1月","2月","1月","1月","2月","1月"]
c1 =[70,80,40,50,60,90,70]
c2 =[30,40,20,15,30,30,40]
c3 =[20,20,10,20,10,20,10]
c4 =[10,10,5,10,np.nan,20,np.nan]
c5 =[10,5,5,np.nan,10,20,15]
df=pd.DataFrame({"建筑名称":list(a.elements()),"月份":b,"电耗量":c1,"照明用电":c2,"空调用电":c3,"动力用电":c4,"特殊用电":c5})
display(df)

#如果这样操作,发现所求列为空值,不是我想要的结果
df["照明用电"]=df["电耗量"]-df["空调用电"]-df["动力用电"]-df["特殊用电"]
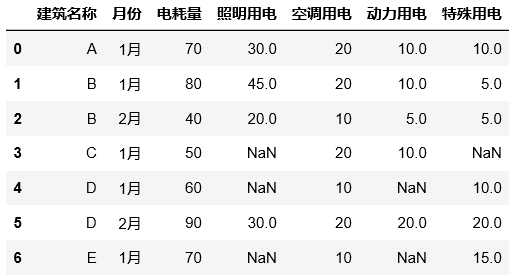
应该如何处理?
#将dataframe数据转化为二维数组,这时候我们可以利用强大的np模块进行数值计算啦!
arr = df[[i for i in list(df.columns[2:]) if i in(["动力用电", "特殊用电", "空调用电"]) ]].values
df["分项之和"] = np.nansum(arr, axis=1)
df["照明用电"] = df.apply(lambda x: x["电耗量"] - x["分项之和"], axis=1)
df.drop(columns=["分项之和"])
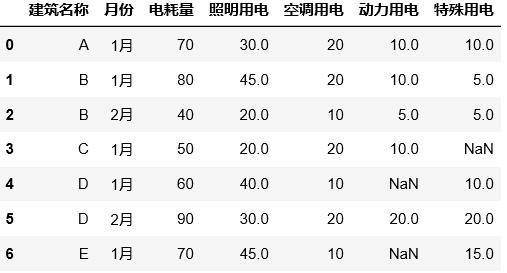
Q5、如何对数据框进行任意行列增、删、改、查操作
df1=df.copy() #复制一下
# 增操作
#普通索引,直接传入行或列
# 在第0行添加新行
df1.loc[0] = ["F","1月",100,50,30,10,10]
# 在第0列处添加新列
df1.insert(0, '建筑编码',[1,2,2,3,4,4,5])
df1.loc[:,"new"] = np.arange(7)
df1["new1"]=np.arange(7)
# 在末尾添加列
#或利用字典赋值操作
_dict={"A":1,"B":2,"C":3,"D":4,"E":5,"F":6}
df1["建筑编码1"]=df1["建筑名称"].map(_dict)
#建立字典from collections import defaultdict
#一个个添加,dict_1=defaultdict(lambda:"N/A"),key不存在时,返回一个默认值dict_1[7]="G"
#以列表形式存放元组中,用dict()转换
test_dict=([8,"H"],[9,"I"])
dict_1=dict(test_dict)
#键值对
dict_1=df1.drop_duplicates(['建筑编码']).set_index("建筑编码")["建筑名称"]
#字典的keys()、values()、items()方法
# keys()用来获取字典内的所有键
#values()用来获取字典内所有值
#items()用来得到一组组键值对
# df1.append(df2) # 往末尾添加dataframe
# pd.concat([df1, df2, df3]) # 往末尾添加多个dataframe
# pd.concat([df1, df2, df3], axis = 1) # 往末尾添加多个dataframe
# # 按照关键字合并
# result = pd.merge(df1, df2, on='cities')
# result2 = pd.merge(df1, df2, on='cities', how='outer')
df1

# 删
df3=df1.copy()
del df3['new1'] # 删除列
df3=df3.drop(['new', '建筑编码1'], axis = 1) # 删除多列
df3=df3.drop([8, 9, 10]) # 删除多列
df3=df3.dropna() # 删除带有Nan的行
df3=df3.dropna(axis = 1, how = 'all') # 删除全为Nan的列
df3=df3.dropna(axis = 1, how = 'any') # 删除带有Nan的列
df3=df3.dropna(axis = 0, how = 'all') # 删除全为Nan的行
df3=df3.dropna(axis = 0, how = 'any') # 删除带有Nan的行 默认选项为此
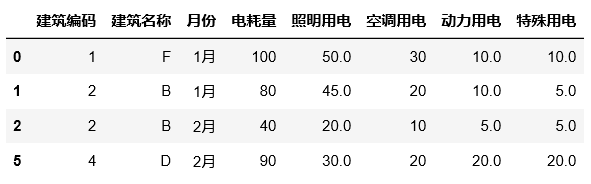
# 改
df4=df1.copy()
df4
#切片索引,传入行或列的位置区间
df4.iloc[:,5]= np.arange(7)
# # 元素赋值修改
df4.loc[0, '电耗量'] = 900
df4.iloc[0, 2] = "3月"
# df.set_index("建筑名称")
#改列明和索引名
df4 =df4.rename(columns={"照明用电":"照明插座用电"},index={1:8})
df4.fillna(value = 1) # 用1填充缺失值
# 列赋值
df4['year'] = 2020
val = pd.Series(["type7","type2","type2","type3","type4","type4","type5"])
df4['建筑类型'] =val #注意索引不能修改,否则修改行会缺失
# df4['建筑类型'] = ["type7","type2","type2","type3","type4","type4","type5"]

# 查
df5=df1.copy()
df5.index # RangeIndex
df5.columns # Index
df5.values # ndarray
# 元素查找
df5_1= df5.loc[0,'建筑名称'] # 数据是什么类型,xx就是什么类型
# df5_1 = df5.loc[[0],['建筑名称']] # DataFrame类型
# # 行查找
# df5_2 =df5.loc[0:2] # DataFrame类型012共3行
# df5_2=df5.iloc[0:2] # DataFrame类型 01共1行
df5_2= df5[0:3] # DataFrame类型 前三行
# 列查找
df5_3= df5.loc[:, '建筑编码'] # Series 列查找
df5_3 = df5.loc[:, ['建筑编码', '建筑名称']] # DataFrame类型 多列查找
df5_3 =df5.iloc[:, 0:2] # DataFrame类型 01列
df5_4= df5['建筑名称'] # Series类型
df5_4= df5.建筑名称 # Series类型 同上
df5_5 = df5[['建筑编码1', '建筑名称']] # DataFrame类型 按照新列序
df5_6= df5.filter(regex = '建筑编码1|建筑名称') # DataFrame类型 按照原列序
df5_7=df5[df5.电耗量 > 80]# 选择df5.电耗量中>80的行
# df5[df5.建筑名称.isin(['B', 'C'])] #DataFrame 条件查找
# df5[['建筑编码1', '建筑名称']][0:3] # DataFrame类型
# # 块查找
df5_8= df5.iloc[0:2, 0:2] # DataFrame类型
#条件查找
# # 条件查找
df5_9=df5.动力用电.notnull() # Series类型 true与false的一列
# df5_9 df5['动力用电'].notnull() # Series 同上
df5_10= df5[df5.动力用电.notnull()] # DataFrame类型 按照year非空选择之后的结果
df5_11= df5[df5.动力用电.notnull()].values # ndarray类型
df5_12= df5[df5.建筑名称== "D"][df5.月份 == '1月'] # DataFrame
#pandas库中使用.where()函数
# df5_13=df5.where((df5.月份=="1月")&(df5.动力用电>5)).dropna(axis=0)
# 或pandas库中的query()函数
df=df[df.建筑名称=="D"].query(("电耗量>60"))
#使用Numpy的内置where()函数,np.where(condition, value if condition is true, value if condition is false)
df['是否>30'] = np.where(df['照明用电']> 30, True, False)
# 再将样本筛选出
df= df[df['照明用电'] == True]Q6:如何对字段打标签
#一般情况下,根据值大小,将样本数据划分出不同的等级
方法一:使用一个名为np.select()的函数,给它提供两个参数:一个条件,另一个对应的等级列表。
conditions = [
(df['负载率'] <=0.3),
(df['负载率'] > 0.3) & (df['负载率'] <= 0.5),
(df['负载率'] > 0.5) & (df['负载率'] <= 0.75),
(df['负载率'] <1)]
values = ['(0-0.3]', '(0.3-0.5]', '(0.5-0.75]', '(0.75-1]']
df['标签'] = np.select(conditions, values)
#统计支路NAME的标签处于(0.75-1]区间情况
df[(df['标签'] == '(0.75-1]')['NAME'].value_counts(normalize=True)
方法二:
bins=[0,0.3,0.5,0.75,1]
df["标签"]=pd.cut(df["负载率"],bins)
方法三:自定义打标签,参加推文自定义分类打标签函数以上为本次分享全部内容,欢迎点赞、收藏、转发三连击!谢谢
Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!


评论