
单目标跟踪方法-SiamMask
共 3944字,需浏览 8分钟
· 2021-11-15
作者: 晟 沚
早期的跟踪算法都是坐标轴对齐的的矩形框。但随着跟踪精度的不断提升,数据集的难度在不断提升,在VOT2015时即提出使用旋转矩形框来作为标记。在VOT2016的时候提出自动的通过mask来生成旋转框的方法。更为本质的,我们会发现,这个旋转的矩形框实际上就是mask的一种近似。我们所要预测的实际上就是目标物体的mask。利用mask才能得到精度本身的上界。
设计理念
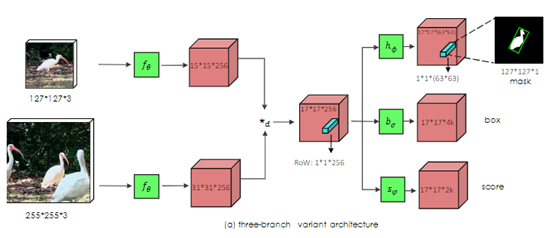
本文初始化简化为视频跟踪的box输入即可,同时得到box和mask两个输出。
主体网络思想和Siam系列较为类似,首先,通过初始帧框定需要跟踪的物体图像(记作template),用作后续帧(记作search,即搜索区域)的检索依据;
其次,将template和search同时输入Siameses Net,输出两个feature map,大小两个feature map做互相关(cross-correlated),得到RoW的feature map;
接着,从上面输出的feature map再输入一个简单的两层(1,1)卷积核的网络得到Two-branch或者Three-branch输出,各个branch主要是输出的通道数不一样,进而影响到任务的不一样。
最后,mask可以有两种方法生成,一个是base path生成方式,另一个是通过refine path生成。
网络结构
先讲一下Siamese网络
主要是计算两个输入的相似度,。左右两个神经网络分别将输入转换成一个"向量",在新的空间中,通过判断cosine距离就能得到相似度。
1. Mask分支(类别无关的半监督分割)
在siamese网络架构中额外增加一个Mask分支即可,但是相较于预测score和box,mask的预测会更为困难。我们这里使用的表述方法,是利用一个vector来编码一个RoW的mask,其实是在channel上面对patch的mask进行编码,使用一个logistic二分类监督。这使得每个prediction位置具有非常高的输出维度(63*63), 我们通过depthwise的卷积后级联1x1卷积来升维来实现高效运行。这样即构成了我们的主要模型框架。
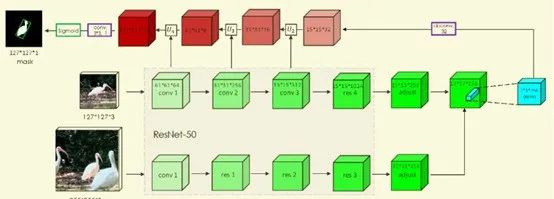
2. SiamMask还应用了DepthwiseCross-correlation的方式,解决SiamRPN非对称的问题,并使用ResNet-50作为网络主体加深网络深度,以获得更多层次的特征。
3. 生成mask:
1) 直接预测的Mask分支的精度并不太高。
得到一根柱子(RoW),维度是(1,1,63*63);
将这根RoW resize为(63, 63)的矩阵,同时对这个矩阵做sigmoid,讲清楚点就是63*63个二值classifier,用于判断这个矩阵的某一个值是否属于mask;mask矩阵,矩阵是经过sigmoid后的0-1的值,然后我们将这个mask 映射回原图。映射方式叫做仿射变换,实现的话关注下cv2.warpAffine函数;
通过预设的一个分割阈值,论文用0.5,但是代码用的0.35,去过滤5-3得到的sigmoid后的以及仿射变换后的mask,这样就得到需要的目标分割
2) Refine Module用来提升分割的精度,refine module采用top-down的结构,通过级联Refine的形式逐级将低语义信息高分辨率的feature map和上采样后的mask进行融合,最终得到同时拥有高语义信息和高分辨率的mask。
和256的RoW有关,只保留三分支中的score分支,将所有anchor的score做一系列操作,如乘上size 惩罚项(size_penalty),加上全图位置得分,从高到小的排列,选择最大值。
根据最大值的index,通过np.unravel_index转换得到feature map上的坐标,即可在(17,17, 256)feature map中得到一根RoW,传入refine path;传入refine path的是(1,1,256),即size为(1,1),channel为256的feature map
第一步就是要做deconv(反卷积),得到(15,15, 32)的feature map
和search经过res50保存下来的featuremap们进行相加耦合,template的feature map们需要经过两层模型的降维达到和RoW经过refine path的相同channel数和size,就可以相加
(127, 127, 4)的模型在经过一个(3, 3,4,1)卷积层得到(127,127,1)的mask
对于输出mask转换为box,有多重选择,我们使用了较为容易生成的最小外包矩形(MBR)
训练过程
1. 网络结构:Resnet-50,直到第4stage,正常模型会得到一个channel为1024的featuremap,但本网络得到的channel是256的feature map,原因是还进行了一层的下采样。
2. 使用了空洞卷积(dilated convolution),以增加感受野,增加感受野可以更好的得到目标mask。
3. 采用了ImageNet-1k的预训练模型,使用SGD优化器,前5个epoch做了warm up( 学习率10^-3 ),接着在15个epoch内逐渐降到 10^-4
4. 数据集不止采用了youtube-VOS(像素级),还有COCO以及ImageNet-VID。
离线训练
需要像素级别的标注来计算分割loss
训练图片和mask图片都是物体或mask 的size小于(127,127),物体和mask各自居于图片中心,且训练图片和mask图片size都为511的大小。注:511不关键,选其他值也一样,关键是要能够方便crop出训练图片和训练mask label。
预测过程
1. 梳理下推理流程:图片被resize到(256,256,3)的大小-->输入模型-->2-branch输出还是3-branch输出-->各自去生成mask。
2. 2-branch的时候,我们会选择最大的score分的那根RoW,这个时候要注意,一共有两根RoW,一个是前面层的(1,1,256),一个是(1,1,63*63),如果要经过refine生成mask,选前面那个Row(1,1,256),如果想base生成,则选择后面那个RoW。同理3-branch亦然,只不过score变成了cls分类最高值among all anchors。
3. 推理阶段,会根据上一帧的bbox位置来确定当前帧的search 区域,如果是3-branch,直接采用置信度最高的bbox,如果是2-branch,则需要用mask的RectBoundingBox获取。
生成template
template不是简单的框定ROI然后resize为(127,127,3)。他需要将框定的框做一个大约2倍放大(假设框定框的宽高分别为w、h,则需要放大到的size计算公式为:
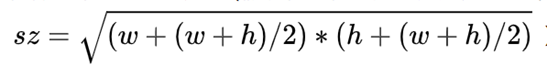
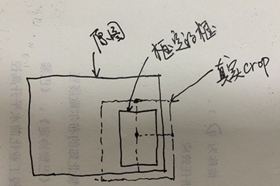
然后我们需要以物体为中心, sz 为宽高,截取一个正方体的物体出来,然后再resize为(127,127,3),这样得到template, 从下面图可以看出来,有些时候框不一定都在图里面,所以框到图外的部分要做padding,padding值为图片各自通道的均值(shape为(1,3))。
生成search
这里需要注意的一点是search同样不是直接把原图resize到(255,255,3)丢进模型里,他依靠template的物体在原图的位置,以物体为中心,约4倍物体size为宽高,进行截取,截取方式同template,只是需要把截取范围扩大1倍,同样图外的部分要做padding,padding值为图片各通道均值,resize为(255,255,3)就可以丢进模型啦。
ok,template和search在推理阶段的生成就讲完啦,我们稍微梳理下:search的截取范围约是template的2倍,template的截取范围又约是框定框的2倍。
之所以这么做的原因是很多时候帧与帧之间间隔时间比较短,理论上应该在上一帧的附近,这个时候我们也可以回想到我们物体训练的时候,search和template的选择也是尽可能在一定时域范围内去选取的。然后template的截取是物体实际大小的2倍,小七初步推测是为了尽可能完善框定框外的图片区域一起放进template去search做搜索。
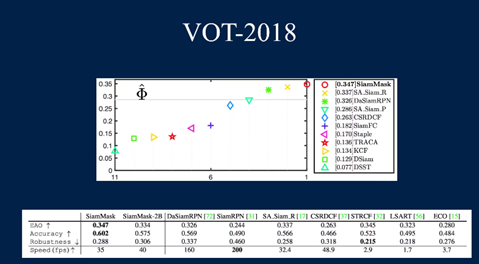
性能
视频跟踪领域(VOT),VOT2016和VOT2018数据集上的性能,本文的方法已经到达到SOTA的结果,同时保持了55fps的超实时的性能表现。
视频目标分割领域(VOS),本文取得了当前最快的速度。在DAVIS2017和Youtube-VOS上,本文和最近发表的较为快速的算法对比, 本文的算法可以取得可比较的分割精度,同时速度快了近一个数量级。对比经典的OSVOS,本文的算法快了近三个数量级,使得视频目标分割可以得到实际使用。
end
机器学习算法工程师
一个用心的公众号
进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助